
得物一面,稳扎稳打!
大家好,我是小林。
前几天刚跟大家分享了得物的校招开奖薪资。

很多同学就好奇得物的面试难度如何?其实都都大厂差不多,围绕八股+项目+算法这三个方面来考察。
这次分享之前同学得物Java 后端岗位一面的面试,面试感受不错,有的问题还跟面试官讨论起来。
Java
ArrayList 和 LinkedList 的区别是什么?(答上来了)
数据结构方面:
-
ArrayList:内部使用动态数组存储数据。因此,它支持随机访问,通过索引访问元素非常快,时间复杂度为O(1)。
-
LinkedList:内部使用双向链表存储数据。这使得在列表的开头或结尾插入、删除元素非常快,时间复杂度为O(1)。
性能方面:
-
ArrayList:添加元素时如果需要扩容(即当前数组已满),则需要复制原数组到新的更大的数组,这样的操作时间复杂度为O(n)。而对于非尾部的插入和删除操作,需要移动后面的所有元素,时间复杂度也是O(n)。
-
LinkedList:对于非首尾的插入和删除操作,需要从头部或尾部遍历到相应的位置,时间复杂度为O(n)。而访问元素(get和set操作)也需要从头部或尾部遍历到相应的位置,时间复杂度为O(n)。
ArrayList 的底层原理是什么?(答上来了)
ArrayList是Java中的动态数组,其底层原理是基于数组实现的。
具体来说,ArrayList内部使用一个Object类型的数组来存储元素。当我们向ArrayList中添加元素时,它会自动调整数组的大小以适应新的元素。当数组的容量不足以容纳新元素时,ArrayList会创建一个更大的数组,并将原数组中的元素复制到新数组中。
这种动态调整数组大小的策略可以确保ArrayList具有可变长度的特性,可以根据需要动态添加或删除元素,而无需手动管理数组的大小。
需要注意的是,由于ArrayList底层使用数组实现,所以在插入或删除元素时,需要将后续的元素进行移动,这可能会影响性能,特别是当ArrayList中的元素数量很大时。因此,在需要频繁进行插入和删除操作的场景下,可能需要考虑使用LinkedList等其他数据结构来替代ArrayList。
ArrayList 是线程安全的吗?( 答上来了)
ArrayList 不是线程安全的,在多线程环境下,如果多个线程同时对同一个ArrayList实例进行操作(如添加、删除、修改等),会导致数据不一致的问题。
为什么不是线程安全的,具体来说是哪里不安全?(源码层面,没答上来)
在高并发添加数据下,ArrayList会暴露三个问题;
-
部分值为null(我们并没有add null进去)
-
索引越界异常
-
size与我们add的数量不符
为了知道这三种情况是怎么发生的,ArrayList,add 增加元素的代码如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
ensureCapacityInternal()这个方法的详细代码我们可以暂时不看,它的作用就是判断如果将当前的新元素加到列表后面,列表的elementData数组的大小是否满足,如果size + 1的这个需求长度大于了elementData这个数组的长度,那么就要对这个数组进行扩容。
大体可以分为三步:
-
判断数组需不需要扩容,如果需要的话,调用grow方法进行扩容;
-
将数组的size位置设置值(因为数组的下标是从0开始的);
-
将当前集合的大小加1
下面我们来分析三种情况都是如何产生的:
-
部分值为null:当线程1走到了扩容那里发现当前size是9,而数组容量是10,所以不用扩容,这时候cpu让出执行权,线程2也进来了,发现size是9,而数组容量是10,所以不用扩容,这时候线程1继续执行,将数组下标索引为9的位置set值了,还没有来得及执行size++,这时候线程2也来执行了,又把数组下标索引为9的位置set了一遍,这时候两个先后进行size++,导致下标索引10的地方就为null了。
-
索引越界异常:线程1走到扩容那里发现当前size是9,数组容量是10不用扩容,cpu让出执行权,线程2也发现不用扩容,这时候数组的容量就是10,而线程1 set完之后size++,这时候线程2再进来size就是10,数组的大小只有10,而你要设置下标索引为10的就会越界(数组的下标索引从0开始);
-
size与我们add的数量不符:这个基本上每次都会发生,这个理解起来也很简单,因为size++本身就不是原子操作,可以分为三步:获取size的值,将size的值加1,将新的size值覆盖掉原来的,线程1和线程2拿到一样的size值加完了同时覆盖,就会导致一次没有加上,所以肯定不会与我们add的数量保持一致的;
ArrayList 和 LinkedList 的应用场景,什么时候该用哪个?(没答上来)
-
ArrayList适用于需要频繁访问集合元素的场景。它基于数组实现,可以通过索引快速访问元素,因此在按索引查找、遍历和随机访问元素的操作上具有较高的性能。当需要频繁访问和遍历集合元素,并且集合大小不经常改变时,推荐使用ArrayList
-
LinkedList适用于频繁进行插入和删除操作的场景。它基于链表实现,插入和删除元素的操作只需要调整节点的指针,因此在插入和删除操作上具有较高的性能。当需要频繁进行插入和删除操作,或者集合大小经常改变时,可以考虑使用LinkedList。
Redis
缓存雪崩、缓存击穿、缓存穿透是什么?(答上来了)
-
缓存雪崩:当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
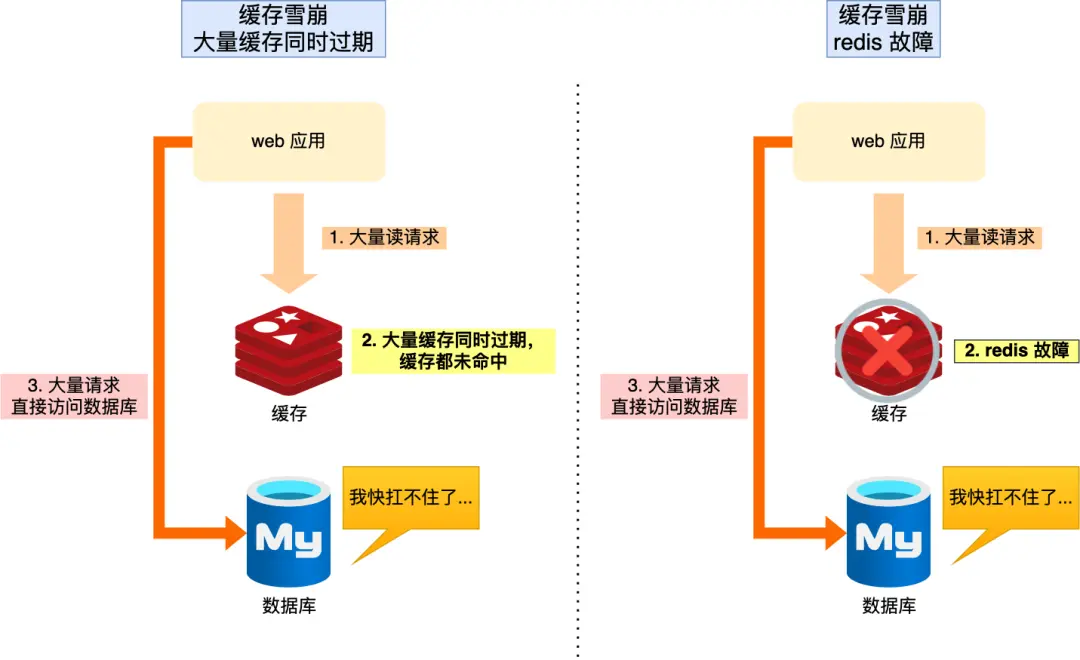
image.png
-
缓存击穿:如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
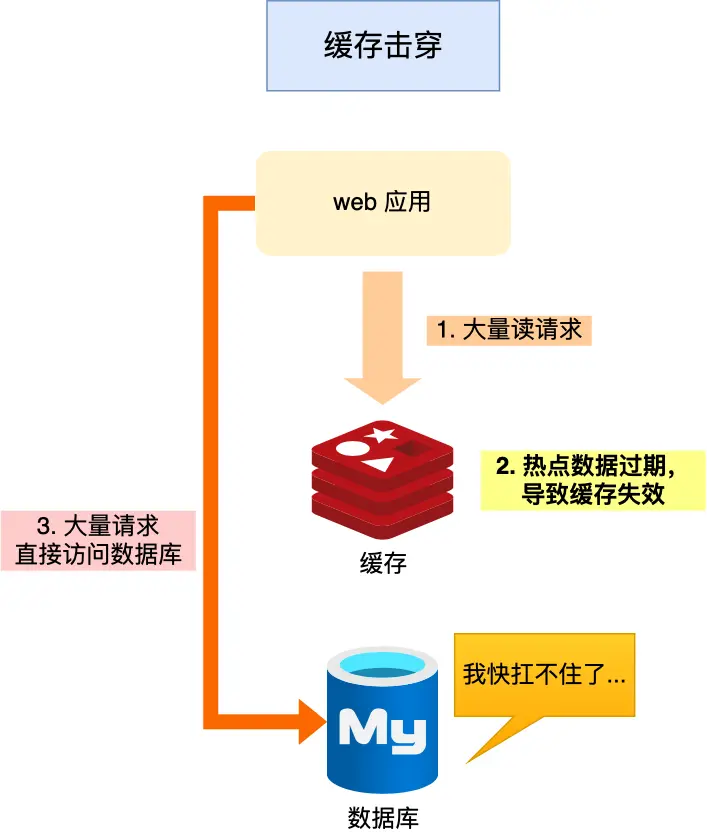
image.png
-
缓存穿透:当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
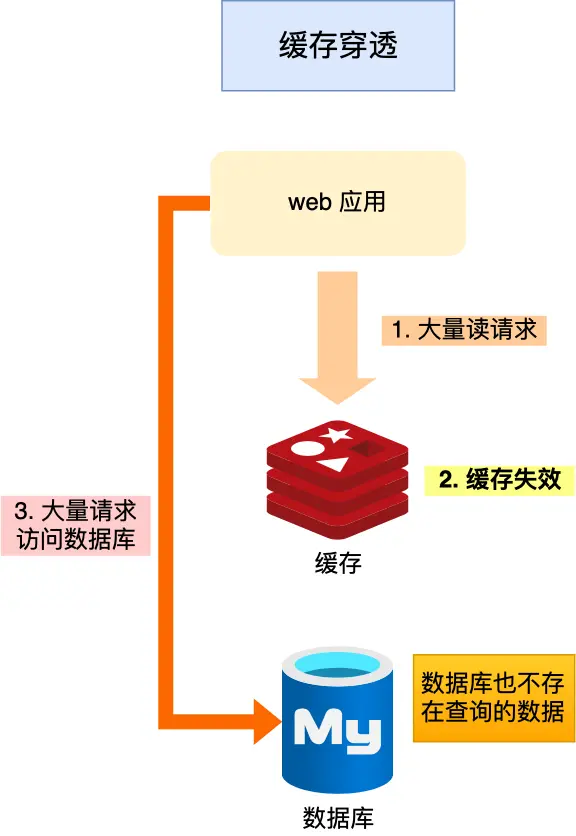
