
YOLOv6、PP-YOLOE、PicoDet为什么都选择了TOOD?
极市导读
MT-YOLOv6的Label Assignment选择的是和YOLOX一样的SimOTA,PP-YOLOE选择的却是TOOD,而YOLOv6再开源时也选择了TOOD。为何诸多目标检测器都选择TOOD呢?本文带你一探究竟! >>加入极市CV技术交流群,走在计算机视觉的最前沿

最近关于YOLO卷起飞的事情一直耿耿于怀,但又跃跃欲试,在MT-YOLOv6开源时还并没有多么感冒,到AB大神认可YOLOv6时便感觉势头不对,应该卷一下了,于是便研究了一下YOLOv6、PP-YOLOE,其实对于目标检测出来网络结构,我最感冒的可能还是Label Assignment,一开始我知道MT-YOLOv6的Label Assignment选择的是和YOLOX一样的SimOTA,PP-YOLOE选择的却是TOOD,但是YOLOv6再开源时也选择了TOOD,翻了翻其他的检测器发现以速度著称PicoDet也不约而同的选择了TOOD,于是便有了下面的故事!
1、问题的遇见与解决之道
1.1 问题的遇见
目标检测旨在从自然图像中定位和识别感兴趣的目标,是计算机视觉中一项基本但具有挑战性的任务。通过联合优化目标分类和定位,它通常被表述为一个多任务学习问题。分类任务旨在学习专注于目标关键或显著部分的可判别特征,而定位任务则致力于精确定位目标的边界。由于分类和定位的学习机制的不同,两个任务学习到的特征的空间分布可能不同,当使用两个独立的分支进行预测时,也会导致一定程度的错位。
最近的单阶段目标检测器试图通过关注目标的中心来预测两个独立任务的一致输出。假设目标中心的Anchor(即,anchor-free检测器的anchor-point,或anchor-based检测器的anchor-box)可能会为分类和定位提供更准确的预测。例如,最近的 FCOS 和 ATSS 都使用中心分支来增强从靠近目标中心的Anchor预测的分类分数,并为相应Anchor的定位损失分配更大的权重。此外,FoveaBox 将目标预定义中心区域内的Anchor视为正样本。这种启发式设计已经取得了很好的效果,但是这些方法可能会受到两个限制:
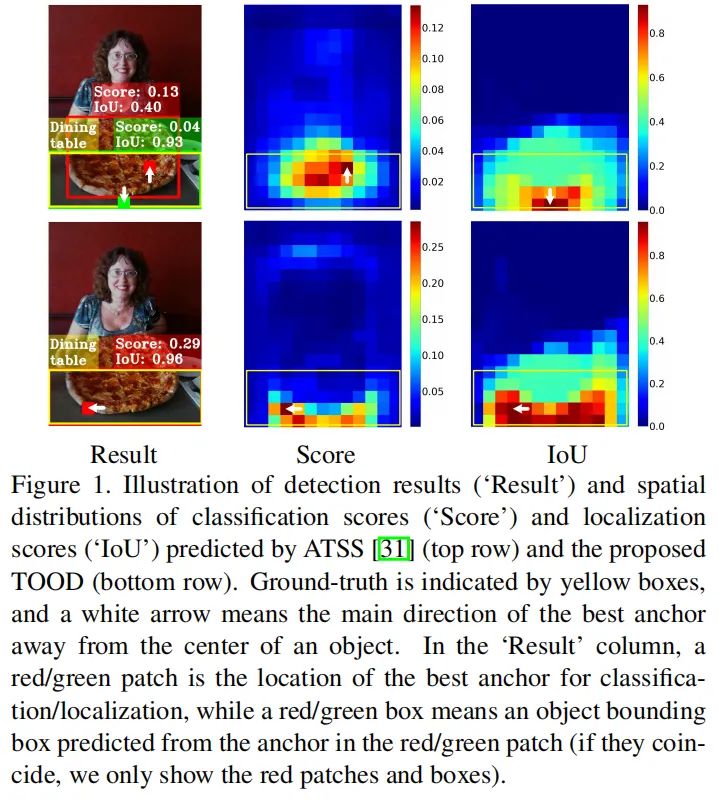
