
如何写出让人抓狂的代码?
《Java 面试指北》来啦!欢迎准备面试的小伙伴加入我的知识星球阅读!近期文章精选 :
前言
今天跟大家聊一个有趣的话题:如何写出让人抓狂的代码?
大家看到这个标题,第一印象觉得这篇文章可能是一篇水文。但我很负责的告诉你,它是一篇有很多干货的技术文。
曾几何时,你在阅读别人代码的时候,有没有抓狂,想生气,想发火的时候?
今天就跟大家一起聊聊,这20种我看了会抓狂的代码,看看你中招了没?
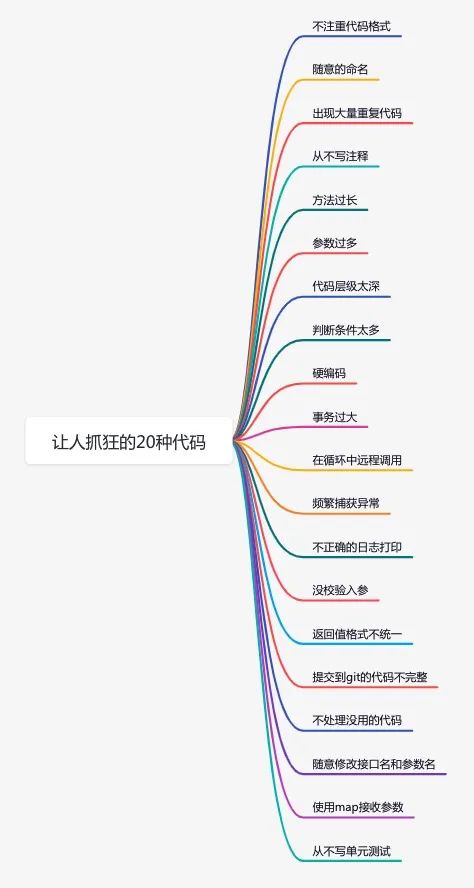
1.不注重代码格式
代码格式说起来很虚,下面我用几个案例演示一下,不注重代码格式的效果。作为这篇文章的开胃小菜吧。
1.1 空格
有时候必要的空格没有加,比如:
@Service
@Slf4j
public class TestService1{
public void test1(){
addLog("test1");
if (condition1){
if (condition2){
if (condition3){
log.info("info:{}",info);
}
}
}
}
}
你看了这段代码有何感想,有没有血压飙升的感觉?
代码好像揉到一起去了。
那么,如何把血压降下来呢?
答:加上空格即可。
正解:
@Service
@Slf4j
public class TestService1 {
public void test1() {
addLog("test1");
if (condition1) {
if (condition2) {
if (condition3) {
log.info("info:{}", info);
}
}
}
}
}
只加了一些空格,稍微调整了一下,这段代码的层次结构一下子变得非常清晰了。
好吧,我又冷静下来了。
1.2 换行
写代码时,如果有些必要的换行没有加,可能会出现这样的代码:
public void update(User user) {
if (null != user.getId()) {
User oldUser = userMapper.findUserById(user.getId());
if(null == oldUser)throw new RuntimeException("用户id不存在");
oldUser.setName(user.getName());oldUser.setAge(user.getAge());oldUser.setAddress(user.getAddress());
userMapper.updateUser(oldUser);
} else { userMapper.insertUser(user);
}
}
看了这段代码,是不是有点生无可恋的感觉?
简单的加点空格优化一下:
public void update(User user) {
if (null != user.getId()) {
User oldUser = userMapper.findUserById(user.getId());
if(null == oldUser) {
throw new RuntimeException("用户id不存在");
}
oldUser.setName(user.getName());
oldUser.setAge(user.getAge());
oldUser.setAddress(user.getAddress());
userMapper.updateUser(oldUser);
} else {
userMapper.insertUser(user);
}
}
代码逻辑一下子变得清晰了许多。
2.随意的命名
java中没有强制规定参数、方法、类或者包名该怎么起名。但如果我们没有养成良好的起名习惯,随意起名的话,可能会出现很多奇怪的代码。
2.1 有意义的参数名
有时候,我们写代码时为了省事(可以少敲几个字母),参数名起得越简单越好。假如同事A写的代码如下:
int a = 1;
int b = 2;
String c = "abc";
boolean b = false;
一段时间之后,同事A离职了,同事B接手了这段代码。
他此时一脸懵逼,a是什么意思,b又是什么意思,还有c...然后心里一万个草泥马。
给参数起一个有意义的名字,是非常重要的事情,避免给自己或者别人埋坑。
正解:
int supplierCount = 1;
int purchaserCount = 2;
String userName = "abc";
boolean hasSuccess = false;
2.2 见名知意
光起有意义的参数名还不够,我们不能就这点追求。我们起的参数名称最好能够见名知意,不然就会出现这样的情况:
String yongHuMing = "苏三";
String 用户Name = "苏三";
String su3 = "苏三";
String suThree = "苏三";
这几种参数名看起来是不是有点怪怪的?
