
记一次Kubernetes排错实战


背景
故障定位
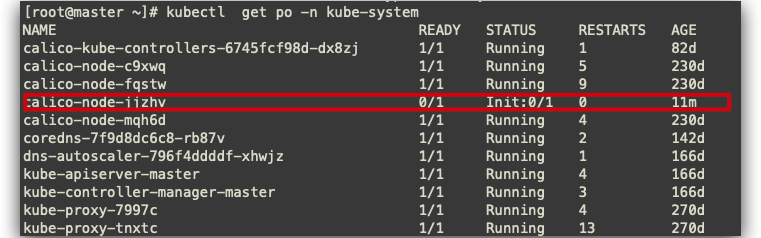


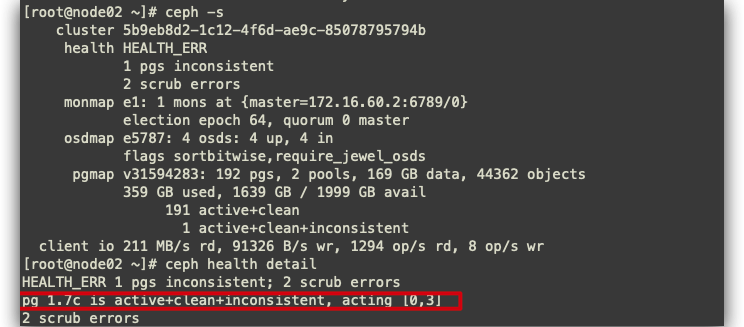
操作

ceph pg repair 1.7c
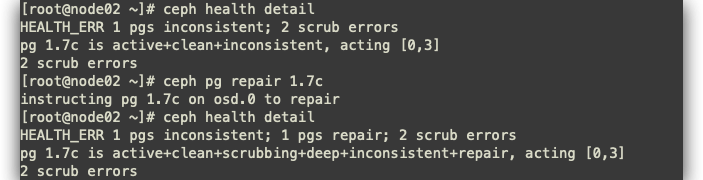


Kubelet宿主机的Linux内核过低 - Linux version 3.10.0-862.el7.x86_64
可以通过禁用kmem解决

kubectl cordon node02
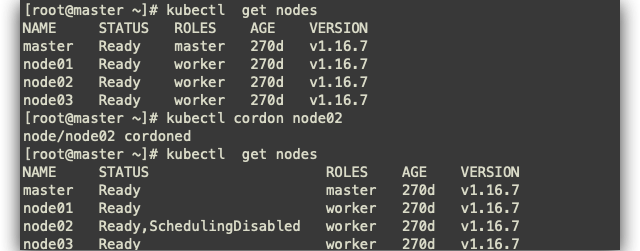
kubectl drain node02 --delete-local-data --ignore-daemonsets --force
--delete-local-data 删除本地数据,即使emptyDir也将删除;
--ignore-daemonsets 忽略DeamonSet,否则DeamonSet被删除后,仍会自动重建;
--force 不加force参数只会删除该Node节点上的ReplicationController,ReplicaSet,DaemonSet,StatefulSet or Job,加上后所有Pod都将删除。
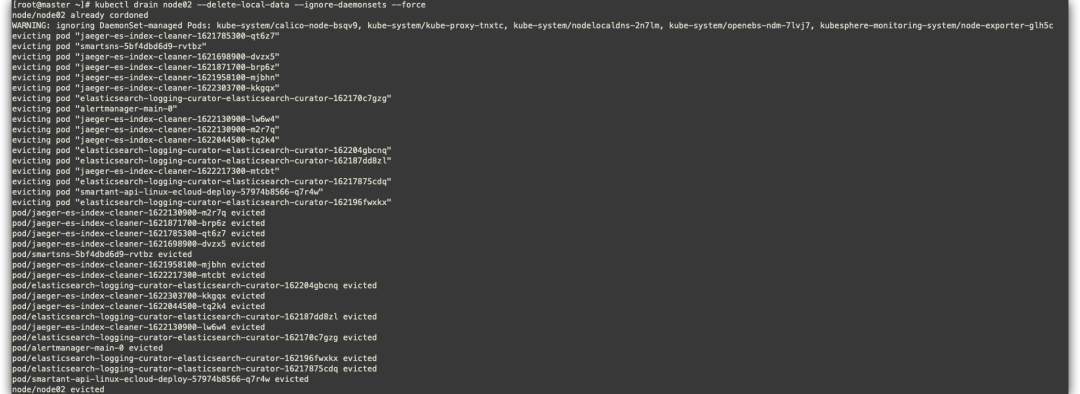

kubectl uncordon node02

反思
后期可以对部署Kubernetes集群内核进行升级。
集群内可能Pod的异常,由于底层存储或者其他原因导致,需要具体定位到问题进行针对性修复。
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多
评论