分类和定位的独立性:最近的单阶段检测器通过并行使用两个独立的分支独立地执行分类和定位任务。这样的双分支设计可能会导致两个任务之间缺乏交互,从而导致执行它们时的预测不一致。如图 1 中的“Result”列所示,ATSS 检测器识别出“Dining table”(由带有红色patch的Anchor表示),但更准确地定位了另一个目标“Pizza”(红色边界框)。与任务无关的样本分配:大多数 anchor-free 检测器使用基于几何的分配方案来选择目标中心附近的anchor-points以进行分类和定位,而anchor-based检测器通常通过计算anchor-boxes和GT之间的 IoU 来分配anchor-boxes。然而,用于分类和定位的最佳anchors通常是不一致的,并且可能会根据目标的形状和特征而有很大差异。广泛使用的样本分配方案与任务无关,因此可能难以对这两个任务做出准确而一致的预测,如图 1 中 ATSS 的“Score”和“IoU”分布所示。“Result”列也说明最佳定位anchor(绿色Patch)的空间位置可能不在目标的中心,并且与最佳分类anchors(红色patch)没有很好地对齐。因此,在非最大抑制 (NMS) 期间,精确的边界框可能会被不太准确的边界框抑制。
1.2 解决思路是什么?
为了解决上述两个问题,研究者们提出了一个任务对齐的单阶段目标检测(TOOD),旨在通过设计一个新的Head结构和面向对齐的学习方法来更准确地对齐这两个任务。
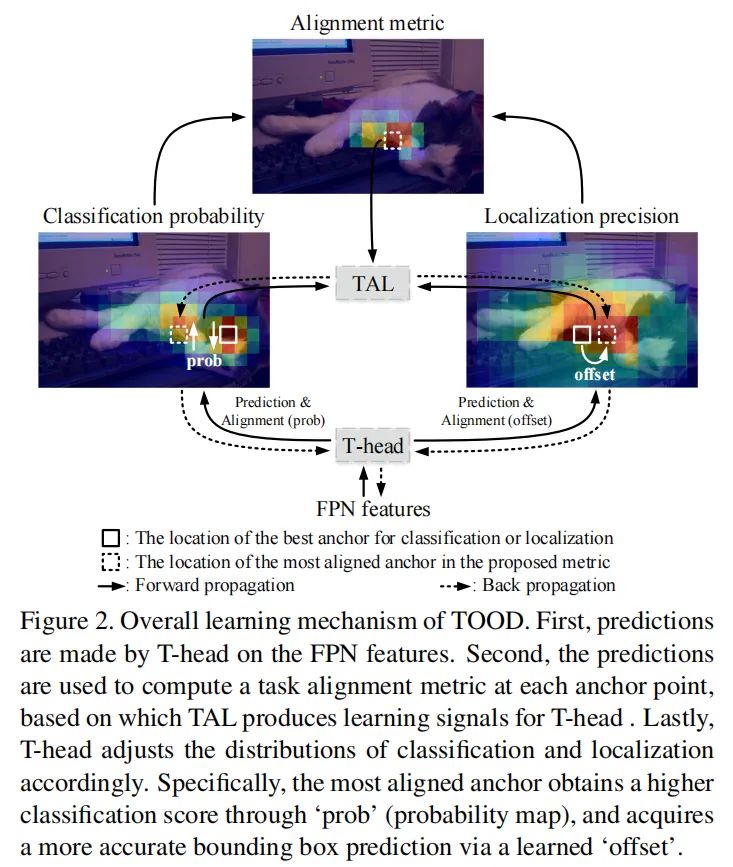
与最近的 GFL 和 ATSS 等单阶段检测器类似,所提出的 TOOD 具有“Backbone-FPN-head”的整体管道。此外,通过考虑效率和简单性,TOOD 每个位置使用单个anchor(与 ATSS 相同),其中“anchor”表示 anchor-free 检测器的anchor point,或 anchor-based 检测器的 anchor box 。
1、任务对齐Head
与传统的单阶段目标检测Head通过并行使用两个分支分别实现分类和定位相比,TOOD架构设计了一个任务对齐Head(T-head)来增强两个任务之间的交互。这使得这两个任务可以更协作地工作,从而更准确地调整预测。T-head 在概念上很简单:它计算任务交互特征,并通过新颖的任务对齐预测器 (TAP) 进行预测。然后它根据任务对齐学习提供的学习信号对齐两个预测的空间分布。
2、任务对齐学习
为了进一步克服错位问题,TOOD中还提出了一个任务对齐学习(TAL)来明确地拉近两个任务的最佳anchors。它是通过设计一个样本分配方案和一个任务对齐的损失来执行的。样本分配通过计算每个anchors的任务对齐程度来收集训练样本(即正样本或负样本),而任务对齐损失逐渐统一最佳anchors,以在训练期间预测分类和定位。因此,在推理时,可以保留具有最高分类分数并共同具有最精确定位的边界框。
2、如何具体进行问题的解决?