为啥不定义成国际上通用的(地球人都能看懂)英文单词呢?
String userName = "苏三";
String susan = "苏三";
上面的这两个参数名,基本上大家都能看懂,减少了好多沟通成本。
所以建议在定义不管是参数名、方法名、类名时,优先使用国际上通用的英文单词,更简单直观,减少沟通成本。少用汉子、拼音,或者数字定义名称。
2.3 参数名风格一致
参数名其实有多种风格,列如:
//字母全小写
int suppliercount = 1;
//字母全大写
int SUPPLIERCOUNT = 1;
//小写字母 + 下划线
int supplier_count = 1;
//大写字母 + 下划线
int SUPPLIER_COUNT = 1;
//驼峰标识
int supplierCount = 1;
如果某个类中定义了多种风格的参数名称,看起来是不是有点杂乱无章?
所以建议类的成员变量、局部变量和方法参数使用supplierCount,这种驼峰风格,即:第一个字母小写,后面的每个单词首字母大写。例如:
int supplierCount = 1;
此外,为了好做区分,静态常量建议使用SUPPLIER_COUNT,即:大写字母 + 下划线分隔的参数名。例如:
private static final int SUPPLIER_COUNT = 1;
3.出现大量重复代码
ctrl + c 和 ctrl + v可能是程序员使用最多的快捷键了。
没错,我们是大自然的搬运工。哈哈哈。
在项目初期,我们使用这种工作模式,确实可以提高一些工作效率,可以少写(实际上是少敲)很多代码。
但它带来的问题是:会出现大量的代码重复。例如:
@Service
@Slf4j
public class TestService1 {
public void test1() {
addLog("test1");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
@Service
@Slf4j
public class TestService2 {
public void test2() {
addLog("test2");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
@Service
@Slf4j
public class TestService3 {
public void test3() {
addLog("test3");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
在TestService1、TestService2、TestService3类中,都有一个addLog方法用于添加日志。
本来该功能用得好好的,直到有一天,线上出现了一个事故:服务器磁盘满了。
原因是打印的日志太多,记了很多没必要的日志,比如:查询接口的所有返回值,大对象的具体打印等。
没办法,只能将addLog方法改成只记录debug日志。
于是乎,你需要全文搜索,addLog方法去修改,改成如下代码:
private void addLog(String info) {
if (log.isDebugEnabled()) {
log.debug("debug:{}", info);
}
}
这里是有三个类中需要修改这段代码,但如果实际工作中有三十个、三百个类需要修改,会让你非常痛苦。改错了,或者改漏了,都会埋下隐患,把自己坑了。
为何不把这种功能的代码提取出来,放到某个工具类中呢?
@Slf4j
public class LogUtil {
private LogUtil() {
throw new RuntimeException("初始化失败");
}
public static void addLog(String info) {
if (log.isDebugEnabled()) {
log.debug("debug:{}", info);
}
}
}
然后,在其他的地方,只需要调用。
@Service
@Slf4j
public class TestService1 {
public void test1() {
LogUtil.addLog("test1");
}
}
如果哪天addLog的逻辑又要改了,只需要修改LogUtil类的addLog方法即可。你可以自信满满的修改,不需要再小心翼翼了。
我们写的代码,绝大多数是可维护性的代码,而非一次性的。所以,建议在写代码的过程中,如果出现重复的代码,尽量提取成公共方法。千万别因为项目初期一时的爽快,而给项目埋下隐患,后面的维护成本可能会非常高。
4.从不写注释
有时候,在项目时间比较紧张时,很多人为了快速开发完功能,在写代码时,经常不喜欢写注释。
此外,还有些技术书中说过:好的代码,不用写注释,因为代码即注释。这也给那些不喜欢写代码注释的人,找了一个合理的理由。
但我个人觉得,在国内每个程序员的英文水平都不一样,思维方式和编码习惯也有很大区别。你要把前人某些复杂的代码逻辑真正搞懂,可能需要花费大量的时间。
我们看到spring的核心方法refresh,也是加了很多注释的:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
如果你写的代码完全不写注释,可能最近一个月、三个月、半年还记得其中的逻辑。但一年、两年,甚至更久的时间之后,你确定还能想起当初的逻辑,而不需要花费大量的时间去重新看自己的代码梳理逻辑?
