
What, 数据库脑裂了?
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

在朋友圈,我经常唠叨,数据中心的两地三中心架构。
郑州的期货交易所,就是采用了这样的架构,在三次暴雨袭击后,仍能屹立不倒,从容不迫服务每笔交易。详细请戳这里:
两地三中心
在这里,先回顾下郑交所(郑州期货交易所)两地三中心架构:
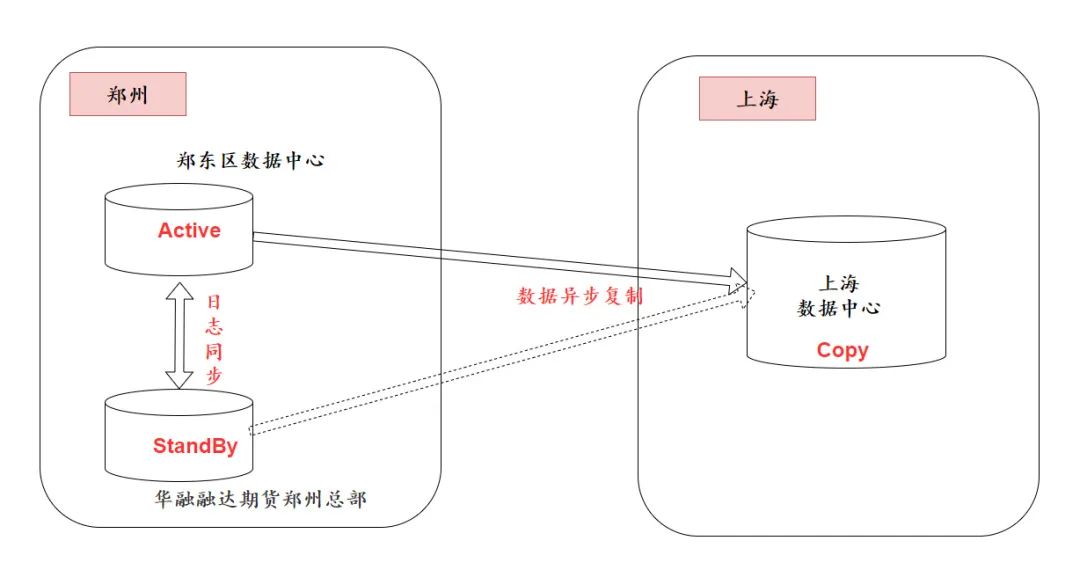
两地三中心,以郑交所为例,两地便是“郑州”和“上海”,三中心,便是“郑东区数据中心”、“华融融达期货郑州总部”和“上海数据中心”。
两地三中心的架构,可以预防本地(郑州)级别的小概率自然灾害,还可以预防全国性的自然灾害。能将郑州和上海同时都端掉的自然灾害或人为行为,几乎不存在。除非是像电影《后天》里面那种极端事件。
复制是基础
对于我们这些技术理工宅来说,感兴趣的莫过于这里面的数据复制技术。同城之间采用了什么复制技术,异地之间又采用了什么复制模式,究竟如何保持三中心的数据一致,每个技术人都迫不及待的想知道。
我没有郑交所的工作经历,并不知道具体内幕。但我知道,数据库的复制,逃不过这几类:
- Leader-based replication 主从复制
- MultiLeader-based replication 多主复制
- Leaderless-based replication 无主复制
最常用的一类,当属主从复制。
电影,硬核复制玩家
小时候,村里经常会来放露天电影。播映小组临时搭个台面,全村人都挤到一块儿,嗑着瓜子,喝着汽水,早早扎个好地儿,一站连看1-2小时,都不叫腿酸的。

露天电影及其考验耳朵,在后排的,听不清;站前排的,又吵的扎耳朵,观感体验不是很好。每场电影的人数,虽说没人管,其实际上是有限制的。
放露天电影,相当于是用户在读取数据。
要想让观众看得爽,收更多的电影入场费,怎么办呢?把电影多复制几份,找多块场地播放。村头一场,村尾同时办一场。分流后,不仅总人数多了,观众体验也极强。看了还想看!
