
百亿业务流量-如何做好稳定性监控

NO.1
前言
监控 -- 安全生产的第一战线,报警的有效覆盖率、线上问题的发现能力以及如何快速定位问题是监控的核心能力。
安全生产整体目标1-5-10,1 分钟发现问题、5 分钟定位问题、10 分钟修复问题。
JSTracker平台 — 打造端到端的前端监控与数据分析平台,提供实时监控、多端覆盖、数据分析、智能化的核心能力,并基于 JSTracker平台 来完成淘系双11的稳定性保障。
本篇文章将通过介绍我们是如何基于 JSTracker平台 建设 1-5-10整体解决方案以及如何保障淘宝直播、会场、店铺、互动、交易等多个核心业务的双11大促稳定性。
NO.2
现状
前端跨端方案不断在演进,在前端框架上,覆盖了web、weex、小程序等多种跨端方案场景,工程的基础设施逐渐成熟,但业务整体的故障发现率依然偏低。对FY18-FY20淘系前端故障做了统计分析,监控发现率均值低于30%, 整体平均修复时长远超过1个小时。现从问题发现、快速恢复来分析下具体原因:
问题发现
多数故障未及时发现,核心问题不是报警有效性的问题,大部分来自于被动通知,线上反馈、舆情或者客诉等,从问题分析来看存在以下几个问题:
业务未接入监控,安全意识缺乏以及基础设施并不完备,页面需要手动引入监控SDK,很多业务在线上完全处于裸奔状态
核心指标未订阅,多数页面引入了监控但是没有订阅报警或者指标订阅不完整,导致线上问题没有第一时间发现
监控指标不完整,从传统前端视角,可能只会关注页面运行时的异常,比如jserror、接口报错运行等,但是从页面整个运行过程来看,很多监控指标是缺失的,比如cdn节点异常、页面加载白屏、页面执行crash等问题