2.1、任务对齐Head(T-Head)
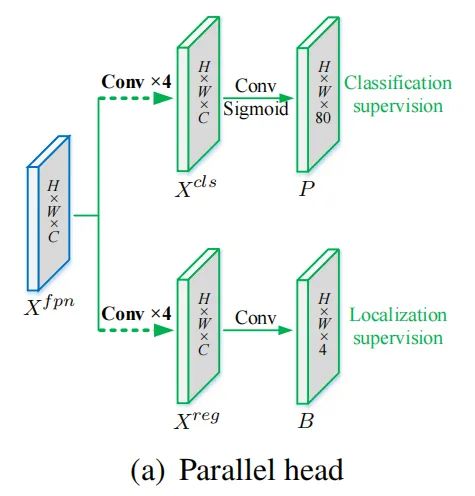
目标是设计一种高效的Head结构,以改进单阶段检测器中head的常规设计(如图(a)所示)。在TOOD中,通过考虑以下2个方面来实现这一点:
增加两个任务之间的交互
增强学习对齐的可检测性
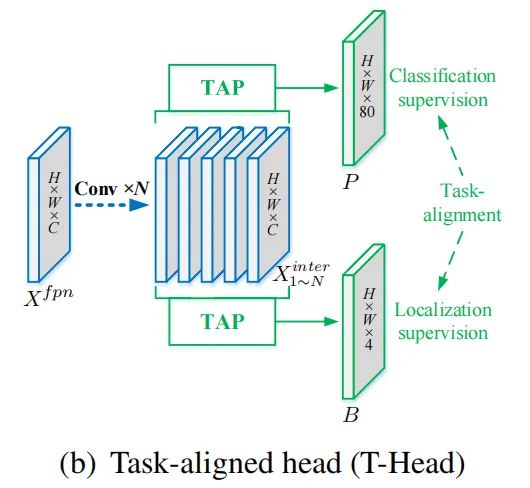
提出的 T-head 如图(b)所示,其中它有一个简单的特征提取器和2个任务对齐预测器 (TAP),如图(c)所示。
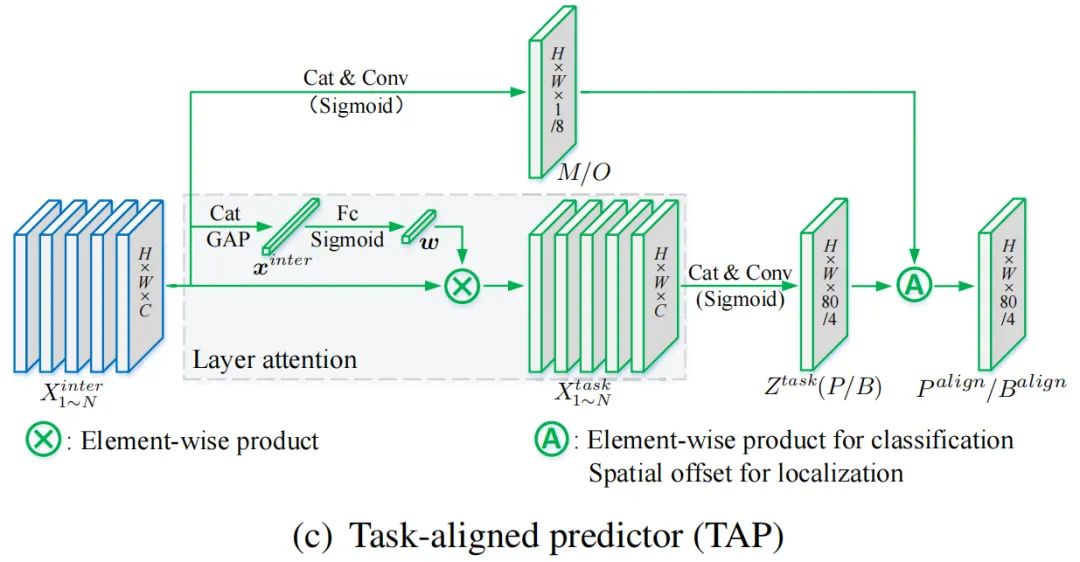
为了增强分类和定位之间的交互,使用特征提取器从多个卷积层中学习任务交互特征,如图(b)中的蓝色部分所示。这种设计不仅方便了任务的交互,而且为两个任务提供了多尺度特征。形式上,令 表示 FPN 特征,其中 H、W 和 C 分别表示高度、宽度和通道数。特征提取器使用 N 个带有激活函数的连续卷积层来计算任务交互特征:
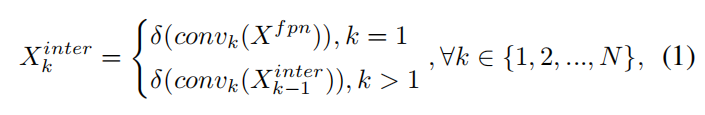
其中 和 δ 分别指第 k 个 conv 层和一个 relu 函数。因此,使用Head中的单个分支从 FPN 特征中提取丰富的多尺度特征。然后,计算出的任务交互特征将被输入到2个 TAP 中用于对齐分类和定位。
1、任务对齐预测器(TAP)
对计算的任务交互特征执行目标分类和定位,这两个任务可以很好地感知彼此的状态。但是,由于单分支设计,任务交互特性不可避免地会在两个不同的任务之间引入一定程度的特征冲突。直观地说,目标分类和定位的任务有不同的目标,因此关注不同类型的特征。因此在TAP中提出了一种Layer attention机制,通过在层级动态计算此类特定于任务的特征来推动任务解耦。如图(c)所示,针对每个分类或定位任务分别计算特定任务的特征:
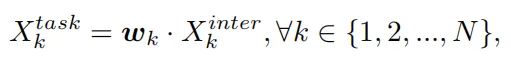
其中 是学习Layer attention 的第 k 个元素。 是通过跨层任务交互特征计算得出的,并且能够捕获层之间的依赖关系:
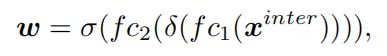
其中 和 指的是两个全连接层。σ 是一个 sigmoid 函数, 是通过对 应用平均池化获得的,这里是通过concat 特征得到的。最后,从每个 预测分类或定位的结果:
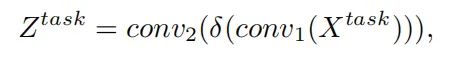
其中 是 的concat特征, 是一个 1×1 的 conv 层,用于降维。然后使用 函数将 转换为密集分类分数 ,或者使用 FCOS 和 ATSS 中应用的distance-to-bbox转换的目标边界框 。
2、预测对齐
在预测步骤,通过调整2个预测的空间分布进一步明确地对齐两个任务:P 和 B。不同于以往使用centerness分支或IoU分支的工作,它们只能根据分类特征或定位特征来调整分类预测,TOOD通过使用计算的任务交互特征联合考虑两个任务来对齐两个预测。值得注意的是分别对这两个任务执行对齐方法。如图(c)所示,使用空间概率图 来调整分类预测:
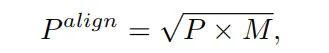
其中 M 是从交互特征中计算出来的,允许它在每个空间位置学习两个任务之间一定程度的一致性。
同时,为了对定位预测进行对齐,进一步从交互特征中学习空间偏移图 ,用于调整每个位置的预测边界框。具体来说,学习到的空间偏移使最对齐的Anchor能够识别其周围的最佳边界预测:
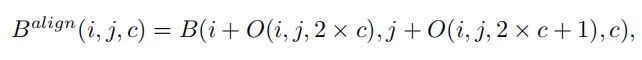
其中索引 表示张量中第 c 个通道的第 个空间位置。上式是通过双线性插值实现的,由于 B 的通道维度非常小,其计算开销可以忽略不计。值得注意的是,每个通道的偏移量是独立学习的,这意味着目标的每个边界都有自己的学习偏移量。这允许对4个边界进行更准确的预测,因为它们中的每一个都可以从其附近最精确的Anchor单独学习。因此,TOOD方法不仅对齐了两个任务,而且通过为每一侧识别一个精确的Anchor来提高定位精度。
对齐图 M 和 O 是从交互式特征堆栈中自动学习的:
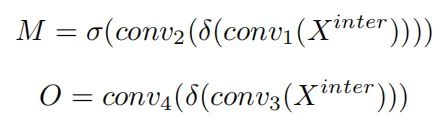
T-head 是一个独立的模块,并且可以在没有 TAL 的情况下正常工作。它可以很容易地以即插即用的方式应用于各种单阶段目标检测器,进而提高检测性能。
2.2、任务对齐学习 (TAL)
TOOD还进一步引入了任务对齐学习 (TAL),进一步指导 T-head 进行任务对齐的预测。TAL 在两个方面与以前的方法不同。首先,从任务对齐的角度来看,它根据设计的指标动态选择高质量的Anchor。其次,它同时考虑Anchor分配和加权。它包括一个样本分配策略和专门为对齐两个任务而设计的新损失。
1、任务对齐样本分配
为了应对 NMS,训练实例的Anchor分配应满足以下规则:
对齐良好的Anchor应该能够预测高分类分数和精确的定位;
未对齐的Anchor应该有一个低分类分数并随后被抑制。
有了这两个目标,TOOD设计了一个新的Anchor对齐指标来明确测量anchor level的任务对齐程度。对齐度量被集成到样本分配和损失函数中,以动态优化每个Anchor的预测。
Anchor alignment metric
考虑到预测边界框和ground truth之间的分类分数和IoU表明了两个任务的预测质量,使用分类分数和IoU的高阶组合来衡量任务对齐的程度。具体来说设计了以下指标来计算每个实例的anchor level对齐:
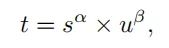
其中 s 和 u 分别表示分类 Score 和 IoU 值。α 和 β 用于控制2个任务在anchor对齐度量中的影响。值得注意的是,t 在2个任务的联合优化中起着关键作用,以实现任务对齐的目标。它鼓励网络从联合优化的角度动态关注高质量(即任务对齐)Anchor。
Training sample assignment
正如 ATSS 和 FreeAnchor 中所讨论的,训练样本分配对于目标检测器的训练至关重要。为了提高两个任务的对齐,TOOD专注于任务对齐的anchors,并采用简单的分配规则来选择训练样本:对于每个实例,选择m个t值最大的anchor作为正样本,而使用剩余的anchors为负样本。同样,训练是通过计算专门为对齐分类和定位任务而设计的新损失函数来执行的。
2、任务对齐损失
Classification objective
为了显式增加对齐anchors的分类分数,同时降低未对齐anchors的分数(即具有较小的 t),在训练期间使用 t 替换正anchors的二进制标签。然而,作者发现当正anchors的标签(即 t)随着 α 和 β 的增加而变小时,网络无法收敛。因此,使用一个归一化的 t,即,来代替正anchors的二进制标签,其中 通过以下两个属性进行归一化:
(1) 确保困难实例的有效学习(对于所有相应的正anchors通常都有一个小的 t);
(2) 根据预测边界框的精度保持实例之间的排名。
因此,采用简单的实例归一化来调整 的规模: 的最大值等于每个实例内的最大 IoU 值 (u)。然后在分类任务的正anchors上计算的二元交叉熵(BCE)可以重写为,
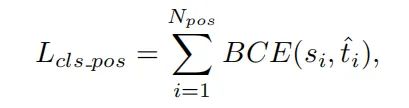
其中 i 表示对应于一个实例的 个正anchors中的第 i 个anchors。采用Focus Loss进行分类,以减轻训练期间负样本和正样本之间的不平衡。在正anchors上计算的focal loss可以用下式重新表示,分类任务的最终损失函数定义如下:
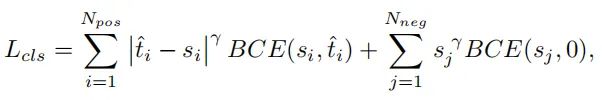
其中 j 表示 个负anchors中的第 j 个anchors,γ 是focus参数。
Localization objective
由良好对齐的anchor(即具有较大的t)预测的边界框通常具有较大的分类分数和精确的定位,并且在NMS期间更有可能保留这样的边界框。此外,t 可以通过更仔细地加权损失来选择高质量的边界框,以改进训练。正如在 Libra r-cnn 中所讨论的,从高质量的边界框中学习有利于模型的性能,而低质量的边界框通常会对训练产生负面影响,因为它会产生大量信息量较少且冗余的信号更新模型。
这里应用 t 值来衡量边界框的质量。因此,通过关注对齐良好的anchors(具有大的 t)来提高任务对齐和回归精度,同时减少边界框回归期间未对齐的anchors(具有小 t)的影响。与分类目标类似,根据 重新加权为每个anchors计算的边界框回归损失,GIoU 损失(LGIoU)可以重新表述如下:
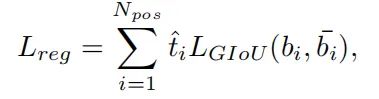
其中 b 和 表示预测的边界框和相应的GT框。
TAL 的总训练损失是 和 的总和。
3、YOLOv6、PP-YOLOE、PicoDet为什么都选择了TOOD?
SimOTA就是分配给每个Anchor更容易学习的GT(Cost更小的)。同时一个GT可以对应多个Anchor,具体数目则根据GT和各个Anchor的IoU情况而定;那么换个角度也就是说,对于一个GT,如果存在很多高质量(IoU大)的Anchor,则多分配一些Anchor负责预测该GT,反之,只有一些质量低(IoU小)的Anchor,则少分配一些Anchor负责预测该GT,从而实现“避免引入有害梯度”的目的。
可以看到SimOTA中所谓的高质量依旧是基于IOU来进行衡量得到的,通过IOU-Aware论文可以知道,单阶段目标检测的性能之所以低,是因为分类分数与定位精度之间的低相关性导致的,在提取Anchor之后,分类分支与定位分支时相互独立的,造成分类与定位间的不匹配。为了缓解这个问题,在IOU-Aware方法中添加了一个同步的IOU预测head,在训练时,IOU head与另外的分类和回归分支一起训练。而在推理时,Anchor的最终分数由分类置信度和预测IOU相乘所得,并用于最后的NMS和AP计算。这里的IOU-Aware我想也是启发作者制定Anchor-Alignment Metric思想来源,目的是获得更为精确合理的预测。
在VarifocalNet中作者对于IOU分支以及CenterNess分支的有效性也进行了实验,证明了这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。但是,VarifocalNet作者认为它们并不是最优解的,因为将两个不完善的预测相乘可能会导致排名依据变差,VarifocalNet作者也经过试验表明,通过这种方法实现的性能上限非常有限。此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。在VarifocalNet中并不采用预测一个额外的定位精确度得分(IOU-aware Centerness),而是将其合并到分类得分中。即预测一个可以同时代表目标存在和定位精度的定位感知或者IOU感知的分类得分(IoU-Aware Classification Score)。
结合TOOD可以看出,最优预测不仅应该具有较高的分类分数,还应该具有准确的定位,这意味着在训练中,分类头和回归头之间具有较高一致性的Anchor应该更为重要。但是相较于前面提到的算法,TOOD设计更为全面细节,其不仅仅是考虑到了任务对齐学习的问题,还精心设计了T-Head来在head端进行任务对其,同时还通过新的Metric设计了全新的Label Assignment策略,实为上上之选。
4、YOLOv6的姿势如何?