所以数据库想要伺候越来越多的读请求,也只要多复制几份,强子说的“多加三倍服务器”,确实没毛病。
电影院越开越大,屏幕越来越多,满足上千人观影同时,还不影响效果。这就是多副本的好处。
数据库也同理。
直播,复制新玩家
但电影拷贝是冷拷贝,在复制完主盘之后,所有的副本都是一致相同的。所以没什么实时的障碍。
拿体育赛事,比如京东奥运直播来说,实时性就要求高了。可以与现场稍有时差,但总不能太大。现场中国队都拿20枚金牌了,转播到国内,我们还在庆祝第10枚金牌,发个朋友圈,不是被笑死!
比如,苏神在跑9.83秒那场,正跟着苏神一起冲冲冲的时候,突然画面嘎嘣下,刹那间,仿佛宇宙毁灭,成了一束光。晃过神,才发现视频雪花了。那不是要急死人,问候下转播台的祖宗长辈,就不过分了!
数据库玩复制,俺也一样
数据库也一样,在多副本开启的同时,总不能让用户老看昨天的数据。也不能说,用户在北京发条微博,回到上海就看不见了。
主从复制,要解决两件事:
- 数据复制到多个数据库
- 保持多个副本数据的一致性
这两件事,带来的好处是:
- 读写分离,提高吞吐
- 切换故障的数据库
复制,提高吞吐
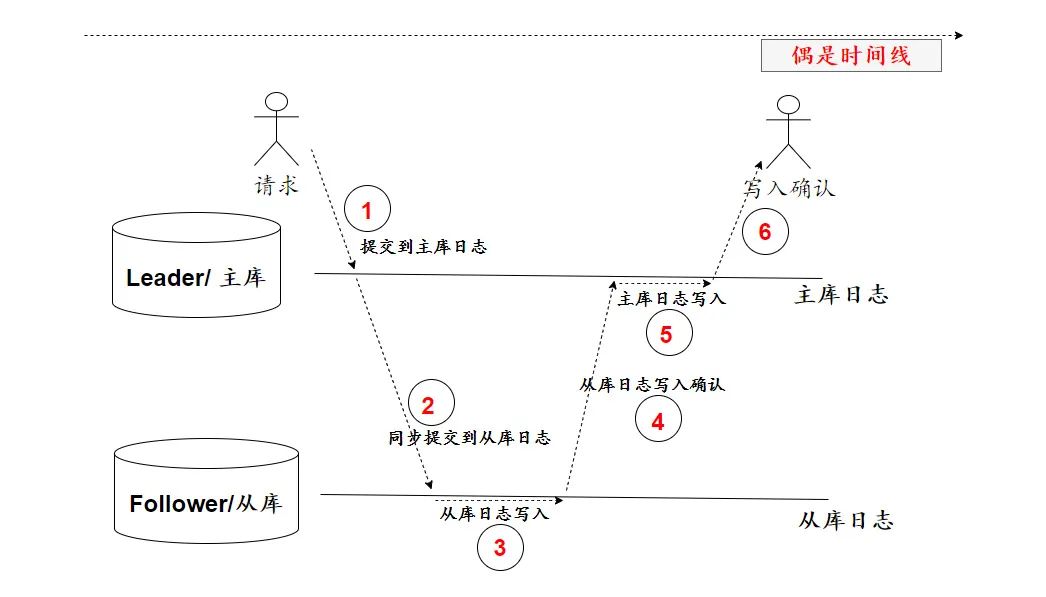
由上,主从库之间,采用同步复制,时刻保持一致。主库承担写,从库承载读。原本一台库要处理读写,现在分成2台。响应更快,吞吐量(处理的请求)更高。