说实话,不写注释,到了项目后期,不光是把自己坑了,还会坑队友。
为什么把这一条单独拿出来?
因为我遇到过,接过锅,被坑惨了。
5.方法过长
我们平时在写代码时,有时候思路来了,一气呵成,很快就把功能开发完了。但也可能会带来一个小问题,就是方法过长。
伪代码如下:
public void run() {
List<User> userList = userMapper.getAll();
//经过一系列的数据过滤
//此处省略了50行代码
List<User> updateList = //最终获取到user集合
if(CollectionUtils.isEmpty(updateList)) {
return;
}
for(User user: updateList) {
//经过一些复杂的过期时间计算
//此处省略30行代码
}
//分页更新用户的过期时间
//此处省略20行代码
//发mq消息通知用户
//此处省略30行代码
}
上面的run方法中包含了多种业务逻辑,虽说确实能够实现完整的业务功能,但却不能称之为好。
为什么呢?
答:该方法总长度超过150行,里面的代码逻辑很杂乱,包含了很多关联性不大的代码块。该方法的职责太不单一了,非常不利于代码复用和后期的维护。
那么,如何优化呢?
答:做方法拆分,即把一个大方法拆分成多个小方法。
例如:
public void run() {
List<User> userList = userMapper.getAll();
List<User> updateList = filterUser(userList);
if(CollectionUtils.isEmpty(updateList)) {
return;
}
for(User user: updateList) {
clacExpireDay(user);
}
updateUser(updateList);
sendMq(updateList);
}
private List<User> filterUser(List<User> userList) {
//经过一系列的数据过滤
//此处省略了50行代码
List<User> updateList = //最终获取到user集合
return updateList;
}
private void clacExpireDay(User user) {
//经过一些复杂的过期时间计算
//此处省略30行代码
}
private void updateUser(List<User> updateList) {
//分页更新用户的过期时间
//此处省略20行代码
}
private void sendMq(List<User> updateList) {
//发mq消息通知用户
//此处省略30行代码
}
这样简单的优化之后,run方法的代码逻辑一下子变得清晰了许多,光看它调用的子方法的名字,都能猜到这些字方法是干什么的。
每个子方法只专注于自己的事情,别的事情交给其他方法处理,职责更单一了。
此外,如果此时业务上有一个新功能,也需要给用户发消息,那么上面定义的sendMq方法就能被直接调用了。岂不是爽歪歪?
换句话说,把大方法按功能模块拆分成N个小方法,更有利于代码的复用。
顺便说一句,Hotspot对字节码超过8000字节的大方法有JIT编译限制,超过了限制不会被编译。
6.参数过多
我们平常在定义某个方法时,可能并没注意参数个数的问题(其实是我猜的)。我的建议是方法的参数不要超过5个。
先一起看看下面的例子:
public void fun(String a,
String b,
String c,
String d,
String e,
String f) {
...
}
public void client() {
fun("a","b","c","d",null,"f");
}
上面的fun方法中定义了6个参数,这样在调用该方面的所有地方都需要思考一下,这些参数该怎么传值,哪些参数可以为空,哪些参数不能为空。
方法的入参太多,也会导致该方法的职责不单一,方法存在风险的概率更大。
那么,如何优化参数过多问题呢?
答:可以将一部分参数迁移到新方法中。
这个例子中,可以把参数d,e,f迁移到otherFun方法。例如:
public Result fun(String a,
String b,
String c) {
...
return result;
}
public void otherFun(Result result,
String d,
String e,
String f) {
...
}
public void client() {
Result result = fun("a","b","c");
otherFun(result, "d", null, "f");
}
这样优化之后,每个方法的逻辑更单一一些,更有利于方法的复用。
如果fun中还需要返回参数a、b、c,给下个方法继续使用,那么代码可以改为:
public Result fun(String a,
String b,
String c) {
...
Result result = new Result();
result.setA(a);
result.setB(b);
result.setC(c);
return result;
}
在给Result对象赋值时,这里有个小技巧,可以使用lombok的@Builder注解,做成链式调用。例如:
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Data
public class Result {
private String a;
private String b;
private String c;
}
这样在调用的地方,可以这样赋值:
Result result = Result.builder()
.a("a").b("b").c("c")
.build();
非常直观明了。
此时,有人可能会说,ThreadPoolExecutor不也提供了7个参数的方法?
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
没错,不过它是构造方法,我们这里主要讨论的是普通方法。
7.代码层级太深
不知道你有没有见过类似这样的代码:
if (a == 1) {
if(b == 2) {
if(c == 3) {
if(d == 4) {
if(e == 5) {
...
}
...
}
...
}
...
}
...
}
这段代码中有很多层if判断,是不是看得人有点眼花缭乱?
有同感的同学,请举个手。
如果你没啥感觉,那么接着往下看:
for(int i=0; i<100;i++) {
for(int j=0; j<50;j++) {
for(int m=0; m<200;m++) {
for(int n=0; n<100;n++) {
for(int k=0; k<50; k++) {
...
}
}
}
}
}
看了这段代码,你心中可能会一紧。这么多循环,代码的性能真的好吗?
这两个例子中的代码都犯了同一个错误,即:代码层级太深。
代码层级太深导致的问题是代码变得非常不好维护,不容易理清逻辑,有时候代码的性能也可能因此变差。
那么关键问题来了,如何解决代码层级较深的问题呢?
对于if判断层级比较多的情况:
if(a!=1) {
...
return;
}
doConditionB();
private void doConditionB() {
if(b!=2) {
...
return;
}
doConditionC();
}
把不满足条件(a==1)的逻辑先执行,先返回。再把满足条件(a==1)的逻辑单独抽取到一个方法(doConditionB)中。该doConditionB中也会把不满足条件(b==2)的逻辑先执行,先返回。再把满足条件(b==2)的逻辑单独抽取到一个方法(doConditionC)中。后面逻辑以此类推。
这种做法是面向防御式编程的一种,即先把不满足条件的代码先执行,然后才执行满足条件的代码。此外别忘了,把满足条件的代码抽取到一个新的方法中喔。
对于for循环层级太深的优化方案,一般推荐使用map。
例如:
for(Order order:orderList) {
for(OrderDetail detail: detailList) {
if(order.getId().equals(detail.getOrderId())) {
doSamething();
}
}
}
使用map优化之后:
Map<Long, List<OrderDetail>> detailMap = detailList.stream().collect(Collectors.groupingBy(OrderDetail::getOrderId));
for(Order order:orderList) {
List<OrderDetail> detailList = detailMap.get(order.getId());
if(CollectionUtils.isNotEmpty) {
doSamething();
}
}
这个例子中使用map,少了一层循环,代码效率提升一些。但不是所有的for循环都能用map替代,要根据自己实际情况选择。
代码层级太深,还有其他的场景,比如:方法中return的次数太多,也会降低代码的可读性。
这种情况,其实也可能通过面向防御式编程进行代码优化。
8.判断条件太多
我们在写代码的时候,判断条件是必不可少的。不同的判断条件,走的代码逻辑通常会不一样。
废话不多说,先看看下面的代码。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@Override
public void pay() {
System.out.println("===发起支付宝支付===");
}
}
@Service
public class WeixinPay implements IPay {
@Override
public void pay() {
System.out.println("===发起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@Override
public void pay() {
System.out.println("===发起京东支付===");
}
}
@Service
public class PayService {
@Autowired
private AliaPay aliaPay;
@Autowired
private WeixinPay weixinPay;
@Autowired
private JingDongPay jingDongPay;
public void toPay(String code) {
if ("alia".equals(code)) {
aliaPay.pay();
} elseif ("weixin".equals(code)) {
weixinPay.pay();
} elseif ("jingdong".equals(code)) {
jingDongPay.pay();
} else {
System.out.println("找不到支付方式");
}
}
}
PayService类的toPay方法主要是为了发起支付,根据不同的code,决定调用用不同的支付类(比如:aliaPay)的pay方法进行支付。
这段代码有什么问题呢?也许有些人就是这么干的。
试想一下,如果支付方式越来越多,比如:又加了百度支付、美团支付、银联支付等等,就需要改toPay方法的代码,增加新的else...if判断,判断多了就会导致逻辑越来越多?
很明显,这里违法了设计模式六大原则的:开闭原则 和 单一职责原则。
开闭原则:对扩展开放,对修改关闭。就是说增加新功能要尽量少改动已有代码。
单一职责原则:顾名思义,要求逻辑尽量单一,不要太复杂,便于复用。
那么,如何优化if...else判断呢?
答:使用 策略模式+工厂模式。
策略模式定义了一组算法,把它们一个个封装起来, 并且使它们可相互替换。 工厂模式用于封装和管理对象的创建,是一种创建型模式。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("aliaPay", this);
}
@Override
public void pay() {
System.out.println("===发起支付宝支付===");
}
}
@Service
public class WeixinPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("weixinPay", this);
}
@Override
public void pay() {
System.out.println("===发起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("jingDongPay", this);
}
@Override
public void pay() {
System.out.println("===发起京东支付===");
}
}
public class PayStrategyFactory {
private static Map<String, IPay> PAY_REGISTERS = new HashMap<>();
public static void register(String code, IPay iPay) {
if (null != code && !"".equals(code)) {
PAY_REGISTERS.put(code, iPay);
}
}
public static IPay get(String code) {
return PAY_REGISTERS.get(code);
}
}
@Service
public class PayService3 {
public void toPay(String code) {
PayStrategyFactory.get(code).pay();
}
}
这段代码的关键是PayStrategyFactory类,它是一个策略工厂,里面定义了一个全局的map,在所有IPay的实现类中注册当前实例到map中,然后在调用的地方通过PayStrategyFactory类根据code从map获取支付类实例即可。
如果加了一个新的支付方式,只需新加一个类实现IPay接口,定义init方法,并且重写pay方法即可,其他代码基本上可以不用动。
当然,消除又臭又长的if...else判断,还有很多方法,比如:使用注解、动态拼接类名称、模板方法、枚举等等。由于篇幅有限,在这里我就不过多介绍了,更详细的内容可以看看我的另一篇文章《消除if...else是9条锦囊妙计》
9.硬编码
不知道你有没有遇到过这类需求:
限制批量订单上传接口,一次性只能上传200条数据。 在job中分页查询用户,一页查询100个用户,然后计算用户的等级。
上面例子中的200条数据和100个用户,很容易硬编码,即在代码中把参数写死了。
我们以上传200条数据为例:
private static final int MAX_LIMIT = 200;
public void upload(List<Order> orderList) {
if(CollectionUtils.isEmpty(orderList)) {
throw new BusinessException("订单不能为空");
}
if(orderList.size() > MAX_LIMIT) {
throw new BusinessException("超过单次请求的数量限制");
}
}
其中MAX_LIMIT被定义成了静态常量。
上线之后,你发现上传历史数据时速度太慢了,需要把限制调大一点。
我擦。。。这种小小的参数改动,还需要改源代码,重新编译,重新打包,重新部署。。。
但如果你当初把这些公共参数,设置成可配置的,例如:
@Value("${com.susan.maxLimit:200}")
private int maxLimit = 200;
public void upload(List<Order> orderList) {
if(CollectionUtils.isEmpty(orderList)) {
throw new BusinessException("订单不能为空");
}
if(orderList.size() > maxLimit) {
throw new BusinessException("超过单次请求的数量限制");
}
}
这样只需在配置中心(比如:apollo、nocas等)中修改一下配置即可,不用修改源代码,不用重新编译,不用重新打包,不用重新部署。
一个字:爽。
我们在前期开发的时候,宁可多花一分钟思考一下,这个参数后面是否会被修改,是否可以定义成可配置的参数。也比后期修改代码,重新编译,重新打包,重新上线花的时间少得多。
10.事务过大
我们平时在使用spring框架开发项目时,喜欢用@Transactional注解声明事务。例如:
@Transactional(rollbackFor = Throwable.class)
public void updateUser(User user) {
System.out.println("update");
}
只需在需要使用事务的方法上,使用@Transactional注解声明一下,该方法通过AOP就自动拥有了事务的功能。
没错,这种做法给我们带来了极大的便利,开发效率更高了。
但也给我们带来了很多隐患,比如大事务的问题。我们一起看看下面的这段代码:
@Transactional(rollbackFor = Throwable.class)
public void updateUser(User user) {
User oldUser = userMapper.getUserById(user.getId());
if(null != oldUser) {
userMapper.update(user);
} else {
userMapper.insert(user);
}
sendMq(user);
}
这段代码中getUserById方法和sendMq方法,在这个案例中无需使用事务,只有update或insert方法才需要事务。
所以上面这段代码的事务太大了,是整个方法级别的事务。假如sendMq方法是一个非常耗时的操作,则可能会导致整个updateUser方法的事务超时,从而出现大事务问题。
那么,如何解决这个问题呢?
答:可以使用TransactionTemplate的编程式事务优化代码。
@Autowired
private TransactionTemplate transactionTemplate;
....
public void updateUser(User user) {
User oldUser = userMapper.getUserById(user.getId());
transactionTemplate.execute((status) => {
if(null != oldUser) {
userMapper.update(user);
} else {
userMapper.insert(user);
}
return Boolean.TRUE;
})
sendMq(user);
}
只有在execute方法中的代码块才真正需要事务,其余的方法,可以非事务执行,这样就能缩小事务的范围,避免大事务。
当然使用TransactionTemplate这种编程式事务,缩小事务范围,来解决大事务问题,只是其中一种手段。
如果你想对大事务问题,有更深入的了解,可以看看我的另一篇文章《让人头痛的大事务问题到底要如何解决?》
11.在循环中远程调用
有时候,我们需要在某个接口中,远程调用第三方的某个接口。
比如:在注册企业时,需要调用天眼查接口,查一下该企业的名称和统一社会信用代码是否正确。
这时候在企业注册接口中,不得不先调用天眼查接口校验数据。如果校验失败,则直接返回。如果校验成功,才允许注册。
如果只是一个企业还好,但如果某个请求有10个企业需要注册,是不是要在企业注册接口中,循环调用10次天眼查接口才能判断所有企业是否正常呢?
public void register(List<Corp> corpList) {
for(Corp corp: corpList) {
CorpInfo info = tianyanchaService.query(corp);
if(null == info) {
throw new RuntimeException("企业名称或统一社会信用代码不正确");
}
}
doRegister(corpList);
}
这样做可以,但会导致整个企业注册接口性能很差,极容易出现接口超时问题。
那么,如何解决这类在循环中调用远程接口的问题呢?
11.1 批量操作
远程接口支持批量操作,比如天眼查支持一次性查询多个企业的数据,这样就无需在循环中查询该接口了。
但实际场景中,有些第三方不愿意提供第三方接口。
11.2 并发操作
java8以后通过CompleteFuture类,实现多个线程查天眼查接口,并且把查询结果统一汇总到一起。
具体用法我就不展开了,有兴趣的朋友可以看看我的另一篇文章《聊聊接口性能优化的11个小技巧》
12.频繁捕获异常
通常情况下,为了在程序中抛出异常时,任然能够继续运行,不至于中断整个程序,我们可以选择手动捕获异常。例如:
public void run() {
try {
doSameThing();
} catch (Exception e) {
//ignore
}
doOtherThing();
}
这段代码可以手动捕获异常,保证即使doSameThing方法出现了异常,run方法也能继续执行完。
但有些场景下,手动捕获异常被滥用了。
12.1 滥用场景1
不知道你在打印异常日志时,有没有写过类似这样的代码:
public void run() throws Exception {
try {
doSameThing();
} catch (Exception e) {
log.error(e.getMessage(), e);
throw e;
}
doOtherThing();
}
通过try/catch关键字,手动捕获异常的目的,仅仅是为了记录错误日志,在接下来的代码中,还是会把该异常抛出。
在每个抛出异常的地方,都捕获一下异常,打印日志。
12.2 滥用场景2
在写controller层接口方法时,为了保证接口有统一的返回值,你有没有写过类似这样的代码:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
try {
List<User> userList = userService.query(ids);
return Result.ok(userList);
} catch (Exception e) {
log.error(e.getMessage(), e);
return Result.fature(500, "服务器内部错误");
}
}
在每个controller层的接口方法中,都加上了上面这种捕获异常的逻辑。
上述两种场景中,频繁的捕获异常,会让代码性能降低,因为捕获异常是会消耗性能的。
此外,这么多重复的捕获异常代码,看得让人头疼。
其实,我们还有更好的选择。在网关层(比如:zuul或gateway),有个统一的异常处理代码,既可以打印异常日志,也能统一封装接口返回值,这样可以减少很多异常被滥用的情况。
13.不正确的日志打印
在我们写代码的时候,打印日志是必不可少的工作之一。
因为日志可以帮我们快速定位问题,判断代码当时真正的执行逻辑。
但打印日志的时候也需要注意,不是说任何时候都要打印日志,比如:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
log.info("request params:{}", ids);
List<User> userList = userService.query(ids);
log.info("response:{}", userList);
return userList;
}
对于有些查询接口,在日志中打印出了请求参数和接口返回值。
咋一看没啥问题。
但如果ids中传入值非常多,比如有1000个。而该接口被调用的频次又很高,一下子就会打印大量的日志,用不了多久就可能把磁盘空间打满。
如果真的想打印这些日志该怎么办?
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
if (log.isDebugEnabled()) {
log.debug("request params:{}", ids);
}
List<User> userList = userService.query(ids);
if (log.isDebugEnabled()) {
log.debug("response:{}", userList);
}
return userList;
}
使用isDebugEnabled判断一下,如果当前的日志级别是debug才打印日志。生产环境默认日志级别是info,在有些紧急情况下,把某个接口或者方法的日志级别改成debug,打印完我们需要的日志后,又调整回去。
方便我们定位问题,又不会产生大量的垃圾日志,一举两得。
14.没校验入参
参数校验是接口必不可少的功能之一,一般情况下,提供给第三方调用的接口,需要做严格的参数校验。
以前我们是这样校验参数的:
@PostMapping("/add")
public void add(@RequestBody User user) {
if(StringUtils.isEmpty(user.getName())) {
throw new RuntimeException("name不能为空");
}
if(null != user.getAge()) {
throw new RuntimeException("age不能为空");
}
if(StringUtils.isEmpty(user.getAddress())) {
throw new RuntimeException("address不能为空");
}
userService.add(user);
}
需要手动写校验的代码,如果作为入参的实体中字段非常多,光是写校验的代码,都需要花费大量的时间。而且这些校验代码,很多都是重复的,会让人觉得恶心。
好消息是使用了hibernate的参数校验框架validate之后,参数校验一下子变得简单多了。
我们只需要校验的实体类User中使用validation框架的相关注解,比如:@NotEmpty、@NotNull等,定义需要校验的字段即可。
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
}
然后在controller类上加上@Validated注解,在接口方法上加上@Valid注解。
@Slf4j
@Validated
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/add")
public void add(@RequestBody @Valid User user) {
userService.add(user);
}
}
这样就能自动实现参数校验的功能。
然而,现在需求改了,需要在User类上增加了一个参数Role,它也是必填字段,并且它的roleName和tag字段都不能为空。
但如果我们在校验参数时,不小心把代码写成这样:
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
@NotNull
private Role role;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Role {
@NotEmpty
private String roleName;
@NotEmpty
private String tag;
}
结果就悲剧了。
你心里可能还乐呵呵的认为写的代码不错,但实际情况是,roleName和tag字段根本不会被校验到。
如果传入参数:
{
"name": "tom",
"age":1,
"address":"123",
"role":{}
}
即使role字段传入的是空对象,但该接口也会返回成功。
那么如何解决这个问题呢?
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
@NotNull
@Valid
private Role role;
}
需要在Role字段上也加上@Valid注解。
温馨的提醒一声,使用validate框架校验参数一定要自测,因为很容易踩坑。
15.返回值格式不统一
我之前对接某个第三方时,他们有部分接口的返回值结构是这样的:
{
"ret":0,
"message":null,
"data":[]
}
另一部分接口的返回值结构是这样的:
{
"code":0,
"msg":null,
"success":true,
"result":[]
}
整得我有点懵逼。
为啥没有一个统一的返回值?
我需要给他们的接口写两套返回值解析的代码,后面其他人看到了这些代码,可能也会心生疑问,为什么有两种不同的返回值解析?
唯一的解释是一些接口是新项目的,另外一些接口是老项目的。
但如果不管是新项目,还是老项目,如果都有一个统一的对外网关服务,由这个服务进行鉴权和统一封装返回值。
{
"code":0,
"message":null,
"data":[]
}
就不会有返回值结构不一致的问题。
温馨的提醒一下,业务服务不要捕获异常,直接把异常抛给网关服务,由它来统一全局捕获异常,这样就能统一异常的返回值结构。
16.提交到git的代码不完整
我们写完代码之后,把代码提交到gitlab上,也有一些讲究。
最最忌讳的是代码还没有写完,因为赶时间(着急下班),就用git把代码提交了。例如:
public void test() {
String userName="苏三";
String password=
}
这段代码中的password变量都没有定义好,项目一运行起来必定报错。
这种错误的代码提交方式,一般是新手会犯。但还有另一种情况,就是在多个分支merge代码的时候,有时候会出问题,merge之后的代码不能正常运行,就被提交了。
好的习惯是:用git提交代码之前,一定要在本地运行一下,确保项目能正常启动才能提交。
宁可不提交代码到远程仓库,切勿因为一时赶时间,提交了不完整的代码,导致团队的队友们项目都启动不了。
17.不处理没用的代码
有些时候,我们为了偷懒,对有些没用的代码不做任何处理。
比如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void add(User user) {
System.out.println("add");
}
public void update(User user) {
System.out.println("update");
}
public void query(User user) {
System.out.println("query");
}
}
本来UserService类中的add、update、query方法都在用的。后来,某些功能砍掉了,现在只有add方法真正在用。
某一天,项目组来了一个新人,接到需求需要在user表加一个字段,这时候他是不是要把add、update、query方法都仔细看一遍,评估一下影响范围?