YOLOv6香不香应该就不用在这里强调了吧!重参+自蒸馏+感知量化+...各种Tricks大放异彩。你想要的都给你了!!!但是今天呢不会展开聊YOLOv6,这类只聊其Label Assignment。
前面也提到了YOLOv6最新开源的Label Assignment由原有的SimOTA升级为TOOD,通过前面的了解大家应该对于TOOD比较了解了,对于为什么使用它也应该比较熟悉了,这里就说说YOLOv6的姿势是什么样子的!
大家可能应该知道PP-YOLOE 改进了 T-head,将 T-head 中的 layer attention 替换为轻量级的 ESE attention,形成 ET-head。然而,YOLOv6的作者发现 ET-head 会降低模型中的推理速度,并且没有准确度增益。因此,保留了在YOLOv6之前版本中的高效解耦头的设计。
通过前面的讲解知道TOOD的分类损失其实就是改进的Focal Loss,只不过是把预测结果换成归一化的alignment metric 。
为了解决训练和推理之间质量估计和分类的不一致问题,Quality Focal Loss(QFL)进一步扩展了Focal Loss,联合表示分类分数和分类监督的定位质量。
我们应该知道在目标检测任务中,正样本比负样本要少得多(特别是在密集的目标检测任务中)。非对称地处理正样本和负样本的Varifocal Loss与同等地处理它们的Generalized Focal Loss不同。这意味着正样本的损失减少量与负样本的损失减少量并不相同。
而Varifocal Loss仅通过使用因子 pγ 缩放负样本 (q=0) 的损失来减少来自负样本 (q=0) 的损失贡献,并且不会以相同的方式降低正样本 (q>0) 的权重。这是因为正样本与负样本相比数量较少,应该保留它们宝贵的学习信号。另一方面,受 PISA 和 Iou-balanced loss 的启发,用训练目标 q 对正样本进行加权。如果一个正样本的 gt IoU 很高,那么它对损失的贡献就会比较大。这将训练重点放在那些高质量的正样本上,这些正样本对于获得更高的 AP 比那些低质量的正样本更重要。同时为了平衡正样本和负样本之间的损失,Varifocal Loss在负损失项中添加了一个可调整的比例因子 α。
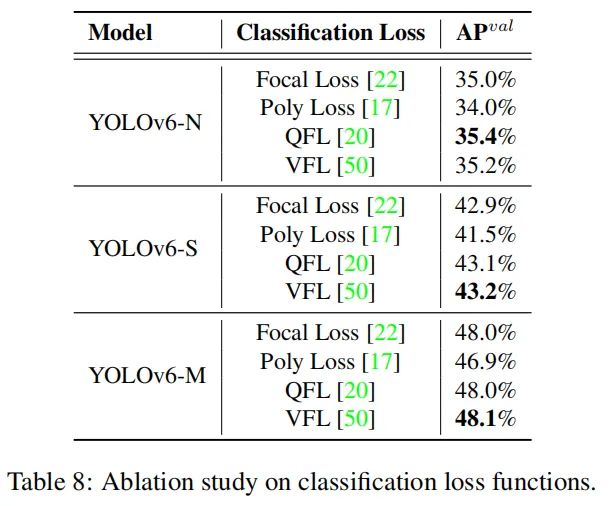
YOLOv6 上评估所有这些分类损失,最终采用 VFL。
那么说YOLOv6选择的就是最优秀的嘛?
前面提到的如果进行归类的话,就是将soft weights用于标签分配。GFL和VFL是两种典型的方法,它们基于IoU定义了Soft Labels目标,然后乘以一个调制因子将其变为loss权重。大家不觉得前面的种种都在设计正样本的权重函数,而一点不重视负样本嘛?
有没有再改进的余地了呢?
这里大家可以参考《A Dual Weighting Label Assignment Scheme for Object Detection》这个文章!
其他的Trick这里不再进行描述了,YOLOv6的文章里面说的比较明白了!