
如何根据系统的业务场景需求定制自己的线程池?
【本文由于内容相对比较严肃,因此基本上没有怎么大白话,这是因为笔者在写作的时候已经厌倦了所谓的大白话写作。希望读者理解】
前面的章节中我们已经对线程池的作用、优势、原理都做了细致的学习和了解。但还是不免有疑问,线程池有那么多的参数和类型,在实际的开发中,我们应该如何设置这些参数呢?是直接使用Executors提供的线程池实现还是自定义线程池?这都是我们本节要回答的问题,那么就请跟随笔者一起来研究一下在实战中如何根据系统的业务场景需求来定制自己的线程池吧。
一般情况下,其实Executors提供的几种实现已经足够我们使用了,比如:newCachedThreadPool()、newFixedThreadPool()以及newSingleThreadExecutor()。
如图1流程图所示,我将不同的业务场景适合的线程池类型画了出来。
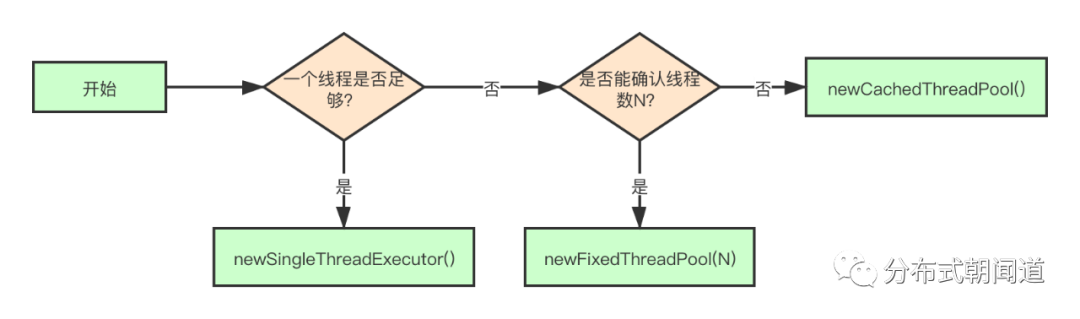
图1
如果在业务场景中使用一个线程就足够了,那么直接选择拥有一个核心工作线程的newSingleThreadExecutor()就能满足要求;
如果一个线程不够,但是能够判断线程数量是有限的,那么只需要指定工作线程数量N,通过newFixedThreadPool(N)就能够满足要求;
如果需要通过创建线程来应对一定程度的突发流量,保证任务处理的即时性,那么使用newCachedThreadPool()也是比较合理的。需要注意的是,如果突发流量很大,比如每秒上万的突增流量,那么使用newCachedThreadPool()就需要慎重,因为会导致出现java.lang.OutOfMemoryError异常。
需要注意的是,我们这里提到的newSingleThreadExecutor()以及newFixedThreadPool(N)线程池,使用的都是LinkedBlockingQueue无界队列。如果业务场景不适合使用无界队列,比如:任务携带的数据过多,且任务并发量大,那么使用基于LinkedBlockingQueue无界队列的线程池就需要慎重。
也就是说,Executors提供的默认线程池也是特定场景下才适用,并不是万能药。
那么问题来了,生产中应当如何使用线程池才比较合理呢?答案很简单,就是自定义线程池。
自定义线程池,其实就是根据自己业务场景,使用不同的参数去对线程池进行定制,从而满足具体的业务场景。
定制线程池的要点,其实就是ThreadPoolExecutor的核心构造参数的指定,主要在于指定合理的核心线程数、最大线程数、选择合适的工作队列、自定义线程工厂以及选择合适的拒绝策略。我们针对每个参数具体讨论一下。
指定线程数量
线程数量并没有一个标准答案,它主要依赖机器的CPU个数以及JVM虚拟机堆的大小,一般情况下,CPU个数是更加主要的影响因素。
实际生产中,我们根据任务关注点的不同,将任务划分为:CPU密集型(或者叫计算密集型)、I/O密集型两大类,如图2所示。也有一种叫做混合类型的任务,也就是既包含计算又包含I/O操作,不是我们讨论的重点因此不单独讨论。感兴趣的兄弟可以自己去单独了解。
图2
一般来说,对于CPU密集型的任务,由于CPU计算速度很快,任务在短时间内就能够通过CPU超强的计算能力执行完成,因此我们可以设置核心线程数corePoolSize为N(CPU个数)+1,之所以要设置为CPU个数加1,主要原因在于为了防止某些情况下出现等待情况导致没有线程可用,比如说发生了缺页中断时,就会出现等待的情况。因此设置一个额外的线程,可以保证继续使用CPU时间片。
而对于I/O密集型的任务,我们可以为最大线程数多设置一些线程。原因在于相比CPU密集型任务,I/O密集型任务在执行过程中由于等待I/O结果花费的时间要明显大于CPU计算所花费的时间,而且我们都知道,处于I/O等待状态的线程并不会消耗CPU资源,因此可以多设置一些线程。一般情况下,我们将其设置为CPU个数的倍数,常见的玩儿法是设置为N(CPU个数)*2。
对于I/O密集型任务,我们还要注意核心线程数不用设置的很大,原因在于I/O操作本身会导致上下文切换的发生,尤其是阻塞式I/O。因此建议将I/O密集型的核心线程数corePoolSize限制为1,最大线程数maximumPoolSize设置为N(CPU个数)*2。当线程池中只要一个线程的时候,能够很从容的应对提交的任务,此时的上下文切换相当少。然后随着任务逐渐增加,再慢慢的增加线程数量至最大线程数。这样做既不浪费资源,还很灵活的支持了任务增加的场景。
需要注意的是我们这里给出的是一种理论的参考配置,实际开发中,由于对性能的要求以及机器配置的不同,我们不能太过于死板教条的照搬文中的配置,还是需要根据具体的情况进行合适的调整,比如考虑CPU的利用率,任务执行过程中的等待时间等。但是一般来说,使用我们提到的配置是一种比较稳妥合适的方式。关于如何计算合理的线程池大小其实是有一个公式的,这里贴一下公式的内容,公式背后的深层次的原理就留给大家去探索学习,公式内容如图3所示。

图3
在Java中,通过Runtime.getRuntime().availableProcessors()就可以很方便的获取到JVM所在机器的CPU个数,从而方便我们指定具体的线程个数。
选择合适的工作队列
我们接着来看一下如何选择合适的工作队列。
工作队列通常有无界队列、有界队列、同步队列三种类型。每个队列都有它自己的特点和用途,按照惯例还是用一张图来说明,如图4所示。
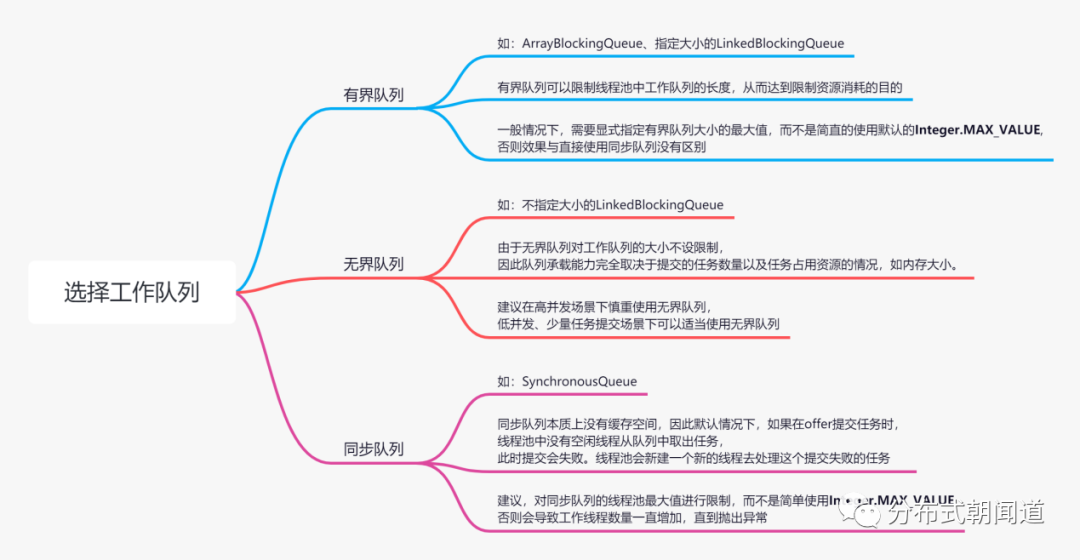
图4
在图4中,我们将每种工作队列的特点,代表的实现,以及使用的注意点都做了详细说明,大家可以认真阅读图中的内容,我们就不再赘述了。
自定义线程工厂
一般来说,我们还需要定义线程工厂,给自定义的线程池起一个个性化的名字,这有助于我们在查找日志的时候精确的定位到具体的某个线程池。
自定义线程工厂,需要实现ThreadFactory接口,此处提供一个参考实现,如图5所示,大家可以根据这个代码样例进行扩展,实现自己的线程工厂,当然也建议大家多去阅读优秀的开源框架,比如Netty、Tomcat,它们都提供了优秀的自定义的线程工厂的实现。
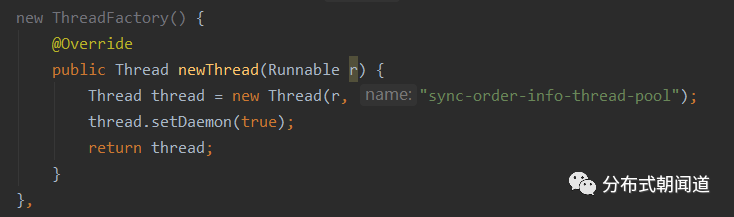
图5
选择合适的拒绝策略
我们接着聊聊如何选择合适的拒绝策略,关于ThreadPoolExecutor默认的拒绝策略及其特点,我们可以参考图6。
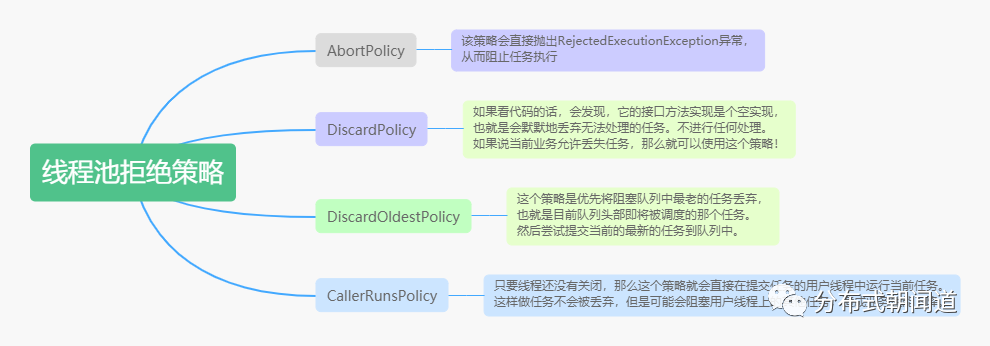
图6
一般来说,直接使用AbortPolicy抛出异常即可,但是如果说我们要求即便触发了拒绝策略,任务也得执行完成不能丢弃,那么选择CallerRunsPolicy拒绝策略即可。如果说这几种拒绝策略都满足不了我们的需求的话,就可以自定义拒绝策略,只需要实现RejectedExecutionHandler接口即可实现自定义的拒绝策略。
自定义线程池代码案例
上文中,我们对自定义线程池中需要注意的要点都进行了详细的图文并茂的讲解,相信你已经有所收获。这个部分我们就趁热打铁,编写一个完整的自定义线程池的案例。
我们以I/O密集型任务为例,实现一个自定义线程池的案例,具体代码如图7所示。
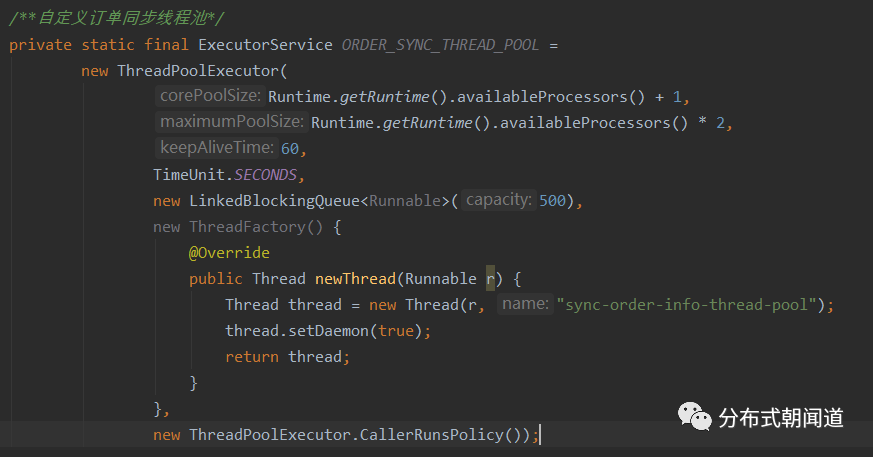
图7
我们定义了一个订单同步线程池,指定核心线程数为CPU数量+1,最大线程数为CPU数量*2,并指定非核心线程数的存活时间为60s。
我们使用了有界的LinkedBlockingQueue作为工作队列,指定大小为500,这个参数可以根据实际情况自定义,比如通过配置文件动态指定。
同时还定义了自定义的线程工厂,为线程池设置了名称“sync-order-info-thread-pool”,便于方便查询日志。最后指定了拒绝策略为CallerRunsPolicy(),保证只要JVM进程正常运行,任务一定能够被执行到。
我们只需要编写一个方法,将该自定义的线程池的引用返回,就可以让业务逻辑在需要的场景随时使用该自定义线程池了。实际开发中,我们更多的会用到Spring框架进行代码编写,我们只需要定义一个ThreadPoolExecutor的bean,即可在需要使用的地方进行注入,进而使用其进行异步任务提交等操作了,如图8所示。
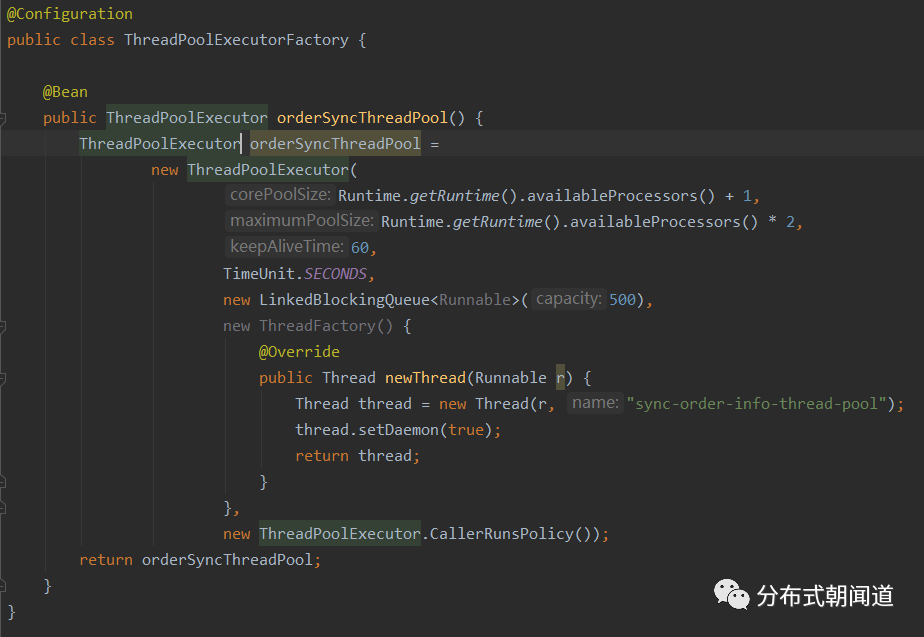
图8
本节,我们重点讨论了如何根据系统的实际业务是需求自定义线程池,在接下来的文章中,我们将通过线程池来实现互联网场景下的验证码保护服务,敬请期待。