但是,这样设计,一定就很完美么?显然不是!全是坑
首先,只有一个主库时,主库日志写入,更新就算成功。而现在主从架构,还要等从库完成日志写入,主库才能提交日志。
1-5个步骤里,任何一个失败,本次提交,就算失败。增加一个节点,意味着增加一个失败因子。从库的反应只要稍差那么点时间,主库就会认为从库挂了,从而回滚操作。
当再增加“从从”库,虽说能服务的用户更多,但等待时间也会线性加倍延长,而且大有提高更新失败的概率。
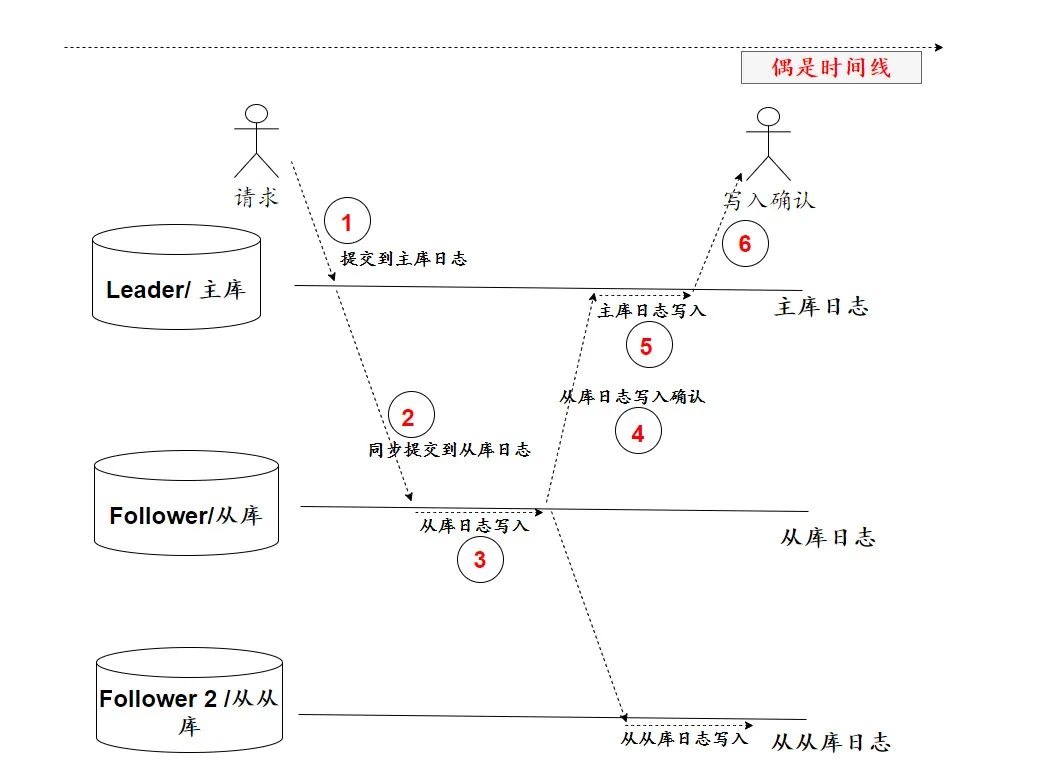
当每一个从库都采用同步策略时,仅等待日志确认,都可以杀死一大批请求。而当采用异步时,从从从库的数据又丧失了与主库的一致性。
因此,折中的办法就是一台从库采用同步,其他从库则采用异步复制数据。
复制,一个倒下去,另一个站起来
数据复制的另一个好处,提供高可用。
当主库下线时,从库接替主库,开始服务用户请求。原下线的主库,此时变成了从库。等再次回来时,新主库把下线时间内的数据更新,补回老主库去。
这样,虽说服务速度慢下来,始终还能保持系统可用。
好玩的是,等老主库上线后,因各种原因,比如网络抖动暂时中断,造成新主库与老主库之间通信受阻,两边都认为自己是主库,此时便产生了脑裂(split brain),即新旧主库都接受写入。
该怎么办呢,咳咳,我们下回再讲!
往期精彩: