
如何让 Jupyter Notebook 自动导入代码?

大家好,我是宝器。
作为使用 Python 工作的数据科学家。每天我们都会启动多个新的Jupyter笔记本,并且在会用到多个不同的库,例如pandas、matplotlib等。
但是,在开始实际工作之前,我们总是需要为每一个 Notebook 写一堆的导入代码,虽然这不困难,但是却很繁琐,有时还需要查找对应的导入语句例如
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
怎样才能在启动Jupyter 笔记本时自动加载这些代码,让我们只专注于使用这些库?本文介绍两种办法。
方法一 : 修改配置文件
一个常见的方法就是通过修改Jupyter的配置文件来实现,这也是我在之前文章中介绍过的方法。
以macOS为例,你可以进入~/.ipython/profile_default文件夹(Windows下也可以在安装目录中找到对应的文件夹),如果找不到该目录需在命令行执行ipython profile create生成配置文件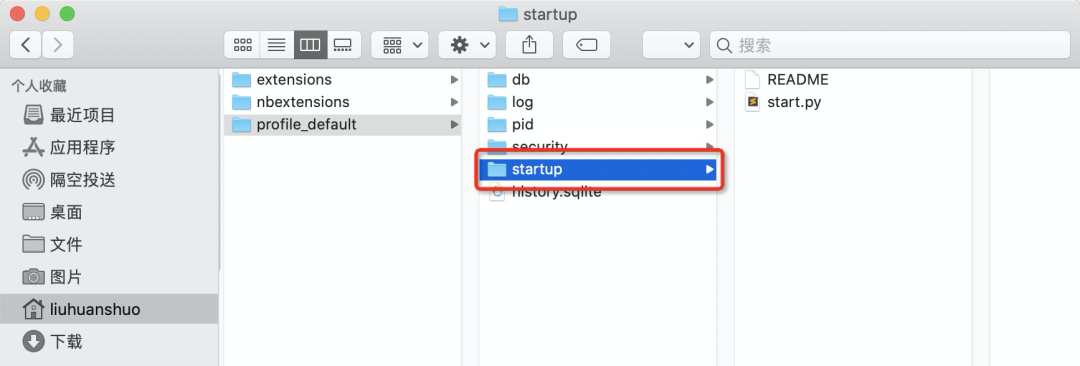
如上图所示,在该文件夹下新建一个名为startup的文件夹(如果有则不用新建),之后进入startup文件夹新建一个Python脚本start.py
现在你可以在start.py中尽情的添加你每次启动jupyter notebook后都需要手动敲入的那段代码,之后保存即可
