
梳理消息队列 MQ/JMS/Kafka

- 前言 -
- 消息队列介绍 -
快递小哥有时间送; 我们有时间取; 快递小哥和我们约定一个时间地点。
1.1什么是消息队列
我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。
1.2消息队列(Message queue)有什么用?
填写我们的注册信息; 提交我们的注册信息; 我们的邮箱收到注册信息; 我们的短信收到注册信息。

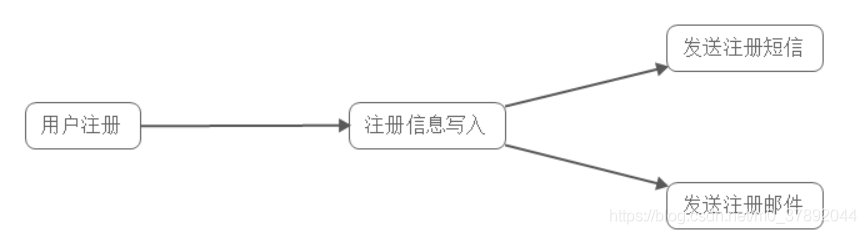
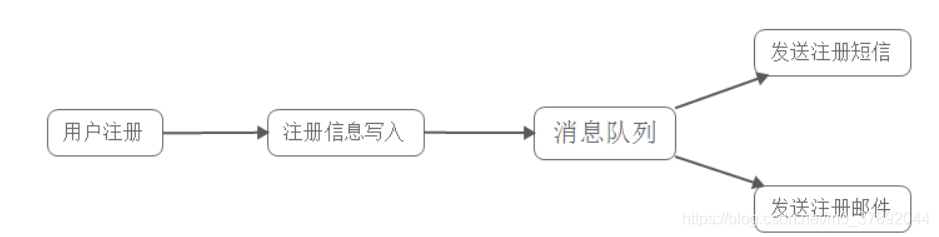
- 降低系统耦合性 -
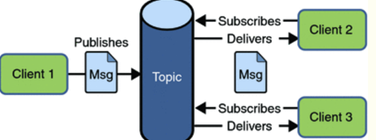
1.3消息队列的两种模式
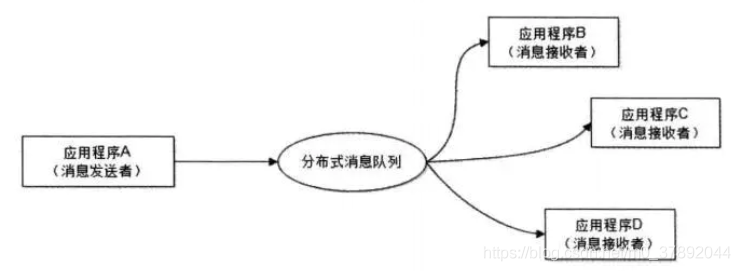
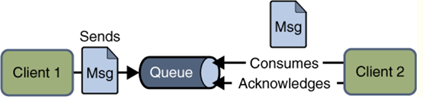
点对点模式
发布订阅模式
- JMS 介绍 -
它提供创建、发送、接收、读取消息的服务。由Sun公司和它的合作伙伴设计的应用程序接口和相应语法,使得Java程序能够和其他消息组件进行通信。
消息队列:计算机科学中,A和B进行通信的一种方式。 JMS:java平台之间分布式通信的一种标准或者规范。
2.1JSM消息模型
2.2JMS消费
同步(Synchronous)
异步(Asynchronous)
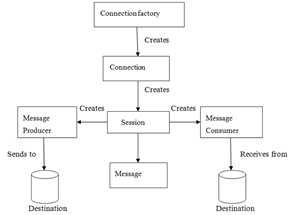
2.3JMS编程模型
SqlSessionFactoryBuilder去构造SqlSessionFactory会话工厂; SqlSessionFactory会话工厂给我们打开SqlSession会话; SqlSession帮我们去连接数据库,接着我们就可以执行增删查改。
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession openSession = sqlSessionFactory.openSession(true);
