
盘点一道使用pandas.groupby函数实战的应用题目
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是我是Python进阶者。
一、前言
前几天Python青铜群有个叫【假装新手】的粉丝问了一个数据分析的问题,这里拿出来给大家分享下。
 一开始以为只是一个简单的去重问题而已,【编程数学钟老师】大佬提出使用set函数,后来有粉丝发现其实没有想的这么简单。目前粉丝就需要编号,然后把重复的编号删除,但是需要保留前边的审批意见。这么来看,使用set集合的办不到了。
一开始以为只是一个简单的去重问题而已,【编程数学钟老师】大佬提出使用set函数,后来有粉丝发现其实没有想的这么简单。目前粉丝就需要编号,然后把重复的编号删除,但是需要保留前边的审批意见。这么来看,使用set集合的办不到了。
二、实现过程
这里给出两个解决方法,一起来看看吧。
方法一
这个方法来自【🌑(这是月亮的背面)】大佬提供的方法,使用pandas中的groupby函数巧妙解决,非常奈斯!
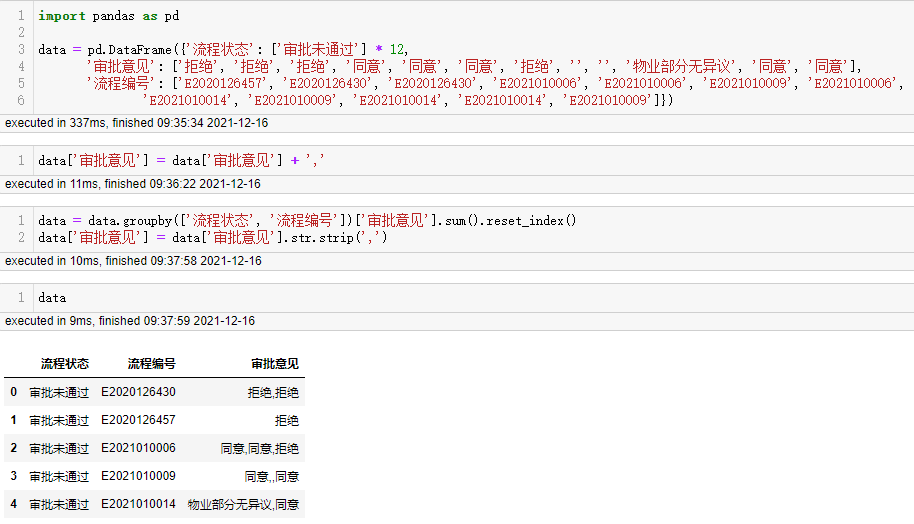 下面给出了一个优化代码,因为原始数据有空白单元格,如下图所示:
下面给出了一个优化代码,因为原始数据有空白单元格,如下图所示:

所以需要额外替换下,代码如下:
data['审批意见'] = data['审批意见'] + ','
data = data.groupby(['流程状态', '流程编号'])['审批意见'].sum().reset_index()
data['审批意见'] = data['审批意见'].str.strip(',').str.replace(',+', ',', regex=True)
方法二
这个方法来自【Oui】大佬提供的方法,这个没有考虑处理的数据列中有空白的情况,但是确实是个好思路,

总结
大家好,我是Python进阶者。这篇文章基于粉丝提问,在实际工作中运用Python工具实现了数据批量分组的问题,在实现过程中,巧妙的运用了pandas.groupby()函数,顺利的帮助粉丝解决了问题,加深了对该函数的认识。

最后感谢粉丝【假装新手】提问,感谢【🌑(这是月亮的背面)】大佬和【Oui】大佬给予的思路和代码支持。
文中针对该问题,给出了两个方法,小编相信肯定还有其他的方法,欢迎大家积极尝试。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~