
在OneFlow实现数据类型自动提升
问题引入
我们先简单看下在pytorch下的这几段代码,读者可以猜下最后输出的类型是什么:
x_tensor = torch.ones((3, ), dtype=torch.int8)
y1_tensor = torch.tensor(1, dtype=torch.float64)
out1 = torch.mul(x_tensor, y1_tensor)
y2_tensor = torch.tensor(1, dtype=torch.int64)
out2 = torch.mul(x_tensor, y2_tensor)
out3 = torch.mul(x_tensor, 1.0)
out4 = torch.mul(x_tensor, 2^63-1(the max value of int64))
接下来揭晓答案:
out1.dtype: torch.float64
out2.dtype: torch.int8
out3.dtype: torch.float32
out4.dtype: torch.int8
可以观察到同样是multiply运算,有些结果的数据类型被提升到更高的一级,有些并没有被提升,还维持着int8类型。这其实是一种类型提升系统,系统内会自定义一些类型提升的规则,根据输入的数据类型来推导最终结果的数据类型。
Python Array API标准
参考链接:https://data-apis.org/array-api/latest/API_specification/type_promotion.html
在这里我们可以了解到Python Array的类型提升规则
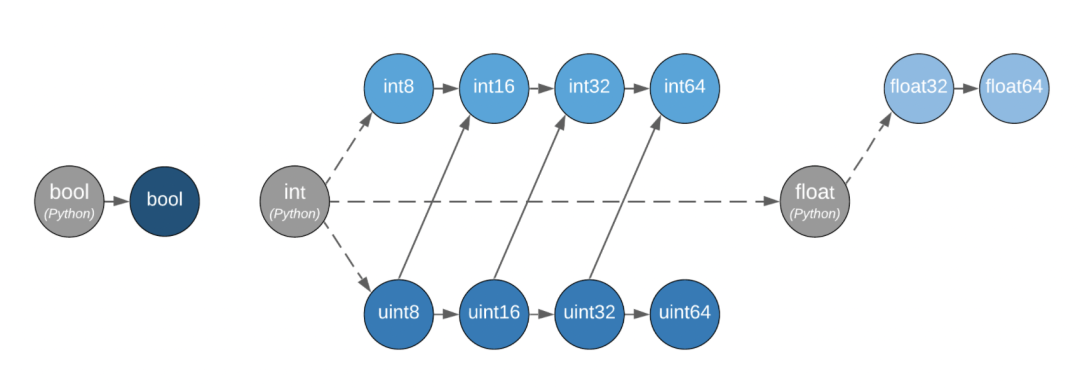
从上图可以看到:
不同数据类型的提升遵循这个连接的规则 虚线表示python标量在溢出的时候未定义 bool int float之间没有连线,表示这种混合类型的提升未定义
关于第一条,我们可以看int8和uint8,两者最终指向了int16,表示两者运算后最终类型提升到了int16
而根据这一个规则,我们可以列出一个类型提升表格(这个表格很重要,后续看Pytorch源码也会用到)
以unsigned int系列和signed int系列为例,列出的表格为: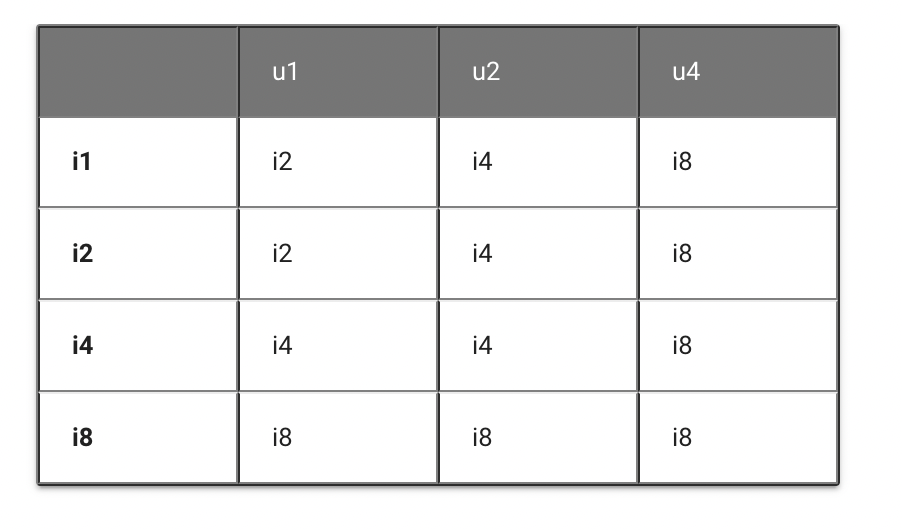
更多类型提升规则表格可参考前面提到的链接
横坐标和纵坐标分别代表输入的数据类型,表格的值代表类型提升后的数据类型,其中:
i1 : 8-bit signed integer (i.e., int8 ) i2 : 16-bit signed integer (i.e., int16 ) i4 : 32-bit signed integer (i.e., int32 ) i8 : 64-bit signed integer (i.e., int64 )
同理于unsigned int
Python Array 和 Scalar 的类型提升
上述这些都是array与array之间运算的类型提升规则,而array与scalar(就是单独一个int,float数值)的类型提升规则则不一样。
如果两者同属于一个数据类型系列(比如都是int系列,包含int8, int32, int64),则最终数据类型遵循数组的数据类型 如果两者同不属于一个数据类型系列(比如一个是int32,一个是float),则进行类型提升
我们可以看下简单的两个例子:
x_tensor = torch.ones((3, ), dtype=torch.int16)
out1 = x_tensor + 2 # out.dtype = torch.int16
out2 = x_tensor + 2.0 # out.dtype = torch.float32
需要注意的是,Array与Scalar的行为会和Array与0d Array的行为保持一致。
我们可以再测试前面两个例子,不同之处是我们将scalar改成一个0d Array
x_tensor = torch.ones((3, ), dtype=torch.int16)
y1_tensor = torch.tensor(2)
y2_tensor = torch.tensor(2.0)
out1 = x_tensor + y1_tensor # out.dtype = torch.int16
out2 = x_tensor + y2_tensor # out.dtype = torch.float32
关于与Scalar运算的行为,Pytorch是和Python Array API标准一致的,但是Numpy则不同,他会根据scalar的数据范围做一个合理的类型提升:
import numpy as np
x = np.ones((3, 3), dtype=np.int32)
out = x + (2**31-1) # dtype: np.int32
out = x + (2**31) # dtype: np.int64
我个人更倾向于在类型提升中,Scalar是单独一种行为,而Scalar Tensor和Tensor的行为一致
其他情况
除了前面提到的规则,Pytorch还存在以下两种情况:
要求两个输入的数据类型完全一致,如 torch.dot
RuntimeError: dot : expected both vectors to have same dtype, but found Short and Float
输入存在一个最低数据类型,比如 torch.sum,传任意int系列数据类型,最终输出结果均为torch.int64。
以上就简单介绍了Pytorch的类型提升规则,还想要更多的例子可以参考官方文档:https://pytorch.org/docs/master/tensor_attributes.html#torch.torch.dtype
Pytorch是怎么做类型提升的?
实际运算的Kernel,输入和输出的数据类型都是相同的模板参数,不存在特化一个输入为int32,输出为float32或其他类型的函数。
因此Pytorch内部会先推断出一个合理的dtype,然后插入一个to这个op,将输入tensor进行类型提升,再进入到Kernel进行实际的运算。下面我们会根据Pytorch的源码进行讲解:
涉及到的代码:https://github.com/pytorch/pytorch/blob/master/c10/core/ScalarType.h
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Activation.cpp
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/TensorIterator.cpp
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TypeProperties.cpp
ScalarType.h
在这个头文件里定义了相关的数据类型,并且定义了一个类型提升的二维矩阵,这样我们就可以输入两个数据类型,根据索引拿到提升后的数据类型。

Activation.cpp
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Activation.cpp#L24
我们以其中一个激活函数threshold为例子
TORCH_META_FUNC(threshold)(const Tensor& self, const Scalar& threshold, const Scalar& value) {
const Tensor& result = maybe_get_output();
build(TensorIteratorConfig()
...
.promote_inputs_to_common_dtype(true)
}
这里调用了一个build函数,函数接受一个TensorIteratorConfig,这个Config类是用于配制各种属性,可以看到这里调用promote_inputs_to_common_dtype并设为true。
TensorIterator.cpp
build函数定义在:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/TensorIterator.cpp#L1321
在1340行,build函数内部调用了compute_type函数
...
compute_types(config);
...
而该函数在260行开始,进行一系列类型推导
其中TensorIterator是一个容器类(Numpy里也有一个类似的容器NpyIter),用于存储输出,输入tensor,里面用了多个for循环来推导得到一个common_dtype。
并在最后进行条件判断:promote_inputs_to_common_dtype_为true,当前Tensor不是输出Tensor,且输入的dtype不等于推导得到的common_dtype,则做一个类型提升:
// Promotes inputs by creating temporaries of the correct dtype
if (config.promote_inputs_to_common_dtype_ && !op.is_output && op.current_dtype != common_dtype_) {
op.original_tensor = op.tensor;
op.tensor = c10::MaybeOwned::owned(op.tensor->to(common_dtype_));
op.current_dtype = common_dtype_;
op.target_dtype = common_dtype_;
}
OneFlow的做法
相关PR:https://github.com/Oneflow-Inc/oneflow/pull/6380
OneFlow则将类型提升的逻辑放在c++中functional前端部分,类似的我们设计了一个TensorProcessor类,接口设计如下:
class TensorProcessor final {
public:
TensorProcessor()
: common_dtype_(DType::InvalidDataType()), promote_inputs_to_common_dtype_(false){};
TensorProcessor& AddInputs(const TensorTuple& init_list);
TensorProcessor& AddInputs(const TensorTuple& init_list, Symbol tensor_lowest_dtype) ;
Maybe<void> Apply();
TensorProcessor& PromoteInputsToCommonDtype(bool is_promote);
Maybe GetInputs() { return tensor_tuple_; };
private:
TensorTuple tensor_tuple_;
Symbol common_dtype_;
std::vector> inputs_lowest_dtype_vec_;
bool promote_inputs_to_common_dtype_;
};
以二元操作Functor基类为例,在实际调用的时候,我们可以这样:
class BinaryFunctor{
public:
Maybe operator()(const std::shared_ptr& x,
const std::shared_ptr& y) const {
TensorProcessor tensor_processor;
JUST(tensor_processor.PromoteInputsToCommonDtype(true).AddInputs({x, y}).Apply());
TensorTuple input_tuple = JUST(tensor_processor.GetInputs());
return OpInterpUtil::Dispatch(*op_, input_tuple);
...
}
...
};
PromoteInputsToCommonDtype 用于设置相关属性 AddInputs函数将需要参与类型提升的Tensor添加到容器中 Apply函数执行实际的类型提升等逻辑
tensor_processor.cpp还有其他几个函数,这里简单介绍下功能:
CheckHasDifferentInputDType 遍历输入Tensor,检查输入Tensor是否有不同的dtype ComputeCommonDType 根据输入dtype推导一个合理的提升过的dtype CastToSameType 给输入Tensor插入一个Cast操作
Maybe<void> CastToSameType(TensorTuple& tensor_tuple, const Symbol& common_dtype) {
for (auto& tensor_ptr : tensor_tuple) {
if (tensor_ptr->dtype() != common_dtype) {
tensor_ptr = JUST(functional::Cast(tensor_ptr, common_dtype));
}
}
return Maybe<void>::Ok();
}
Apply函数逻辑如下:
Maybe<void> TensorProcessor::Apply() {
if (promote_inputs_to_common_dtype_) {
bool has_different_input_dtype = CheckHasDifferentInputDType(tensor_tuple_);
if (has_different_input_dtype) {
common_dtype_ = ComputeCommonDType(tensor_tuple_);
JUST(CastToSameType(tensor_tuple_, common_dtype_));
}
} else {
for (int i = 0; i < tensor_tuple_.size(); ++i) {
// Cast all the inputs to it's attribute `lowest_dtype` if the input tensor dtype is lower
// than attribute `lowest_dtype`.
Symbol base_dtype = inputs_lowest_dtype_vec_.at(i);
if (base_dtype->data_type()
&& DType::priority_order[base_dtype->data_type()]
> DType::priority_order[tensor_tuple_.at(i)->dtype()->data_type()]) {
tensor_tuple_.at(i) = JUST(one::functional::Cast(tensor_tuple_.at(i), base_dtype));
}
}
}
return Maybe<void>::Ok();
}
if内执行的是类型提升,而else内逻辑则是对应前面提到的其他情况中的第二条,将Tensor类型提升到设定好的一个最低数据类型。还是sum算子,我们设定最低数据类型为int64是这么做的:
class ReduceSumFunctor{
public:
Maybe operator()(const std::shared_ptr& x, const std::vector<int32_t>& axis,
const bool& keepdims) const {
...
TensorProcessor tensor_processor;
JUST(tensor_processor.AddInputs({x}, /*lowest_dtype=*/DType::Int64()).Apply());
TensorTuple input_tuple = JUST(tensor_processor.GetInputs());
}
...
};
总结
类型提升是一个我们不经意间会使用的一个操作,如果没有正确处理输出的数据类型,则可能导致结果溢出,出现错误的结果。看似很简单,但实际调研+推敲细节也搞了两三周,最后感谢同事在我完成这个功能的期间提供的许多帮助!
点击下方原文链接直达OneFlow仓库,欢迎关注。