后来发现只有add方法需要改,他心想前面的开发者为什么不把没用的代码删掉,或者标记出来呢?
在java中可以使用@Deprecated表示这个类或者方法没在使用了,例如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void add(User user) {
System.out.println("add");
}
@Deprecated
public void update(User user) {
System.out.println("update");
}
@Deprecated
public void query(User user) {
System.out.println("query");
}
}
我们在阅读代码时,可以先忽略标记了@Deprecated注解的方法。这样一个看似简单的举手之劳,可以给自己,或者接手该代码的人,节省很多重复查代码的时间。
建议我们把没用的代码优先删除掉,因为gitlab中是有历史记录的,可以找回。但如果有些为了兼容调用方老版本的代码,不能删除的情况,建议使用
@Deprecated注解相关类或者接口。
18.随意修改接口名和参数名
不知道你有没有遇到过这种场景:你写了一个接口,本来以为没人使用,后来觉得接口名或参数名不对,偷偷把它们改了。比如:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
return userService.query(ids);
}
接口名改了:
@PostMapping("/queryUser")
public List<User> queryUser(@RequestBody List<Long> ids) {
return userService.query(ids);
}
结果导致其他人的功能报错,原来他已经在调用该接口了。
大意了。。。
所以在修改接口名、参数名、修改参数类型、修改参数个数时,一定要先询问一下相关同事,有没有使用该接口,免得以后出现不必要的麻烦。
对于已经在线上使用的接口,尽量不要修改接口名、参数名、修改参数类型、修改参数个数,还有请求方式,比如:get改成post等。宁可新加一个接口,也尽量不要影响线上功能。
19.使用map接收参数
我之前见过有些小伙伴,在代码中使用map接收参数的。例如:
@PostMapping("/map")
public void map(@RequestBody Map<String, Object> mapParam){
System.out.println(mapParam);
}
在map方法中使用mapParam对象接收参数,这种做法确实很方便,可以接收多种json格式的数据。
例如:
{
"id":123,
"name":"苏三",
"age":18,
"address":"成都"
}
或者:
{
"id":123,
"name":"苏三",
"age":18,
"address":"成都",
"role": {
"roleName":"角色",
"tag":"t1"
}
}
这段代码可以毫不费劲的接收这两种格式的参数,so cool。
但同时也带来了一个问题,那就是:参数的数据结构你没法控制,有可能你知道调用者传的json数据格式是第一种,还是第二种。但如果你没有写好注释,其他的同事看到这段代码,可能会一脸懵逼,map接收的参数到底是什么东东?
项目后期,这样的代码变得非常不好维护。有些同学接手前人的代码,时不时吐槽一下,是有原因的。
那么,如果优化这种代码呢?
我们应该使用有明确含义的对象去接收参数,例如:
@PostMapping("/add")
public void add(@RequestBody @Valid User user){
System.out.println(user);
}
其中的User对象是我们已经定义好的对象,就不会存在什么歧义了。
20.从不写单元测试
因为项目时间实在太紧了,系统功能都开发不完,更何况是单元测试呢?
大部分人不写单元测试的原因,可能也是这个吧。
但我想告诉你的是,不写单元测试并不是个好习惯。
我见过有些编程高手是测试驱动开发,他们会先把单元测试写好,再写具体的业务逻辑。
那么,我们为什么要写单元测试呢?
我们写的代码大多数是可维护的代码,很有可能在未来的某一天需要被重构。试想一下,如果有些业务逻辑非常复杂,你敢轻易重构不?如果有单元测试就不一样了,每次重构完,跑一次单元测试,就知道新写的代码有没有问题。
我们新写的对外接口,测试同学不可能完全知道逻辑,只有开发自己最清楚。不像页面功能,可以在页面上操作。他们在测试接口时,很有可能覆盖不到位,很多bug测不出来。
建议由于项目时间非常紧张,在开发时确实没有写单元测试,但在项目后期的空闲时间也建议补上。
本文结合自己的实际工作经验,用调侃的方式,介绍了在编写代码的过程中,不太好的地方和一些优化技巧,给用需要的朋友们一个参考
·········· END ··············
面试指北/免费提问/简历修改/求职指南/学习打卡,欢迎加入JavaGuide 知识星球。这是星球的详细介绍以及加入方法:JavaGuide 知识星球详细介绍 (一定一定一定确定自己真的需要再加入,一定一定要看完详细介绍之后再加我)。
如果本文对你有帮助的话,欢迎点赞&在看&分享,这对我继续分享&创作优质文章非常重要。感谢🙏🏻
