
我又被吐槽啦
大家好,我是3y,一年CRUD经验用十年的markdown程序员👨🏻💻常年被誉为职业八股文选手
我又又又又被吐槽了,随之而来,我的消息推送平台开源项目Austin又又又又更新啦,迭代自己的项目多是一件美事啊。
01、可插拔
我的项目逐渐成型了之后,有挺多小伙伴吐槽过我的项目太重了,依赖的中间件有点多。
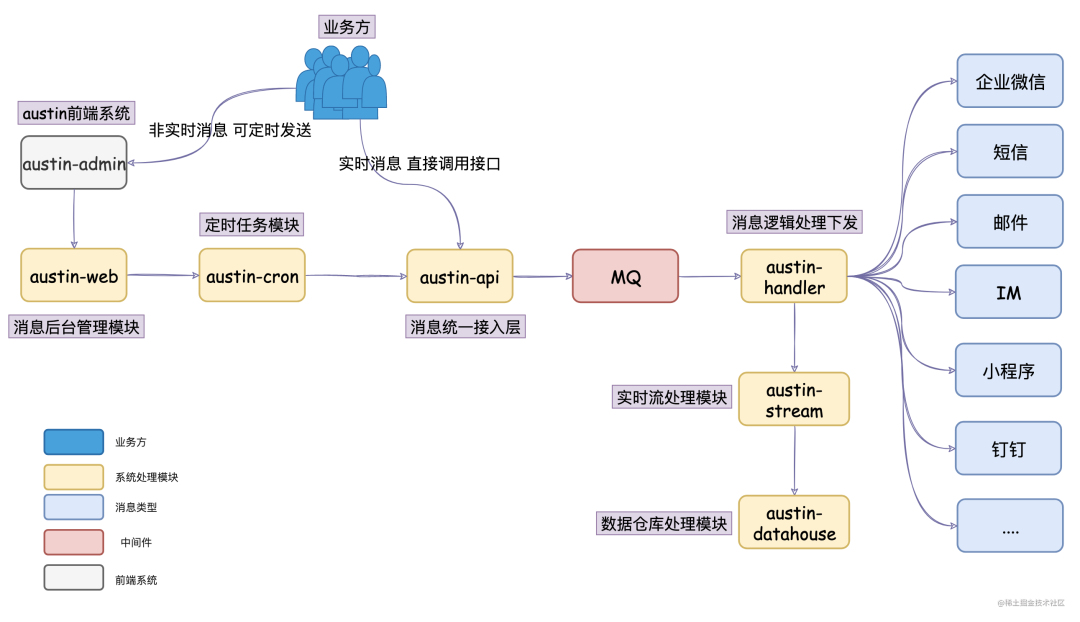
在最开始的那一版需要强依赖MySQL/Redis/Kafka/Apollo(项目启动就需要部署这些中间件),弱依赖prometheus/graylog/flink/xxl-job(想要有完整的项目体验,就需要把这些给部署起来)。
MySQL是没有人吐槽的,数据库这种东西,可以说是后端必需的了。
Redis暂时还没人吐槽,毕竟用的还是太多了,也没有什么强大的竞品。
Apollo经常被吐槽能不能换成Nacos。
Kafka时而有人吐槽,想要支持RabbitMQ、RocketMQ。
我以前存在个观念:在公司里中间件是不会轻易替换的,现在我的代码已经实现了一种姿势,感觉没多大必要支持多种中间件实现,你想换就自己动手改改嘛,又不难。
「“Apollo太重啦,Apollo不好用!快点支持Nacos!”」「“支持RocketMQ好不好啊”」「“能不能支持RabbitMQ?”」
对我来说并不是啥大理由,我还是觉得Apollo挺好用,足够成熟稳定,同理Kafka亦是如此。不过当我被吐槽多了,总会怀疑自己是不是做得不够好,也会跟身边的大佬讨论讨论,有没有必要支持一些功能。
思来想去,我变了,我又懂了
为了让消息推送平台Austin易上手,我首先把Apollo做成弱依赖,可以通过配置选择读本地文件还是读配置中心(Apollo)。其实当我们使用Apollo时,即便Apollo挂了,Apollo本身就有很强的容灾能力(自带本地文件)
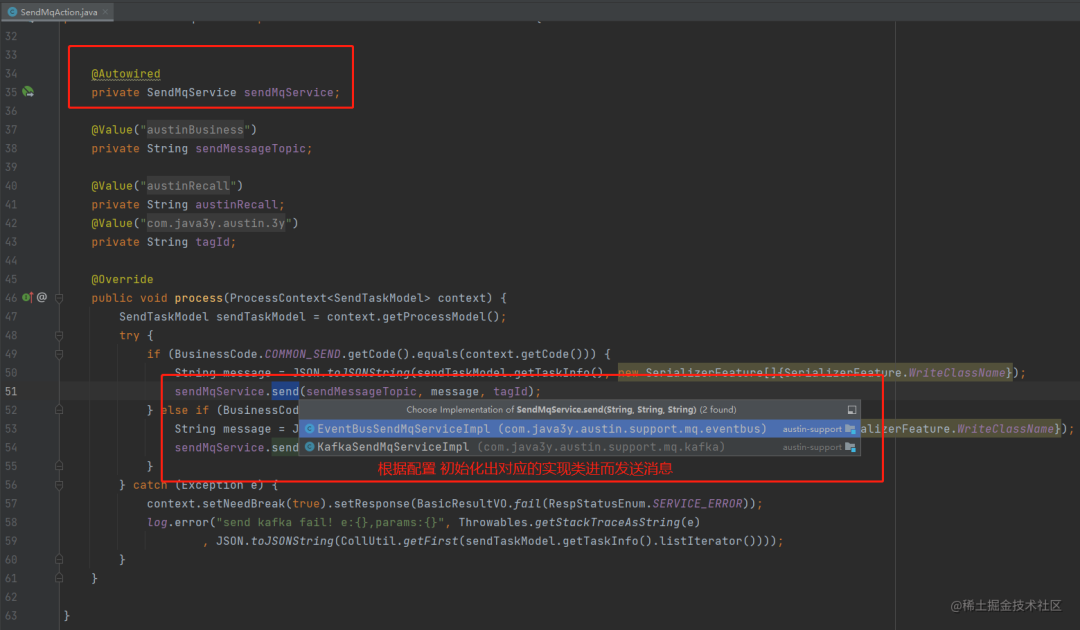
其次,我把Kafka做成弱依赖,可以通过配置选择用Guava的eventbus还是走分布式消息队列(Kafka),后续可能还会支持RocketMQ/RabbitMQ,感兴趣的也可以在我的代码基础上实现一把,蹭个pull request也很香的。
一方面是降低使用门槛而做的,另一方面是可以对具体实现进行可插拔,这是开源项目所需要的。我认为如果是公司级生产环境线上的项目,对这块更多考虑的是异构容灾(而非可插拔)。
于是乎,现在消息推送平台Austin默认的强依赖只剩下了MySQL和Redis,其他中间件的都是弱依赖,要做到可插拔我是借助配置去实例化不同的中间件。
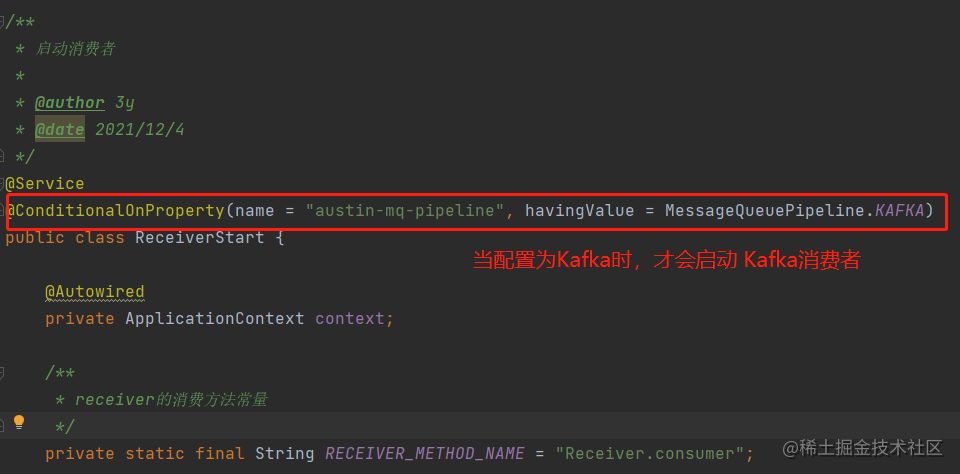
当我的配置austin-mq-pipeline=eventbus时,我就不去实例化Kafka相关的生产者和消费者,转而去初始化eventBus的生产者和消费者,那自然接口下的实现类就是为eventbus的
02、Kafka支持Tag过滤
我的股东们是能直接用我的远程服务的:Kafka的Topic是共享的,Group消费者也是共享的,在不修改的前提下,直接使用会带来一个问题。
当同时有两个或以上的股东在本地启动了Austin,那就会争抢消费这个Topic(相当于一个消费者组里起了多个消费者),导致在测试下发的时候可能收不到自己调试的消息(被别的股东抢去了)。
要解决这个问题我第一时间的想法很简单:不同的股东使用不同的group(相当于每个股东都会有独立的消费者组),那不就完事了嘛?正好我的groupId生成是依赖渠道的code,改掉code就完事咯。
但这还是有问题的:每个股东有独立的消费者组,意味着每个股东能消费整个topic的所有消息,这又意味着股东会接受到其他股东的测试消息(明明只想要自己测试的消息,却来了一条其他人发的)。
要解决这个问题,除了给每个股东一个独立的topic,那就是根据tag过滤啦。
在Kafka实现这种效果,挺简单的:在发送的时候,把tag写进Kafka的头部,在消费前把非自身tag的消息过滤掉就完事了。
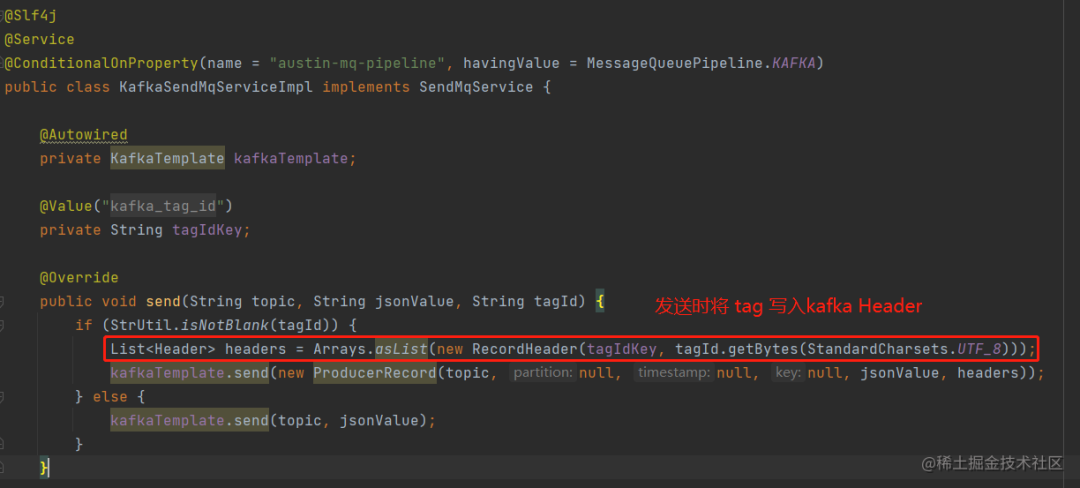
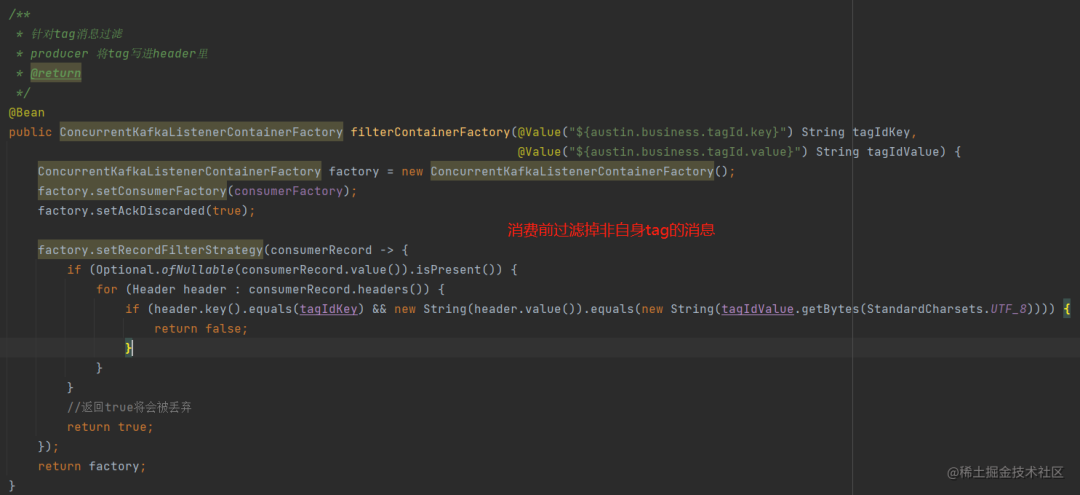
03、总结
从开始写这个项目到现在还一直在迭代,这个过程受到了不少的吐槽。这种吐槽大多数是正向的,毕竟有人吐槽那才说明我这个项目是真的有人在用的,有人在看的。
最近有个想法:把这个系统做成是线上的,可以由各大开发者在推送消息的时候调用我的接口,做成这样一定会很有意思,面临的挑战和需求也会更多。那我就一直可以迭代,在这过程中一定我还能学到很多以前所不知道的东西。
今天就到这吧,下次我更新了代码再跟大家聊聊我的项目,我是3y下期再见!
 最近我开通了
最近我开通了阅读原文可跳转至消息推送平台仓库