快速恢复
从故障平均恢复统计时长来看离目标10分钟快速恢复存在很大差距。一个完整的开发流程包含 :开发 -> 发布 -> 线上验证回归流程。流程如图所示:
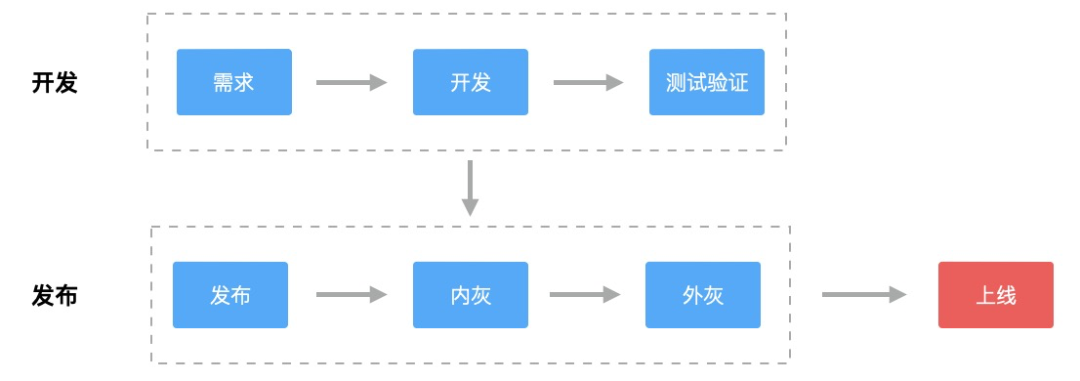
如果问题已经发布上线,按照发布流程很难做到10分钟恢复,对于问题的核心解法,需要聚焦到页面发布之前的开发阶段和发布阶段,主要涉及两点:
发布之前:完整的自动化测试流程,例如在发布之前对资源异常、JSError等做检测拦截
发布过程:页面发布过程具有可灰度、可监控、可回滚的完整过程
NO.3
整体方案
围绕着 1-5-10 安全生产整体目标,针对“问题发现、快速恢复”的问题解决方案如下:
监控覆盖
从故障问题来看,问题发现的核心问题是需要先解决监控覆盖率的问题,解决接入覆盖、订阅覆盖、指标覆盖的问题,保障业务100%接入和订阅以及页面的监控指标完整性,具体解决方案如下:
接入覆盖
我们需从两个维度来解决接入覆盖率的问题,完善基础设施和业务治理推动的角度
完善基础设施,前端页面主要分为两部分,源码和搭建(斑马、方舟)。在搭建层,我们在solution做了统一默认接入, 在源码层,目前 集团监控采集规范和数据规范标准还未统一,正在标准化统一的路上
业务治理推动,通过团队维度统计覆盖分布和指标情况,度量页面安全分, 引导和推动业务快速完成接入
在业务治理层,需要建立指标统计和业务度量方式,方案如下
指标统计
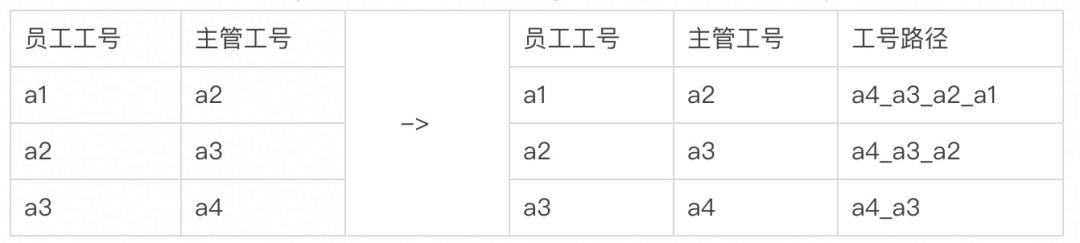
在度量开发过程当中,需要各种维度来统计指标数据,比如团队、时间等。如何高效的按汇报关系将数据进行汇总,是统计分析的核心问题,整体思路如下
构造人员工号的全路径字段(工号路径),可以通过path节点找到层级关系
获取某个主管下的列表,可以通过like快速查询,比如获取a3的所有员工, 如:工号路径 like '%a3%'
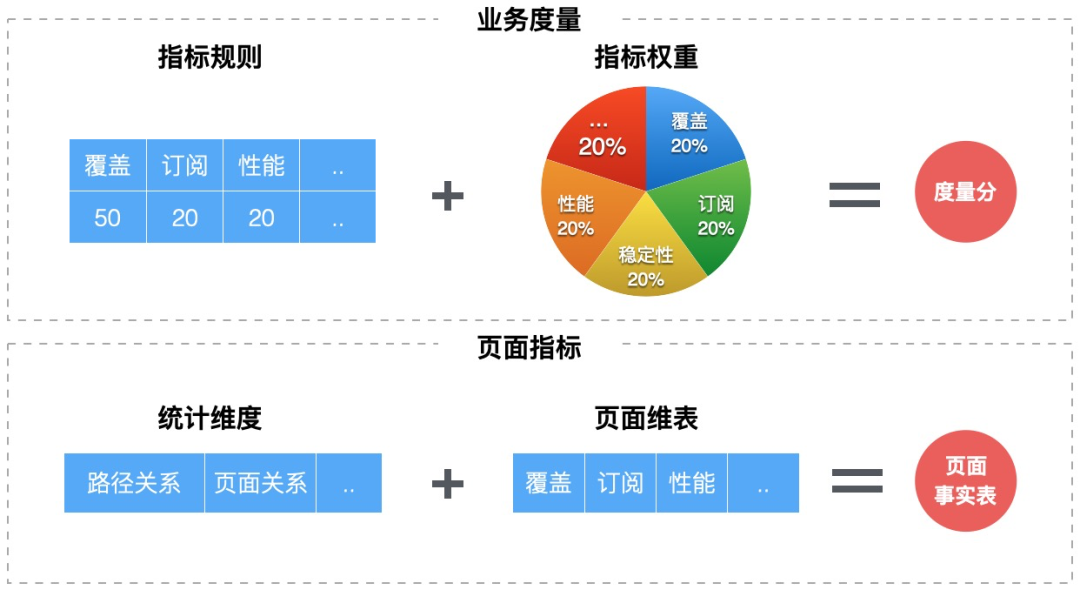
度量&红黑榜
度量目标帮助业务、团队做辅助决策,基于页面的原始数据,从原始数据 -> 数据分析 -> 指标度量 -> 业务决策 ,可建立一套指标度量模型,帮助业务快速发现问题
订阅覆盖
从统计数据可以看出, 很多页面主要是指标订阅不完整,比如只订阅了jserror,忽略白屏、crash等指标的订阅。在业务现状下,需要对未订阅的页面补齐订阅指标以及保障后续核心指标订阅,整体流程如下:
订阅指标补齐:通过治理流程,统计页面未订阅关系分布,走一键订阅指标补齐
完善发布流程:页面发布后,订阅发布消息,对核心指标做增量订阅
NO.3
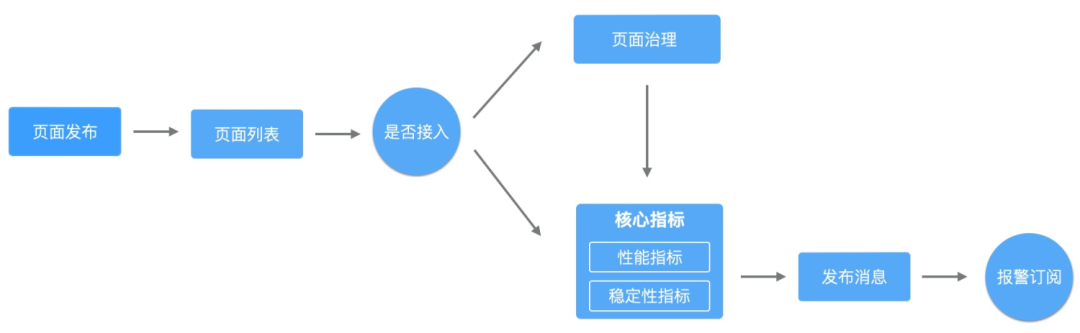
指标覆盖
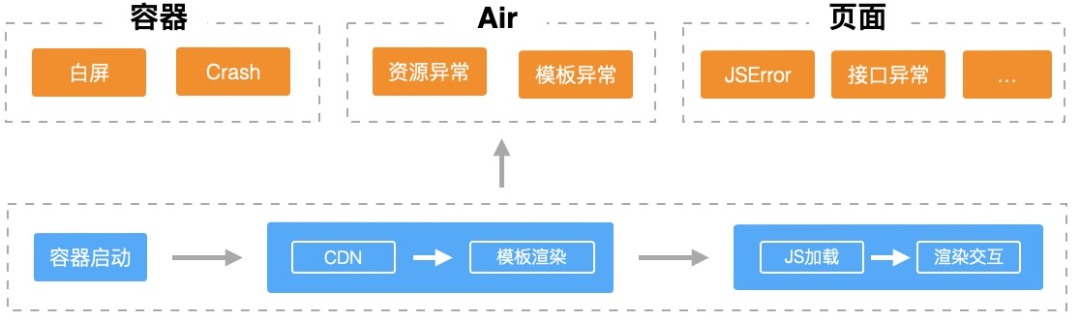
跨端页面,从整体的页面周期来看主要划分为三个过程,从容器启动 -> air渲染 -> 页面加载执行
容器层,比如weex、webview容器等,加载运行过程可以检测页面加载是否白屏、crash等
源站层,如果在cdn就出现异常,从前端的视角是无法感知的
页面层,依赖本身SDK的能力,全局捕捉过程异常点作为监控指标点
从安全视角来看,整个链路的稳定性都需要做到可监控。全链路保障过程,在数据链路层对数据指标过程做了统一接入,通过页面地址对齐指标
灰度监控
快速恢复的核心是需要更快发现问题,更快的对变更进行回滚。历史故障数据,80%左右的线上问题是由变更导致的。但很多故障不是缺少监控导致的,而是新的版本变更引起的问题在整体的错误量不明显,在整体日志层没有区分,导致看到的表面现像是正常的,而忽略了问题。
对于变更的过程的监控 【灰度监控】,需要标识异常的日志是新的版本带来的,用来对比线上版本的监控区分出新版本的错误比例增长以及新引发的问题,解决方案如下:
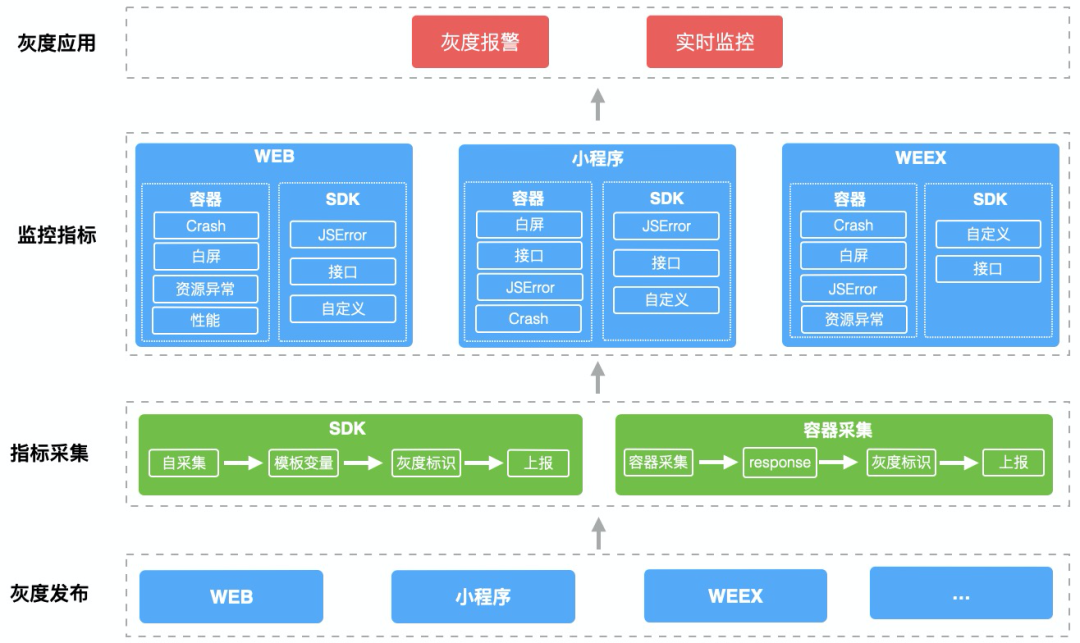
指标采集:采集脚本通过读取模板全局变量获取,容器层通过response header拿到灰度标识
监控指标:采集脚本和容器层需要统一和标准化灰度字段规范,在日志上报过程中携带,小程序通过版本号区分
灰度应用:主要表现在指标灰度实时日志呈现和报警
采集标准
主要分为两部分:字段规范和集成规范。字段规范主要针对不同的日志源,在数据链路上处理字段统一;集成规范是对于不同的跨端场景,用于页面识别灰度状态
字段规范

集成规范
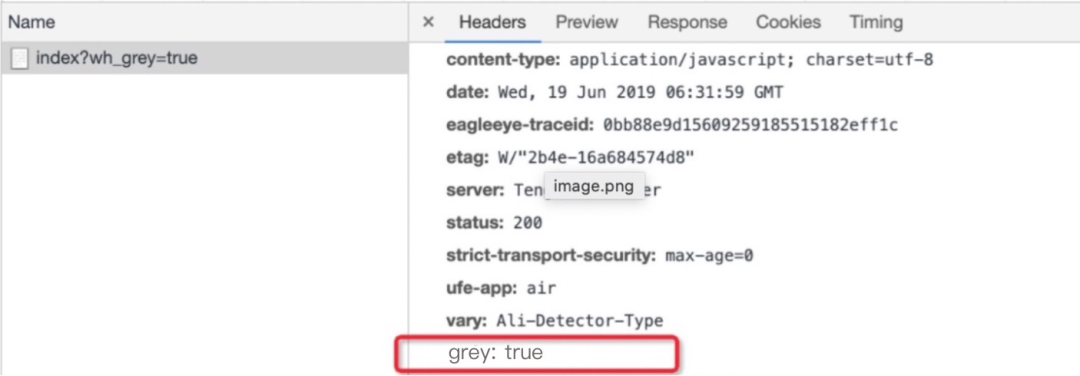
<meta name="page-tag" content="env=spe,grey=true,version=0.0.1" />采集方式
通过采集方式解决页面监控SDK以及跨端容器(weex、windvane等)获取发布版本的信息的问题,主要存在以下两个问题
监控SDK:受浏览器的限制,只能通过全局的方式读取,比如通过meta标签或者全局变量的方式
跨端容器:获取不到模板的内容,只能通过响应头的信息来获取到版本信息
基于上面问题,和前端发布约定下面两种标准的方式来通知端当前发布状态
集成到response headers内容里,headers里面写入版本号、灰度状态
直接在渲染层注入到页面模板内容,模板渲染的时候可以写入到全局参数中
具体方式
web sdk, 考虑全局变量存在一定污染,目前标准集成是通过meta标签的方式
"" content="{{$page.isGreyPage}}" />容器侧,直接读取到response内容,但是也存在弊端,依赖客户端发版迭代
灰度应用
从监控视角来看,一个新的版本迭代主要担心两点,会不会带来新的问题或错误率比例会不会变大。对于应用侧,需要让用户清晰的感知指标的变化情况,具体如下:
灰度监控报警
灰度报警链路如下图:
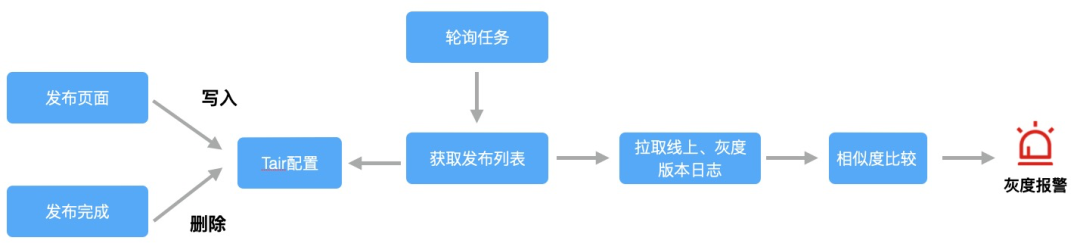
1、订阅页面的发布消息,存储或者删除页面发布的信息,比如页面地址、灰度比例、发布人等配置信息
2、灰度报警目前是通过5分钟进行一次轮询,灰度版本日志可以拉取最新30分钟,线上可以拉取12个小时日志,避免新增的日志误差比较大造成误差,在对日志进行diff比较,相似度 < 50% 判断为新增日志,效果如下:
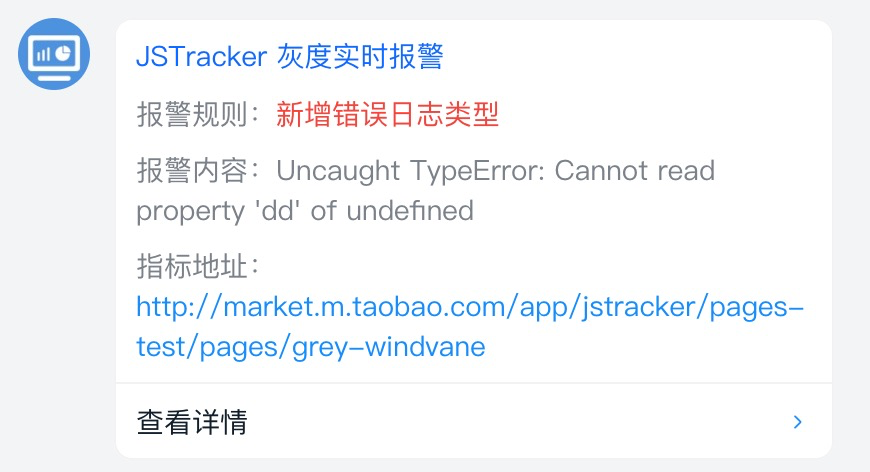
灰度实时监控
指标采集完整之后,在指标日志增加grey字段对灰度版本以及线上版本做日志区分,可以通过对比以下几点来判断灰度版本是否异常
灰度版本错误率和线上版本错误率的比例值
错误日志的趋势比例以及状态
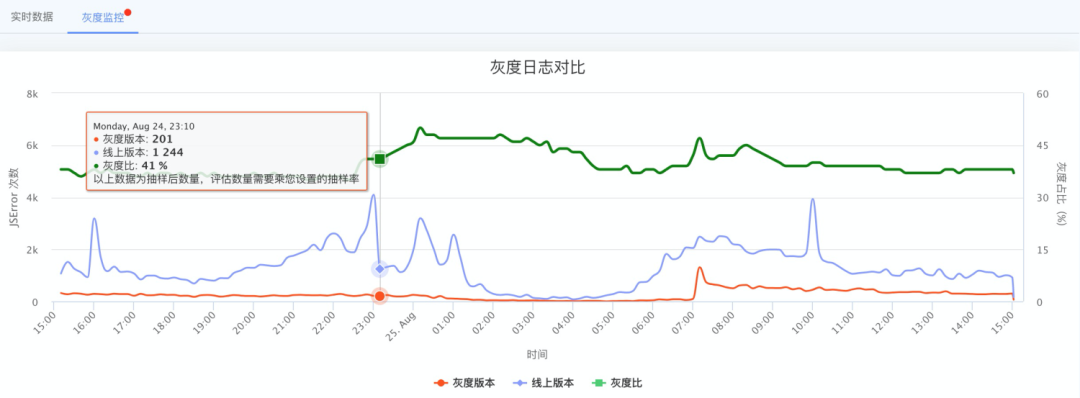
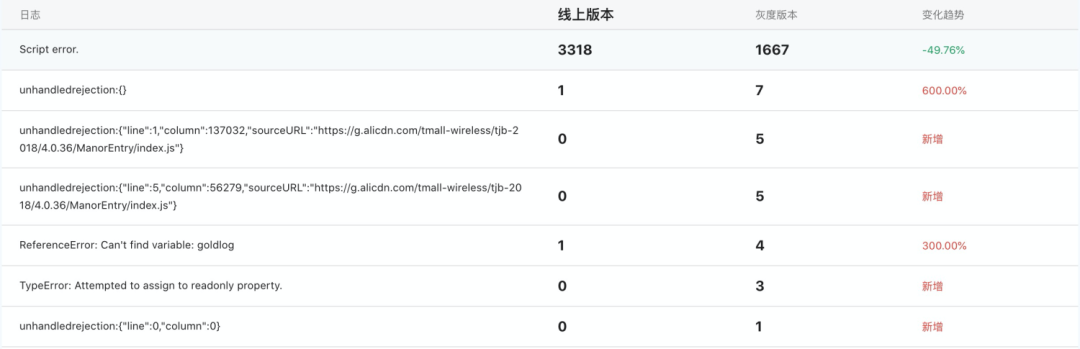
结果
目前淘系C端的页面监控覆盖率是98%, 包含源码页面、搭建页面以及小程序。以主会场监控为例,在预售、预热、正式阶段,直接定位到 10+ 处模块开发问题。
监控大屏
基于页面监控、指标覆盖率的完整前提下,通过datav搭建了淘系整体的监控大盘,可以全局观察核心页面的异常情况。
案例: 双11晚上,整体的weex错误日志上涨,通过日志排查是有个页面js执行错误的逻辑
指标覆盖
Crash日志 整体上涨,xx号客户端推送配置,Crash日志大量上涨,业务第一时间收到报警,及时止血
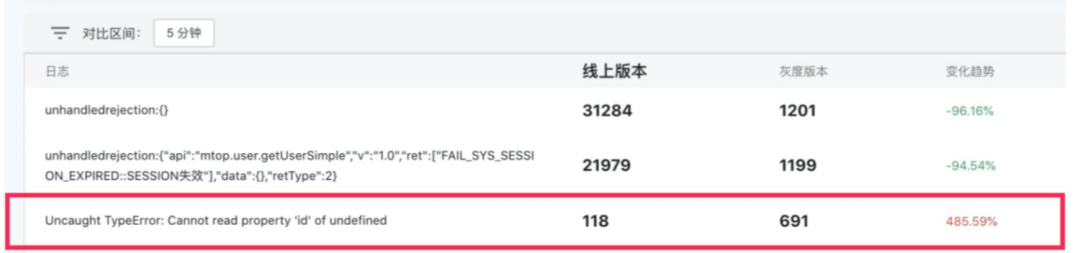
灰度监控
互动业务,新增功能迭代发布后,灰度报错异常比例增加,及时回滚避免了线上问题扩大
NO.4
总结
在监控覆盖、灰度监控等能力建设之下,我们有了更好规避问题和感知问题的能力,才能让业务走的更远、走的更快。目前在报警订阅、准确性、指标分析上仍然存在不少问题,后续我们会持续完善监控的能力,欢迎一起讨论交流。
欢迎关注东半球最大的前端团队