ProjectMapper mapper = openSession.getMapper(ProjectMapper.class);
mapper.queryAllTaskByInit("init");
Connection Factory给我创建Connection连接; Connection连接给我们创建了Session会话; Session会话给我们创建消费者和生产者; 生产者生成消息; 消费者消费消息;
- 3MQ 介绍 -
3.1AMQP协议
- AMQP 模型 -
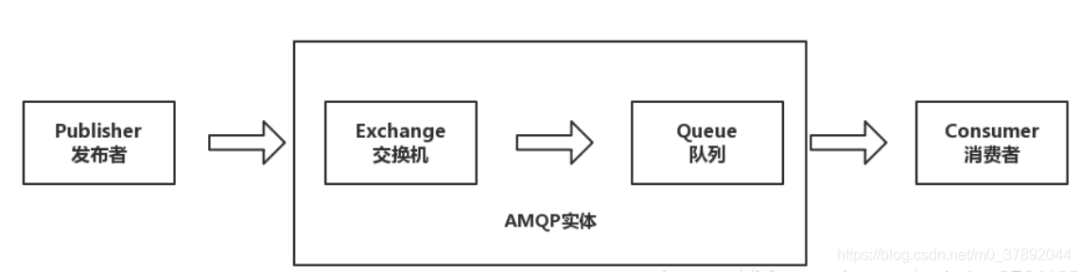
AMQP工作过程
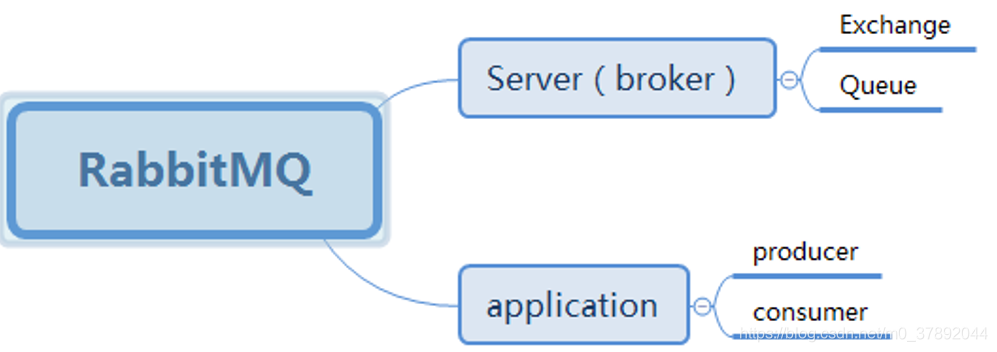
3.2RabbitMQ模型
服务端包括:队列和交换机。 客户端包括:生产者和消费者。
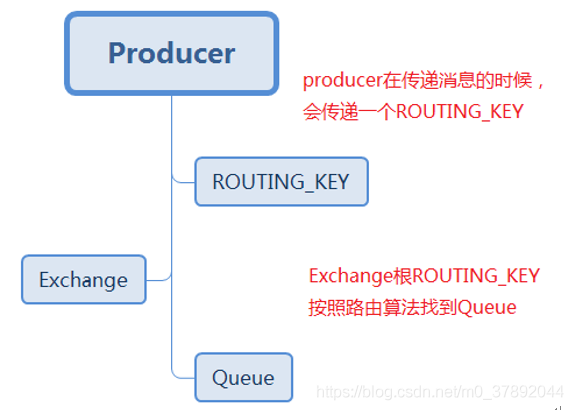
Direct:直接交换器,工作方式类似于单播,Exchange会将消息发送完全匹配ROUTING_KEY的Queue。 Fanout:广播是式交换器,不管消息的ROUTING_KEY设置为什么,Exchange都会将消息转发给所有绑定的Queue(所谓绑定就是将一个特定的 Exchange 和一个特定的 Queue 绑定起来。Exchange 和Queue的绑定可以是多对多的关系)。 Topic:主题交换器,工作方式类似于组播,Exchange会将消息转发和ROUTING_KEY匹配模式相同的所有队列,比如,ROUTING_KEY为user.stock的Message会转发给绑定匹配模式为 * .stock,user.stock, * . * 和#.user.stock.#的队列。( * 表是匹配一个任意词组,#表示匹配0个或多个词组)。
- Kafka -
4.1 kafka原理图
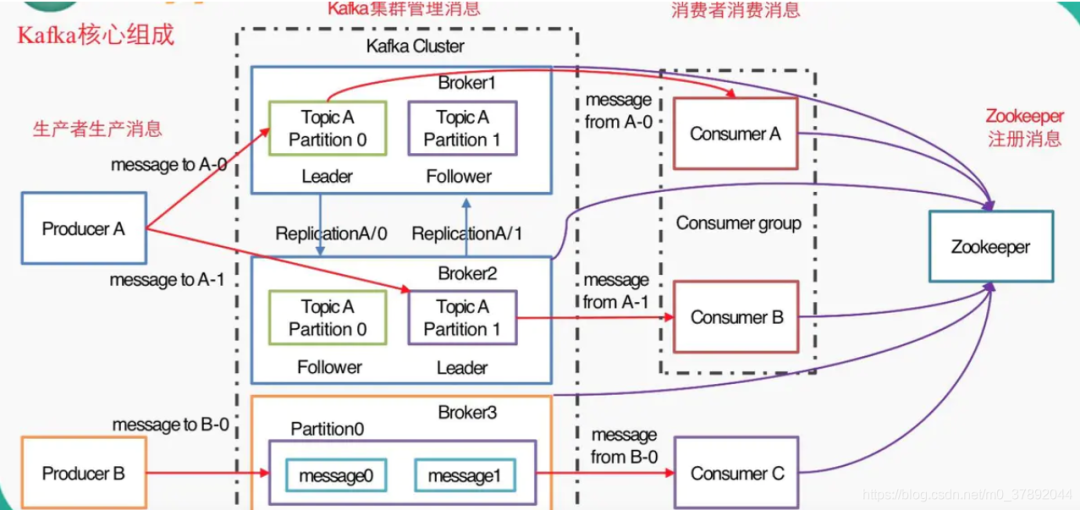
Producer :消息生产者,就是向kafka broker发消息的客户端。 Consumer :消息消费者,向kafka broker取消息的客户端。 Topic :kafka给消息提供的分类方式。broker用来存储不同topic的消息数据。一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。 broker:中间件的kafka cluster,存储消息,是由多个server组成的集群。 Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。 Offset:kafka的存储文件都是按照offset.kafka来命名,例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
- Kafka 高可用机制 -
多个broker组成,每个broker是一个节点; 你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。 采用replica副本机制,每个partition的数据都会同步到其他机器上,形成多个replica副本。 所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,然后其他replica就是follower。 读数据时,从leader读取,写数据时,leader把数据同步到所有follower上去。如果某个broker宕机了,这个broker在其他的broker还保留副本,假设这个broker上面存在leader,那么就重新选一个leader。
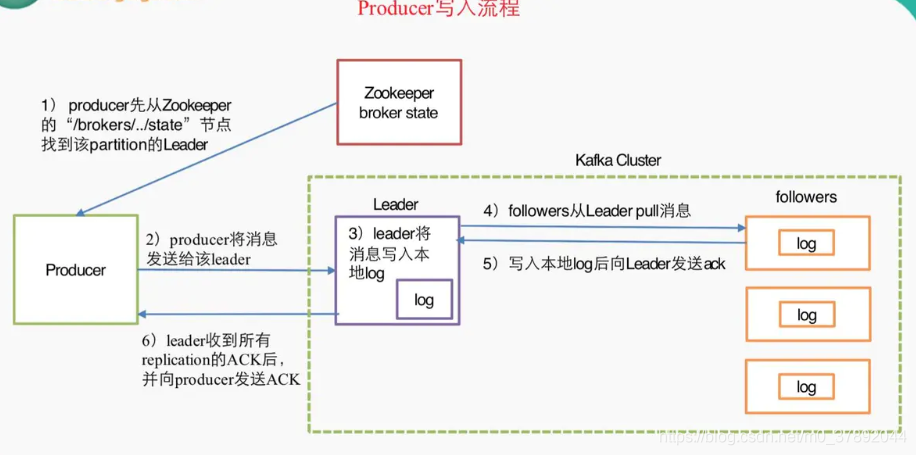
4.2生产者结构图
消息队列:指计算机领域中,A和B通信的一种通信方式; JMS:Java中对于消息队列的接口规范; ActiveMQ/RabbitMQ:JMS接口规范具体实现的一种技术; RocketMQ:不完全是JMS接口规范具体实现的一种技术; Kafka:非JMS接口规范具体实现的一种技术;
作者:歪桃
来源:
blog.csdn.net/m0_37892044/article/details/106603925

评论