image.png
这些缓存问题,有什么解决方案吗?(答上来了)
缓存雪崩解决方案:
-
均匀设置过期时间:如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间。我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
-
互斥锁:当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
-
后台更新缓存:业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
缓存击穿解决方案:
-
互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
-
不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
缓存穿透解决方案:
-
非法请求的限制:当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
-
缓存空值或者默认值:当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
-
布隆过滤器:我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
网络协议
HTTP1.1怎么对请求做拆包,具体来说怎么拆的?( 八股没背过这,不知道)
在HTTP/1.1中,请求的拆包是通过"Content-Length"头字段来进行的。该字段指示了请求正文的长度,服务器可以根据该长度来正确接收和解析请求。

具体来说,当客户端发送一个HTTP请求时,会在请求头中添加"Content-Length"字段,该字段的值表示请求正文的字节数。
服务器在接收到请求后,会根据"Content-Length"字段的值来确定请求的长度,并从请求中读取相应数量的字节,直到读取完整个请求内容。
这种基于"Content-Length"字段的拆包机制可以确保服务器正确接收到完整的请求,避免了请求的丢失或截断问题。
讲讲TCP三次握手 (答上来了)

-
一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态
-
客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN 标志位置为 1,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
-
服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
-
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。
-
服务端收到客户端的应答报文后,也进入 ESTABLISHED 状态。
三次握手要实现什么目的?
