SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id = 'RGAN01'));
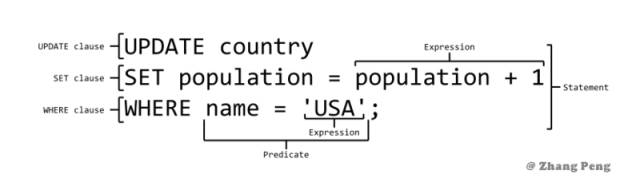
WHERE
WHERE 子句用于过滤记录,即缩小访问数据的范围。
WHERE 后跟一个返回 true 或 false 的条件。
WHERE 可以与 SELECT,UPDATE 和 DELETE 一起使用。
可以在 WHERE 子句中使用的操作符
运算符
描述
=
等于
<>
不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=
>
大于
<
小于
>=
大于等于
<=
小于等于
BETWEEN
在某个范围内
LIKE
搜索某种模式
IN
指定针对某个列的多个可能值
SELECT 语句中的 WHERE 子句
SELECT * FROM Customers WHERE cust_name = 'Kids Place';
UPDATE 语句中的 WHERE 子句
UPDATE Customers SET cust_name = 'Jack Jones' WHERE cust_name = 'Kids Place';
DELETE 语句中的 WHERE 子句
DELETE FROM Customers WHERE cust_name = 'Kids Place';
IN 和 BETWEEN
IN 操作符在 WHERE 子句中使用,作用是在指定的几个特定值中任选一个值。
BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。
IN 示例
SELECT * FROM products WHERE vend_id IN ('DLL01', 'BRS01');
BETWEEN 示例
SELECT * FROM products WHERE prod_price BETWEEN 3 AND 5;
AND、OR、NOT
AND、OR、NOT 是用于对过滤条件的逻辑处理指令。
AND 优先级高于 OR,为了明确处理顺序,可以使用 ()。
AND 操作符表示左右条件都要满足。
OR 操作符表示左右条件满足任意一个即可。
NOT 操作符用于否定一个条件。
AND 示例
SELECT prod_id, prod_name, prod_price FROM products WHERE vend_id = 'DLL01' AND prod_price <= 4;
OR 示例
SELECT prod_id, prod_name, prod_price FROM products WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
NOT 示例
SELECT * FROM products WHERE prod_price NOT BETWEEN 3 AND 5;
LIKE
LIKE 操作符在 WHERE 子句中使用,作用是确定字符串是否匹配模式。
只有字段是文本值时才使用 LIKE。
LIKE 支持两个通配符匹配选项:% 和 _。
不要滥用通配符,通配符位于开头处匹配会非常慢。
% 表示任何字符出现任意次数。
_ 表示任何字符出现一次。
% 示例
SELECT prod_id, prod_name, prod_price FROM products WHERE prod_name LIKE '%bean bag%';
_ 示例
SELECT prod_id, prod_name, prod_price FROM products WHERE prod_name LIKE '__ inch teddy bear';
SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id;
自连接
SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM customers c1, customers c2 WHERE c1.cust_name = c2.cust_name AND c2.cust_contact = 'Jim Jones';
自然连接(NATURAL JOIN)
SELECT * FROM Products NATURAL JOIN Customers;
左连接(LEFT JOIN)
SELECT customers.cust_id, orders.order_num FROM customers LEFT JOIN orders ON customers.cust_id = orders.cust_id;
右连接(RIGHT JOIN)
SELECT customers.cust_id, orders.order_num FROM customers RIGHT JOIN orders ON customers.cust_id = orders.cust_id;
组合(UNION)
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 基本规则
所有查询的列数和列顺序必须相同。
每个查询中涉及表的列的数据类型必须相同或兼容。
通常返回的列名取自第一个查询。
默认会去除相同行,如果需要保留相同行,使用 UNION ALL。
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
应用场景
在一个查询中从不同的表返回结构数据。
对一个表执行多个查询,按一个查询返回数据。
组合查询
SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNION SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name = 'Fun4All';
JOIN vs UNION
JOIN vs UNION
JOIN 中连接表的列可能不同,但在 UNION 中,所有查询的列数和列顺序必须相同。
UNION 将查询之后的行放在一起(垂直放置),但 JOIN 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。
五、函数
🔔 注意:不同数据库的函数往往各不相同,因此不可移植。本节主要以 Mysql 的函数为例。
文本处理
函数
说明
LEFT()、RIGHT()
左边或者右边的字符
LOWER()、UPPER()
转换为小写或者大写
LTRIM()、RTIM()
去除左边或者右边的空格
LENGTH()
长度
SOUNDEX()
转换为语音值
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
SELECT * FROM mytable WHERE SOUNDEX(col1) = SOUNDEX('apple')
日期和时间处理
日期格式:YYYY-MM-DD
时间格式:HH:MM:SS
函 数
说 明
AddDate()
增加一个日期(天、周等)
AddTime()
增加一个时间(时、分等)
CurDate()
返回当前日期
CurTime()
返回当前时间
Date()
返回日期时间的日期部分
DateDiff()
计算两个日期之差
Date_Add()
高度灵活的日期运算函数
Date_Format()
返回一个格式化的日期或时间串
Day()
返回一个日期的天数部分
DayOfWeek()
对于一个日期,返回对应的星期几
Hour()
返回一个时间的小时部分
Minute()
返回一个时间的分钟部分
Month()
返回一个日期的月份部分
Now()
返回当前日期和时间
Second()
返回一个时间的秒部分
Time()
返回一个日期时间的时间部分
Year()
返回一个日期的年份部分
mysql> SELECT NOW();
2018-4-1420:25:11
数值处理
函数
说明
SIN()
正弦
COS()
余弦
TAN()
正切
ABS()
绝对值
SQRT()
平方根
MOD()
余数
EXP()
指数
PI()
圆周率
RAND()
随机数
汇总
函 数
说 明
AVG()
返回某列的平均值
COUNT()
返回某列的行数
MAX()
返回某列的最大值
MIN()
返回某列的最小值
SUM()
返回某列值之和
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以让汇总函数值汇总不同的值。
SELECT AVG(DISTINCT col1) AS avg_col FROM mytable
六、排序和分组
ORDER BY
ORDER BY 用于对结果集进行排序。
ASC :升序(默认)
DESC :降序
可以按多个列进行排序,并且为每个列指定不同的排序方式
指定多个列的排序方向
SELECT * FROM products ORDER BY prod_price DESC, prod_name ASC;
GROUP BY
GROUP BY 子句将记录分组到汇总行中。
GROUP BY 为每个组返回一个记录。
GROUP BY 通常还涉及聚合:COUNT,MAX,SUM,AVG 等。
GROUP BY 可以按一列或多列进行分组。
GROUP BY 按分组字段进行排序后,ORDER BY 可以以汇总字段来进行排序。
分组
SELECT cust_name, COUNT(cust_address) AS addr_num FROM Customers GROUP BY cust_name;
分组后排序
SELECT cust_name, COUNT(cust_address) AS addr_num FROM Customers GROUP BY cust_name ORDER BY cust_name DESC;
HAVING
HAVING 用于对汇总的 GROUP BY 结果进行过滤。
HAVING 要求存在一个 GROUP BY 子句。
WHERE 和 HAVING 可以在相同的查询中。
HAVING vs WHERE
WHERE 和 HAVING 都是用于过滤。
HAVING 适用于汇总的组记录;而 WHERE 适用于单个记录。
使用 WHERE 和 HAVING 过滤数据
SELECT cust_name, COUNT(*) AS num FROM Customers WHERE cust_email IS NOT NULL GROUP BY cust_name HAVING COUNT(*) >= 1;
(以下为 DDL 语句用法)
七、数据定义
DDL 的主要功能是定义数据库对象(如:数据库、数据表、视图、索引等)。
数据库(DATABASE)
创建数据库
CREATE DATABASE test;
删除数据库
DROP DATABASE test;
选择数据库
USE test;
数据表(TABLE)
创建数据表
普通创建
CREATE TABLE user ( id int(10) unsigned NOT NULL COMMENT 'Id', username varchar(64) NOT NULL DEFAULT 'default' COMMENT '用户名', password varchar(64) NOT NULL DEFAULT 'default' COMMENT '密码', email varchar(64) NOT NULL DEFAULT 'default' COMMENT '邮箱' ) COMMENT='用户表';
根据已有的表创建新表
CREATE TABLE vip_user AS SELECT * FROM user;
删除数据表
DROP TABLE user;
修改数据表
添加列
ALTER TABLE user ADD age int(3);
删除列
ALTER TABLE user DROP COLUMN age;
修改列
ALTER TABLE `user` MODIFY COLUMN age tinyint;
添加主键
ALTER TABLE user ADD PRIMARY KEY (id);
删除主键
ALTER TABLE user DROP PRIMARY KEY;
视图(VIEW)
定义
视图是基于 SQL 语句的结果集的可视化的表。
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
作用
简化复杂的 SQL 操作,比如复杂的联结;
只使用实际表的一部分数据;
通过只给用户访问视图的权限,保证数据的安全性;
更改数据格式和表示。
创建视图
CREATE VIEW top_10_user_view AS SELECT id, username FROM user WHERE id < 10;
DROP PROCEDURE IF EXISTS `proc_adder`; DELIMITER ;; CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int) BEGIN DECLARE c int; if a is null then set a = 0; end if;
if b is null then set b = 0; end if;
set sum = a + b; END ;; DELIMITER ;
使用存储过程
set @b=5; call proc_adder(2,@b,@s); select @s as sum;
DELIMITER $ CREATE PROCEDURE getTotal() BEGIN DECLARE total INT; -- 创建接收游标数据的变量 DECLARE sid INT; DECLARE sname VARCHAR(10); -- 创建总数变量 DECLARE sage INT; -- 创建结束标志变量 DECLARE done INT DEFAULT false; -- 创建游标 DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30; -- 指定游标循环结束时的返回值 DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true; SET total = 0; OPEN cur; FETCH cur INTO sid, sname, sage; WHILE(NOT done) DO SET total = total + 1; FETCH cur INTO sid, sname, sage; END WHILE;
DELIMITER $ CREATE TRIGGER `trigger_insert_user` AFTER INSERT ON `user` FOR EACH ROW BEGIN INSERT INTO `user_history`(user_id, operate_type, operate_time) VALUES (NEW.id, 'add a user', now()); END $ DELIMITER ;