
Kafka是什么、主要应用在什么场景? 建议收藏!
点击上方[全栈开发者社区]→右上角[...]→[设为星标⭐]
1、kafka是什么?
Kafka是由LinkedIn开发的一个分布式基于发布/订阅的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。
2、产生背景
Kafka是一个消息系统,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。
活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。
运营数据指的3是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
3、基本架构图
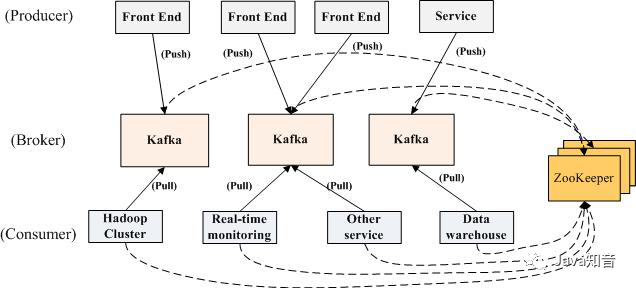
4、基本概念解释
1)Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。broker端不维护数据的消费状态,提升了性能。直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的创建对象和垃圾回收。
2)Producer
负责发布消息到Kafka broke
3)Consumer
消息消费者,向Kafka broker读取消息的客户端,consumer从broker拉取(pull)数据并进行处理。
4)Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
5)Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
6)Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
7)Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1)。
5、适用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Website activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Metrics
Kafka通常被用于可操作的监控数据。这包括从分布式应用程序来的聚合统计用来生产集中的运营数据提要。
4、Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统
END
作者:宝哥-NO1
blog.csdn.net/code52/article/details/50475511