面试官:同步序列号,保证数据不丢失。我说是建立连接,收发数据,面试官说你这个说的也没问题,另一个角度解释一下。补充:三个方面分析三次握手的原因:
-
三次握手才可以阻止重复历史连接的初始化(主要原因)
-
三次握手才可以同步双方的初始序列号
-
三次握手才可以避免资源浪费
第一个原因:避免历史连接
简单来说,三次握手的首要原因是为了防止旧的重复连接初始化造成混乱。我们考虑一个场景,客户端先发送了 SYN(seq = 90)报文,然后客户端宕机了,而且这个 SYN 报文还被网络阻塞了,服务端并没有收到,接着客户端重启后,又重新向服务端建立连接,发送了 SYN(seq = 100)报文(注意!不是重传 SYN,重传的 SYN 的序列号是一样的)。
看看三次握手是如何阻止历史连接的:
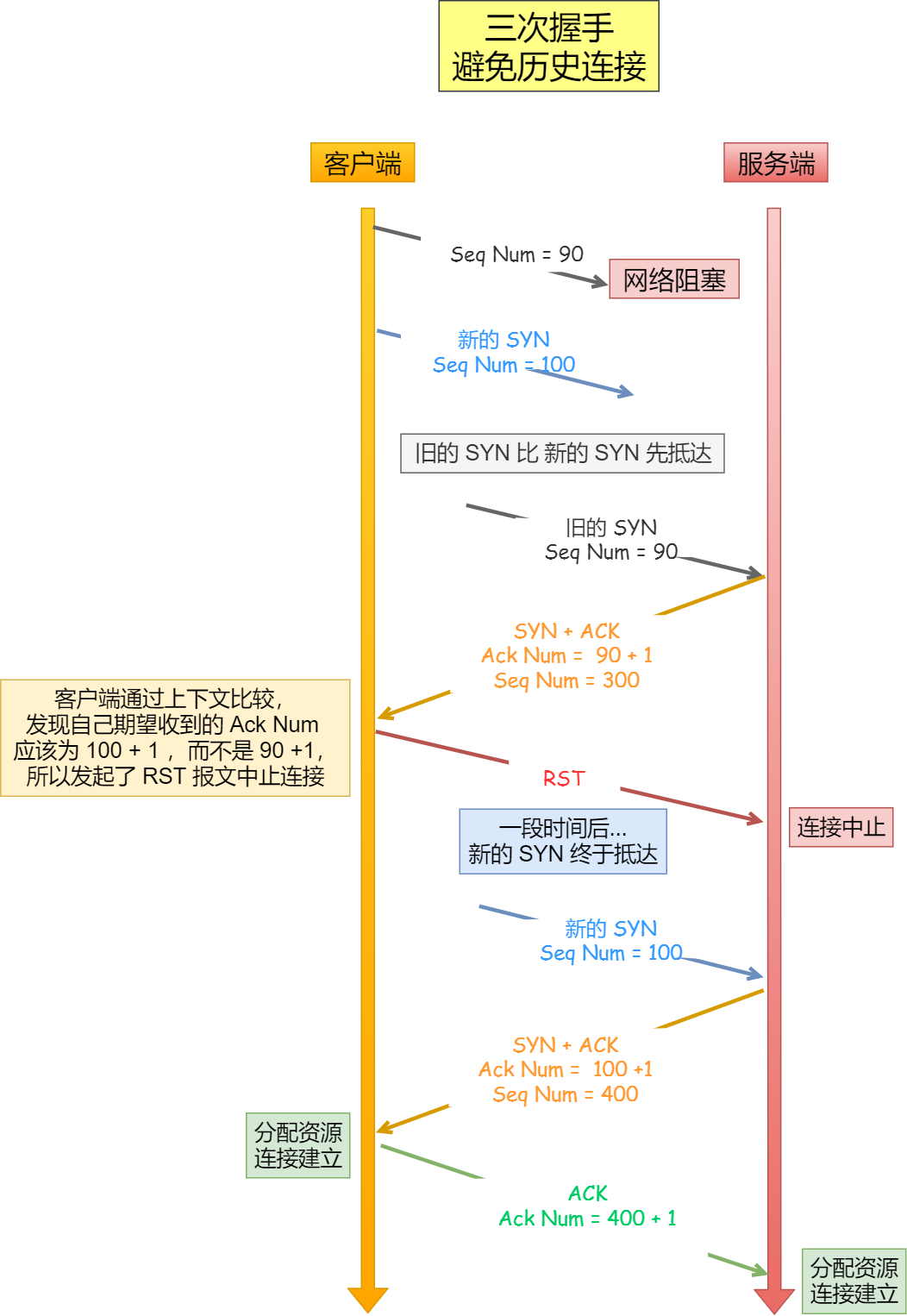
客户端连续发送多次 SYN(都是同一个四元组)建立连接的报文,在网络拥堵情况下:
-
一个「旧 SYN 报文」比「最新的 SYN」 报文早到达了服务端,那么此时服务端就会回一个 SYN + ACK 报文给客户端,此报文中的确认号是 91(90+1)。
-
客户端收到后,发现自己期望收到的确认号应该是 100 + 1,而不是 90 + 1,于是就会回 RST 报文。
-
服务端收到 RST 报文后,就会释放连接。
-
后续最新的 SYN 抵达了服务端后,客户端与服务端就可以正常的完成三次握手了。
上述中的「旧 SYN 报文」称为历史连接,TCP 使用三次握手建立连接的最主要原因就是防止「历史连接」初始化了连接。
第二个原因:同步双方初始序列号
TCP 协议的通信双方, 都必须维护一个「序列号」, 序列号是可靠传输的一个关键因素,它的作用:
-
接收方可以去除重复的数据;
-
接收方可以根据数据包的序列号按序接收;
-
可以标识发送出去的数据包中, 哪些是已经被对方收到的(通过 ACK 报文中的序列号知道);
可见,序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 SYN 报文的时候,需要服务端回一个 ACK 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步。
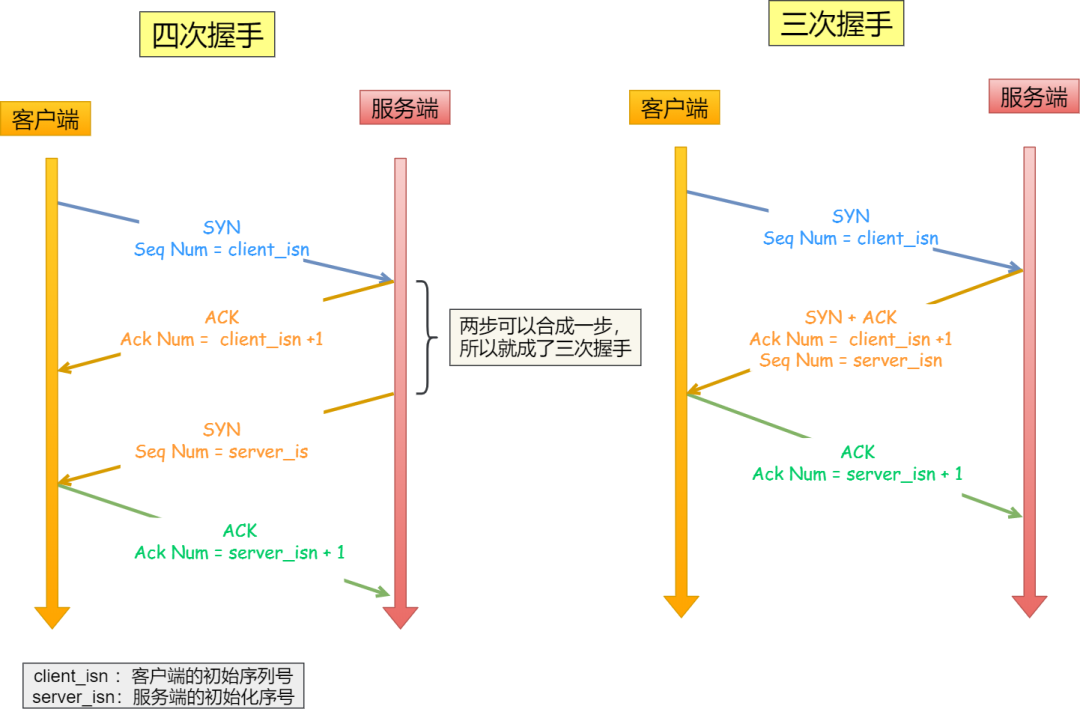
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。而两次握手只保证了一方的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
原因三:避免资源浪费
如果只有「两次握手」,当客户端发生的 SYN 报文在网络中阻塞,客户端没有接收到 ACK 报文,就会重新发送 SYN ,由于没有第三次握手,服务端不清楚客户端是否收到了自己回复的 ACK 报文,所以服务端每收到一个 SYN 就只能先主动建立一个连接,这会造成什么情况呢?如果客户端发送的 SYN 报文在网络中阻塞了,重复发送多次 SYN 报文,那么服务端在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。
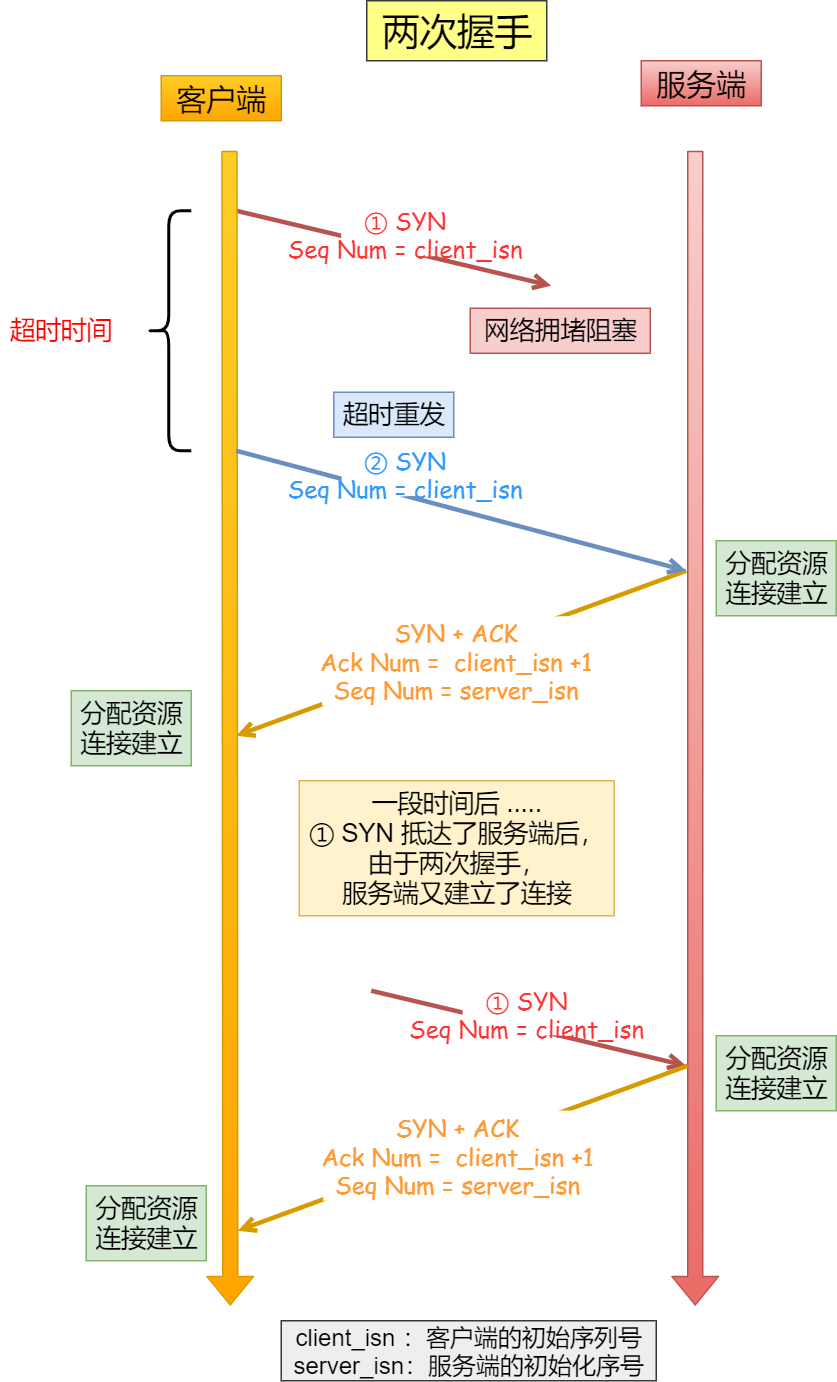 即两次握手会造成消息滞留情况下,服务端重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
即两次握手会造成消息滞留情况下,服务端重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
项目
JWT 令牌和传统方式有什么区别?(答上来了)
-
无状态性:JWT是无状态的令牌,不需要在服务器端存储会话信息。相反,JWT令牌中包含了所有必要的信息,如用户身份、权限等。这使得JWT在分布式系统中更加适用,可以方便地进行扩展和跨域访问。
-
安全性:JWT使用密钥对令牌进行签名,确保令牌的完整性和真实性。只有持有正确密钥的服务器才能对令牌进行验证和解析。这种方式比传统的基于会话和Cookie的验证更加安全,有效防止了CSRF(跨站请求伪造)等攻击。
-
跨域支持:JWT令牌可以在不同域之间传递,适用于跨域访问的场景。通过在请求的头部或参数中携带JWT令牌,可以实现无需Cookie的跨域身份验证。
JWT 令牌为什么能解决集群部署,什么是集群部署?( 答上来了)
在传统的基于会话和Cookie的身份验证方式中,会话信息通常存储在服务器的内存或数据库中。但在集群部署中,不同服务器之间没有共享的会话信息,这会导致用户在不同服务器之间切换时需要重新登录,或者需要引入额外的共享机制(如Redis),增加了复杂性和性能开销。
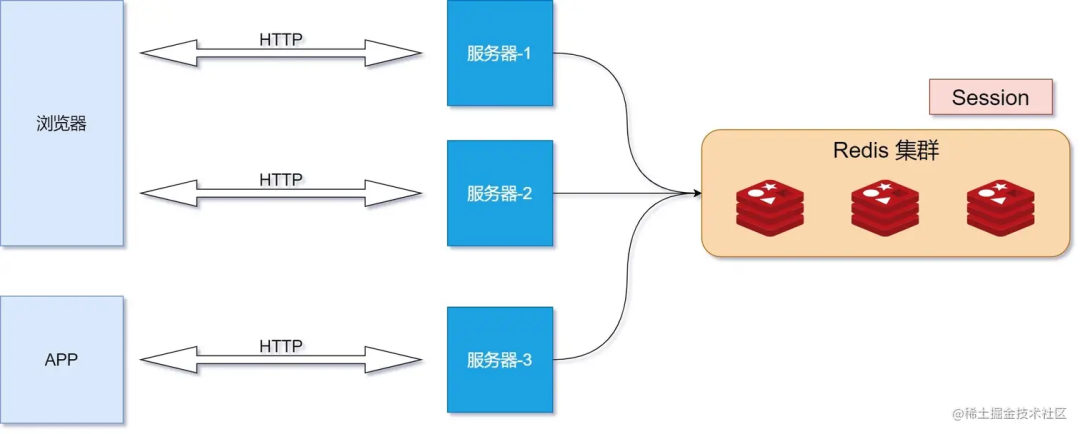
image.png
而JWT令牌通过在令牌中包含所有必要的身份验证和会话信息,使得服务器无需存储会话信息,从而解决了集群部署中的身份验证和会话管理问题。当用户进行登录认证后,服务器将生成一个JWT令牌并返回给客户端。客户端在后续的请求中携带该令牌,服务器可以通过对令牌进行验证和解析来获取用户身份和权限信息,而无需访问共享的会话存储。
由于JWT令牌是自包含的,服务器可以独立地对令牌进行验证,而不需要依赖其他服务器或共享存储。这使得集群中的每个服务器都可以独立处理请求,提高了系统的可伸缩性和容错性。
JWT 令牌都有哪些字段?( 没答上来,忘了有哪些,没想到会问)
JWT令牌由三个部分组成:头部(Header)、载荷(Payload)和签名(Signature)。其中,头部和载荷均为JSON格式,使用Base64编码进行序列化,而签名部分是对头部、载荷和密钥进行签名后的结果。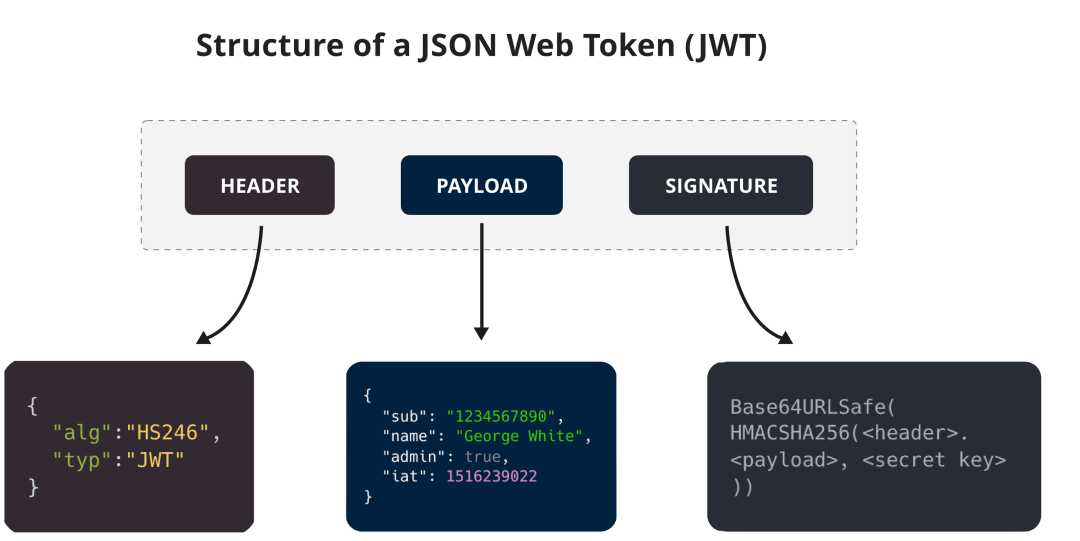
JWT 令牌如果泄露了,怎么解决,JWT是怎么做的?
-
及时失效令牌:当检测到JWT令牌泄露或存在风险时,可以立即将令牌标记为失效状态。服务器在接收到带有失效标记的令牌时,会拒绝对其进行任何操作,从而保护用户的身份和数据安全。
-
刷新令牌:JWT令牌通常具有一定的有效期,过期后需要重新获取新的令牌。当检测到令牌泄露时,可以主动刷新令牌,即重新生成一个新的令牌,并将旧令牌标记为失效状态。这样,即使泄露的令牌被恶意使用,也会很快失效,减少了被攻击者滥用的风险。
-
使用黑名单:服务器可以维护一个令牌的黑名单,将泄露的令牌添加到黑名单中。在接收到令牌时,先检查令牌是否在黑名单中,如果在则拒绝操作。这种方法需要服务器维护黑名单的状态,对性能有一定的影响,但可以有效地保护泄露的令牌不被滥用。
网关统一鉴权怎么做的?
答上来了,把流程说一遍就行了(2次算法,时间戳,随机数)
你这个SHA256算法不算加密吧?算签名吧?
完了晕菜了,一直背的用SHA256算法对secretKey加密,没思考过
补充:签名是需要用秘钥和原始数据(或者SHA256 后的数据)一起用加密算法生成的
你说说加密和签名有什么区别?
追问立马就来了,跳进大坑,回答不知道
补充:
-
加密是为了保护数据,通常对应解密;而签名是将数据和私钥一起用加密算法得到,用于验证数据的来源和完整性,确保数据传输过程中未被修改。
-
加密要用公钥私钥(对称秘钥),但签名验证可以只用公钥
那如果别人伪造你的签名,你怎么解决?
我说每个用户都有唯一的32位secretKey,没办法伪造
补充:
-
伪造签名的解决方法:伪造签名是一种安全漏洞,可能导致恶意行为。为了防止伪造签名,可以采取以下措施:
-
使用安全的密钥管理:确保私钥用于签名的安全存储和管理,以防止未经授权的访问。使用硬件安全模块(HSM)等工具来保护私钥。
-
使用公开密钥基础设施(PKI):PKI提供了一种建立信任关系的方式,可以确保公钥的有效性。公钥的合法性可以通过证书颁发机构(CA)进行验证。
-
使用数字证书:数字证书是包含公钥和身份信息的数字文件,用于验证签名的合法性。使用数字证书来验证签名可以提高安全性。
-
保护通信渠道:确保数据在传输过程中受到适当的加密和安全措施的保护,以防止中间人攻击。
-
定期更换密钥:定期更换用于签名的密钥,以降低长期存在的密钥被滥用的风险。
最后
反问
我:表现怎么样,还有什么地方需要进一步学习?
面试官:表现不错,问你的也都答上来了,毕竟也是学生,了解的也没那么深,工作中慢慢的了解的就深了,我当年也是什么都不懂,没事儿。
面试感受
都这么烂了,面试官还说不错,面试官人真不错,全程微笑,一起讨论,还主动跟我说我敲字是帮你记录,不是不认真听哈,一开始没答上来,下一个问题告诉我别紧张哈,别受到刚才那个题的影响
历史好文: