
又是入刑的一天!抓取 jk 小姐姐图片
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
文 | 某某白米饭
来源:Python教授「ID: justpython」

在网上搜小姐姐照片养养眼的时候发现了半次元这个网站,这里面有 cos、jk、绘图等板块,觉得不错,就用爬虫下载下来了。
获取列表数据
从搜索框中搜索 jk,进入 jk 页面。
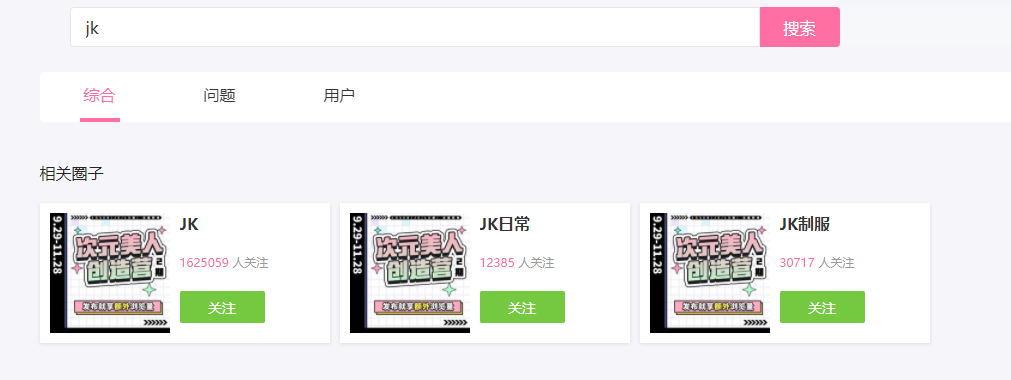
选择关注人数最多的点进去。
要获取 url 地址就得打开 F12 控制面板,找到一条 https://bcy.net/apiv3/common/circleFeed?circle_id=492&since=0&sort_type=2&grid_type=10 看它的数据集包含了 uid、昵称、头像等数据。再加上进入详情页面的 item_id。这个链接就是获取最新的 jk 列表的地址。
import requests
import time
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
def get_list():
try:
url = 'https://bcy.net/apiv3/common/circleFeed?circle_id=492&since='+str(int(time.time()))+'.000000&sort_type=2&grid_type=10'
response = requests.get(url,headers= header)
response.raise_for_status()
#转码
response.encoding = 'utf-8'
print(response.text)
except:
print("Failed!")
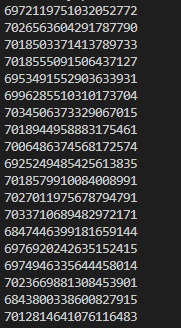
提取返回值里面的 item_id 就很简单,它就是个 json 串。
def parse_list(data):
item_ids = []
json_data = json.loads(data)
for item in json_data['data']['items']:
item_ids.append(item['item_detail']['item_id'])
return item_ids
示例结果:
获取 jk 图
从上面获取到 item_id 后,将它拼入到 https://bcy.net/item/detail/{item_id}?_source_page=hashtag 中。在 F12 中的结果集不是 json 串,而是一个页面。搜索发现 jk 图片的数据在 javascript 中。

用截取字符串的方式将数据提取出来,最后将 jk 图下载下来慢慢看。
import re
def get_item(item_ids):
intercepts = []
for id in item_ids:
url = 'https://bcy.net/item/detail/'+ str(id) + '?_source_page=hashtag'
response = requests.get(url, headers = header)
response.encoding = 'utf-8'
text = response.text
intercept = text[text.index('JSON.parse("') + len('JSON.parse("'): text.index('");')].replace(r'\"',r'"')
intercepts.append(intercept)
return intercepts
def download(intercepts):
for i in intercepts:
pattern = re.compile('"multi":\[{"path":"(.*?)","type"')
pattern_item_id = re.compile('"post_data":{"item_id":"(.*?)","uid"')
b = pattern.findall(i)
item_id = pattern_item_id.findall(i)[0]
index = 0
for url in b:
index = index + 1
content = re.sub(r'(\\u[a-zA-Z0-9]{4})',lambda x:x.group(1).encode("utf-8").decode("unicode-escape"),url)
response = requests.get(content.replace('\\',''))
with open('D:\\bcy\\' + str(item_id) + str(index) + '.png', 'wb') as f:
f.write(response.content)
最后在提取图片的url 的时候没有使用 json 串是因为,它的json串中有特殊的字符,有些转换不了。
总结
爬虫千万条,安全最重要。
推荐阅读
评论