
大数据入门:Spark+Kudu的广告业务项目实战笔记(三)
点击上方蓝色字体,选择“设为星标”




这章的主要目标是对前两个需求的代码进行重构。
1.重构思路
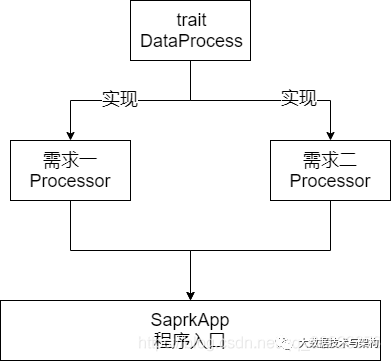
2.trait
Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。
与接口不同的是,它还可以定义属性和方法的实现。
一般情况下Scala的类只能够继承单一父类,但是如果是 Trait(特征) 的话就可以继承多个,从结果来看就是实现了多重继承。
package com.imooc.bigdata.cp08.`trait`import org.apache.spark.sql.SparkSession//顶层数据处理接口trait DataProcess {def process(spark:SparkSession)}
3.Processor
3.1 需求一:ETL的Processor
package com.imooc.bigdata.cp08.businessimport com.imooc.bigdata.cp08.`trait`.DataProcessimport com.imooc.bigdata.cp08.utils.{IPUtils, KuduUtils, SQLUtils, SchemaUtils}import org.apache.spark.sql.SparkSessionobject LogETLProcessor extends DataProcess{override def process(spark: SparkSession): Unit = {//使用DataSourceAPI直接加载json数据var jsonDF = spark.read.json("D:\\Hadoop基础与电商行为日志分析\\spark\\coding385\\sparksql-train\\data\\data-test.json")//jsonDF.printSchema()//jsonDF.show(false)//导入隐式转换import spark.implicits._//加载IP库,建议将RDD转成DFval ipRowRDD = spark.sparkContext.textFile("D:\\Hadoop基础与电商行为日志分析\\spark\\coding385\\sparksql-train\\data\\ip.txt")val ipRuleDF = ipRowRDD.map(x => {val splits = x.split("\\|")val startIP = splits(2).toLongval endIP = splits(3).toLongval province = splits(6)val city = splits(7)val isp = splits(9)(startIP, endIP, province, city, isp)}).toDF("start_ip", "end_ip", "province", "city", "isp")//ipRuleDF.show(false)//利用Spark SQL UDF转换json中的ipimport org.apache.spark.sql.functions._def getLongIp() = udf((ip:String)=>{IPUtils.ip2Long(ip)})//添加字段传入十进制IPjsonDF = jsonDF.withColumn("ip_long",getLongIp()($"ip"))//将日志每一行的ip对应省份、城市、运行商进行解析//两个DF进行join,条件是:json中的ip在规则ip中的范围内// val result = jsonDF.join(ipRuleDF, jsonDF("ip_long")// .between(ipRuleDF("start_ip"), ipRuleDF("end_ip")))// //.show(false)//用SQL的方式完成jsonDF.createOrReplaceTempView("logs")ipRuleDF.createOrReplaceTempView("ips")val sql = SQLUtils.SQLval result = spark.sql(sql)//.show(false)//Kuduval masterAddresses = "hadoop000"val tableName = "ods"val partitionId = "ip"val schema = SchemaUtils.ODSSchemaKuduUtils.sink(result,tableName,masterAddresses,schema,partitionId)spark.read.format("org.apache.kudu.spark.kudu").option("kudu.master",masterAddresses).option("kudu.table",tableName).load().show()}}
3.2 需求二:ProvinceCityStatProcessor
package com.imooc.bigdata.cp08.businessimport com.imooc.bigdata.cp08.`trait`.DataProcessimport com.imooc.bigdata.cp08.utils.{KuduUtils, SQLUtils, SchemaUtils}import org.apache.spark.sql.SparkSessionobject ProvinceCityStatProcessor extends DataProcess{override def process(spark: SparkSession): Unit = {//从Kudu的ods表中读取数据,然后按照省份和城市分组即可val sourceTableName = "ods"val masterAddress = "hadoop000"val odsDF = spark.read.format("org.apache.kudu.spark.kudu").option("kudu.table", sourceTableName).option("kudu.master", masterAddress).load()//odsDF.show(false)odsDF.createOrReplaceTempView("ods")val result = spark.sql(SQLUtils.PROVINCE_CITY_SQL)//result.show(false)//Kuduval sinkTableName = "province_city_stat"val partitionId = "provincename"val schema = SchemaUtils.ProvinceCitySchemaKuduUtils.sink(result,sinkTableName,masterAddress,schema,partitionId)spark.read.format("org.apache.kudu.spark.kudu").option("kudu.master",masterAddress).option("kudu.table",sinkTableName).load().show()}}
4.项目入口
package com.imooc.bigdata.cp08import com.imooc.bigdata.cp08.business.{LogETLProcessor, ProvinceCityStatProcessor}import org.apache.spark.sql.SparkSession//整个项目的入口object SparkApp {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[2]").appName("SparkApp").getOrCreate()//ETLLogETLProcessor.process(spark)//省份ProvinceCityStatProcessor.process(spark)spark.stop()}}


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
本文编辑:冷眼丶
微信公众号|import_bigdata
文章不错?点个【在看】吧! ?
评论