
结合 React 源码,五分钟带你掌握优先队列
什么是优先队列
优先队列是数据结构中的基础概念,与队列先进先出(FIFO)的出队顺序不同的是 ,它的出队顺序与元素的优先级相关。
例如 React 的时间分片(React Fiber),它将渲染任务分了优先级,出队的顺序与任务的“重要程度”存在关系,那么满足这种情况的数据结构就是 优先队列 。
优先队列的操作
插入:在优先队列中插入元素,并使队列“有序” 删除最大/最小值:删除并返回最大/最小的元素,并使队列“有序” 查找最大/最小关键字:查找最大/最小的值
优先队列的实现比较
| 实现 | 插入 | 删除 | 查找最大/最小关键字 |
|---|---|---|---|
| 数组 | 1 | n | n |
| 链表 | 1 | n | 1 |
| 有序数组 | n 或 logn | n | 1 |
| 有序链表 | n | 1 | 1 |
| 二叉搜索树 | logn | logn | logn |
| 二叉堆 | logn | logn | 1 |
logn ,但二叉树在多次删除之后容易导致树的倾斜,同时查找成本也高于二叉堆,所以最终二叉堆是比较符合实现优先队列的数据结构。二叉堆
在二叉堆中数组中,要保证每个元素都小于(大于)或等于另外两个特定位置的元素。例如下图的树中,父节点总是小于或等于子节点。
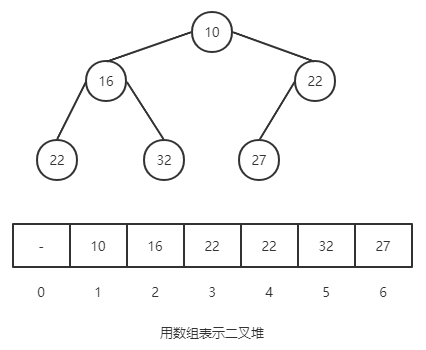
对于二叉堆有如下性质:
节点 k 的父节点下标为 k / 2(向下取整) 以某节点为根节点的子树,该节点是这颗树的极值
二叉堆的操作
插入
二叉堆的插入非常简单,只需要在二叉堆的最后添加要插入的内容,并将其“上浮”到正确位置。
尝试在上面的二叉堆中插入新元素 9,过程如下:
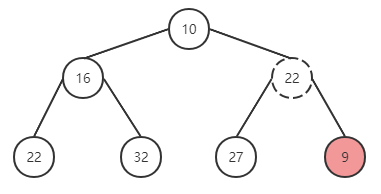
在尾部插入元素 9,与父节点进行对比,有序性被破坏,与父元素替换位置。
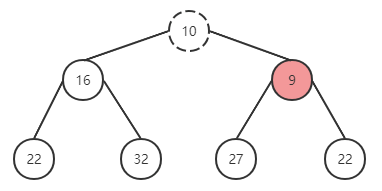
替换成功后,继续上一轮操作,与父节点进行对比,仍然无法满足有序性,继续调换位置。
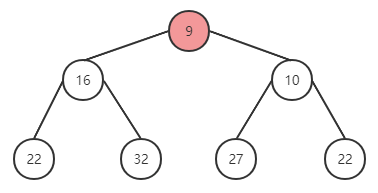
再次替换后符合。
程序框架
function push {
* 在堆尾部添加元素
* 执行上浮循环
* 与父元素对比大小,将较大的放在父节点位置
return minItem
}
实现
function push(heap: Heap, node: Node): void {
const index = heap.length;
heap.push(node); // 在堆尾部添加元素
siftUp(heap, node, index); // 进行上浮操作
}
function siftUp(heap, node, i) {
let index = i;
while (true) {
const parentIndex = (index - 1) >>> 1; // 父节点位置:parentIndex = childIndex / 2
const parent = heap[parentIndex];
if (parent !== undefined && compare(parent, node) > 0) {
// The parent is larger. Swap positions.
heap[parentIndex] = node;
heap[index] = parent;
index = parentIndex;
} else {
// The parent is smaller. Exit.
return;
}
}
}
删除
取出根节点的值对比插入稍微复杂一点,归纳起来可以分为三步:
取出根节点的值 将最后一个元素与根节点进行替换,并删除最后一个元素 下沉
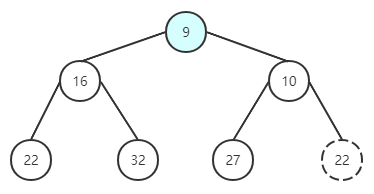
取出根节点。
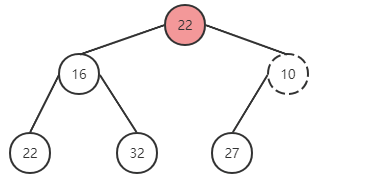
将最后一个元素与根节点调换,并删除。对比发现有序性被破坏,进行对调。
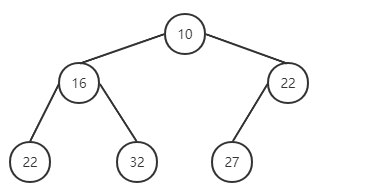
完成删除。
程序框架
function pop {
* 设定 minItem 保存根节点
* 取出最后一个节点与根节点替换,并删除最后一个节点
* 执行下沉循环
* 将根元素与左右子节点对比,挑选较小的与父节点替换位置
return minItem
}
实现
export function pop(heap: Heap): Node | null {
const first = heap[0]; // 取出根节点
if (first !== undefined) {
const last = heap.pop(); // 取出最后一位元素,并删除
if (last !== first) {
heap[0] = last; // 与根节点对调
siftDown(heap, last, 0); // 下沉
}
return first;
} else {
return null;
}
}
function siftDown(heap, node, i) {
let index = i;
const length = heap.length;
while (index < length) {
const leftIndex = (index + 1) * 2 - 1;
const left = heap[leftIndex];
const rightIndex = leftIndex + 1;
const right = heap[rightIndex];
// If the left or right node is smaller, swap with the smaller of those.
// 寻找左右儿子较小的那一个替换
if (left !== undefined && compare(left, node) < 0) { //左子节点小于根节点
if (right !== undefined && compare(right, left) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
heap[index] = left;
heap[leftIndex] = node;
index = leftIndex;
}
} else if (right !== undefined && compare(right, node) < 0) { // 左子节点大于根节点,右子节点小于根节点
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
// Neither child is smaller. Exit.
return;
}
}
}
以下是 React 源码中 scheduler/src/SchedulerMinHeap.js 关于最小堆的完整实现:
/**
* Copyright (c) Facebook, Inc. and its affiliates.
*
* This source code is licensed under the MIT license found in the
* LICENSE file in the root directory of this source tree.
*
* @flow strict
*/
// 定义最小堆极其元素,其中 sortIndex 为最小堆对比的 key,若 sortIndex 相同,则对比 id
type Heap = Array<Node>;
type Node = {|
id: number,
sortIndex: number,
|};
// 入队操作,在入队完成之后进行“上浮”
export function push(heap: Heap, node: Node): void {
const index = heap.length;
heap.push(node);
siftUp(heap, node, index);
}
// 查找最大值
export function peek(heap: Heap): Node | null {
const first = heap[0];
return first === undefined ? null : first;
}
// 删除并返回最大值
export function pop(heap: Heap): Node | null {
const first = heap[0]; // 取出根节点(哨兵)
if (first !== undefined) {
const last = heap.pop(); // 取出最后一位元素,并删除
if (last !== first) { // 头尾并没有对撞
heap[0] = last; // 与根节点对调
siftDown(heap, last, 0); // 下沉
}
return first;
} else {
return null;
}
}
// 上浮,调整树结构
function siftUp(heap, node, i) {
let index = i;
while (true) {
const parentIndex = (index - 1) >>> 1; // 父节点位置:parentIndex = childIndex / 2,此处使用位操作,右移一位
const parent = heap[parentIndex];
if (parent !== undefined && compare(parent, node) > 0) { // 对比父节点和子元素的大小
// The parent is larger. Swap positions.
heap[parentIndex] = node; // 若父节点较大,则更换位置
heap[index] = parent;
index = parentIndex;
} else {
// The parent is smaller. Exit.
return;
}
}
}
// 下沉,调整树结构
function siftDown(heap, node, i) {
let index = i;
const length = heap.length;
while (index < length) {
const leftIndex = (index + 1) * 2 - 1;
const left = heap[leftIndex];
const rightIndex = leftIndex + 1;
const right = heap[rightIndex];
// If the left or right node is smaller, swap with the smaller of those.
// 寻找左右儿子较小的那一个替换
if (left !== undefined && compare(left, node) < 0) {
if (right !== undefined && compare(right, left) < 0) { // 左子节点小于根节点
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
heap[index] = left;
heap[leftIndex] = node;
index = leftIndex;
}
} else if (right !== undefined && compare(right, node) < 0) { // 左子节点大于根节点,右子节点小于根节点
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
// Neither child is smaller. Exit.
return;
}
}
}
function compare(a, b) {
// Compare sort index first, then task id.
const diff = a.sortIndex - b.sortIndex;
return diff !== 0 ? diff : a.id - b.id;
}
堆排序
利用最大/最小堆的特性,我们很容易就能实现对数组的排序,重复执行 pop 就能进行升序排列,如果要降序,使用最大堆即可,该操作时间复杂度为 nlogn。
多叉堆
为了追求更优的时间复杂度,我们可以将二叉堆改为多叉堆实现,下图为一个三叉堆:
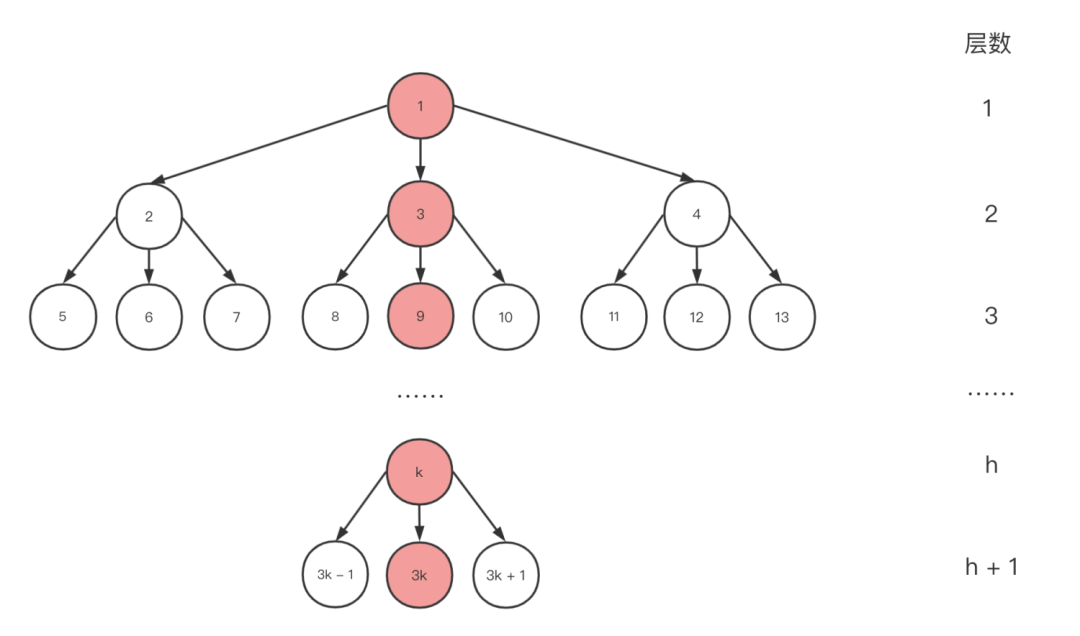
与二叉堆不同的是对于含有 N 个元素的 d 叉堆(通常情况下 d >= 2),随着 d 的增加,树高 K = logdN 的斜率会下降,然而 d 越大,删除操作的成本会更高。所以子元素不是越多越好,通常情况下三叉堆和四叉堆的应用会比较常见。
在 libev 中有这么一段注释 https://github.com/enki/libev/blob/master/ev.c#L2227,他提及了四叉树相比二叉堆来说缓存更加友好。根据 benchmark,在 50000+ 个 watchers 的场景下,四叉树会有 5% 的性能优势。
/*
* at the moment we allow libev the luxury of two heaps,
* a small-code-size 2-heap one and a ~1.5kb larger 4-heap
* which is more cache-efficient.
* the difference is about 5% with 50000+ watchers.
*/
同样 Go 语言中的定时器的 timersBucket 的数据结构也采用了最小四叉堆。
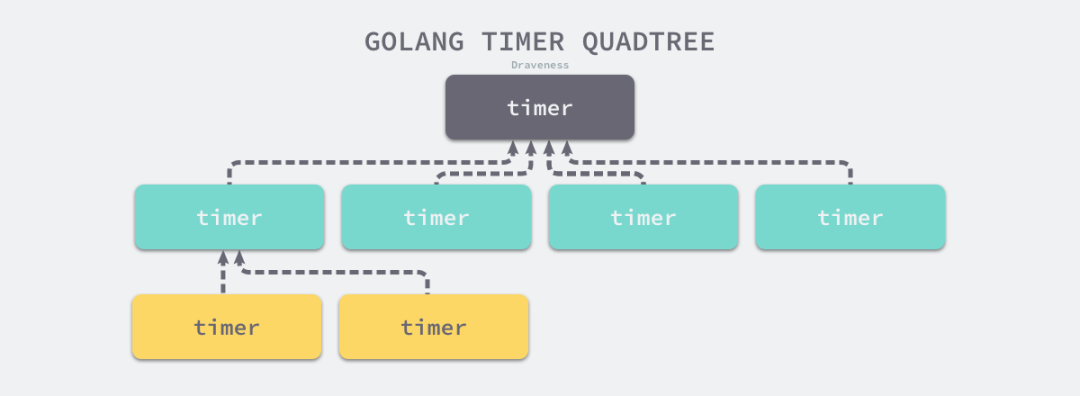
结语
多叉堆,例如四叉堆更加适合数据量大,对缓存要求友好对场景。二叉堆适用数据量比较小且频繁插入和删除的场景。通常情况下二叉堆可以满足大部分情况下的需求,如果编写底层代码,并且对性能有更高的要求,那么可以考虑多叉堆实现优先队列。
看完两件事
如果你觉得这篇内容对你挺有启发,我想邀请你帮我两件小事
1.点个「在看」,让更多人也能看到这篇内容(点了「在看」,bug -1 😊)
点个『在看』支持下 