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
.......
现在重启Jupyter Notebook后就可以直接使用pandas、numpy等我们配置好的库!
但这个方法也有一个弊端,就是由于文件缺少相关导入代码,因此可能打包发给别人用时会无法执行,我们也不可能再次检查所用的代码然后手动导入一遍,所以只能在自己修改了配置文件的设备上用用。
方法二 : 使用 pyforest
这是我最近新发现的一个方法,由国外大神开发的一个插件,相比较修改配置文件,更适合小白操作。
我们只需要在终端(命令行)执行以下代码
pip install --upgrade pyforest
python -m pyforest install_extensions
之后重启Jupyter Notebook后便可以实现自动导入相关库。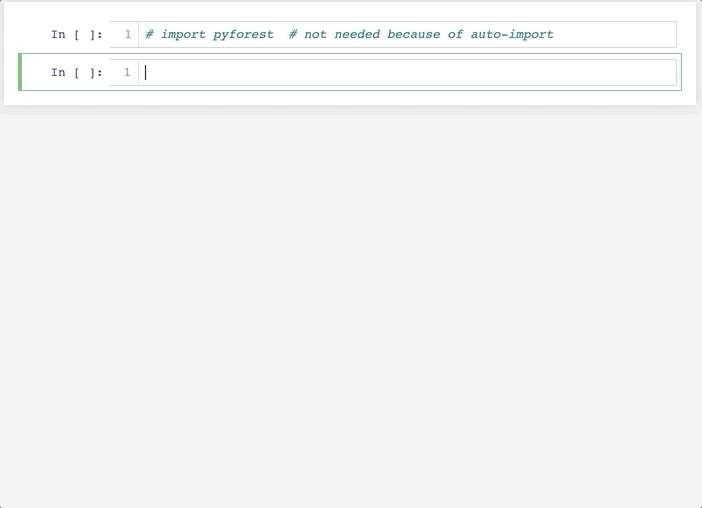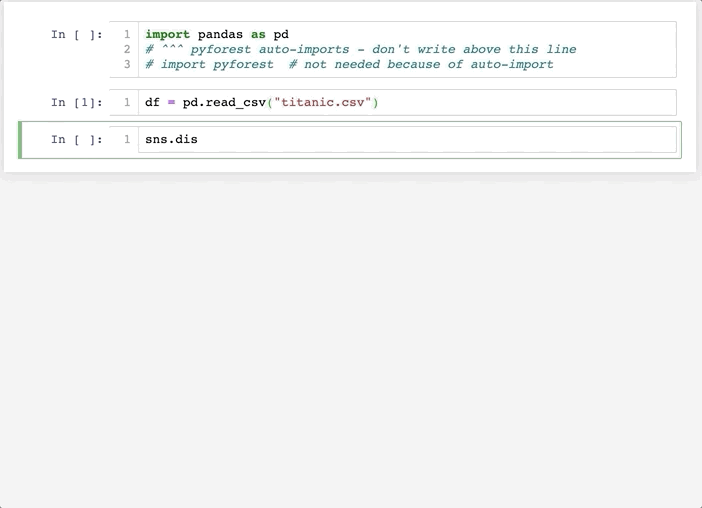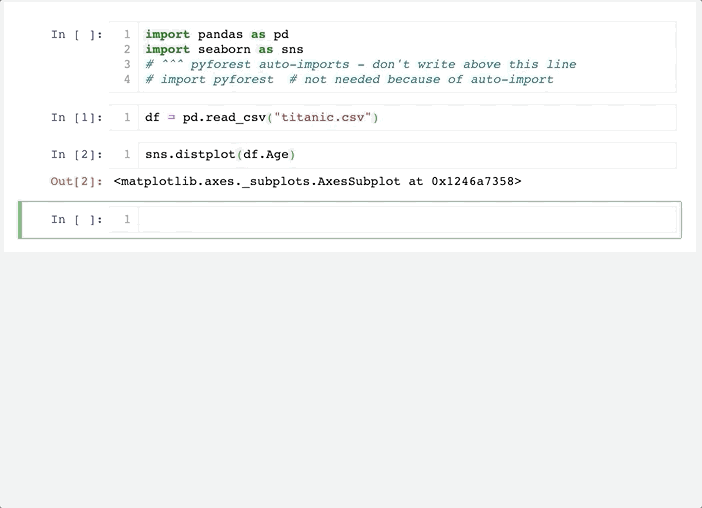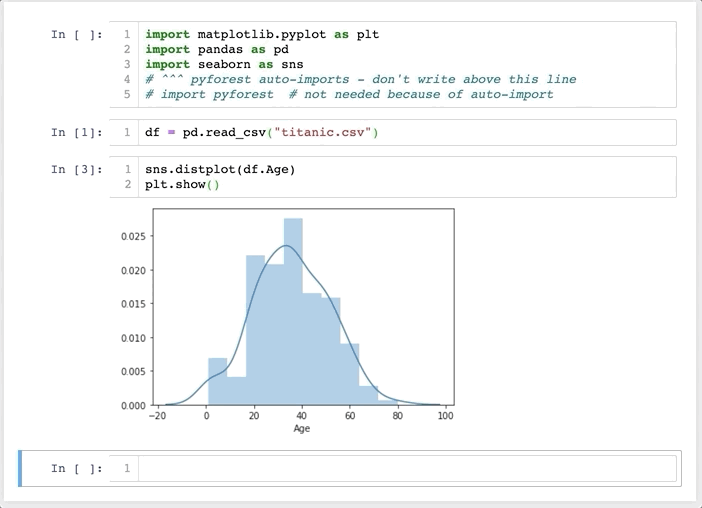
可以看到,这个方法和方法一的差别在于,他不是默认导入全部的依赖库(避免了过多的内存占用),而是在你使用到这个库时,自动在Notebook头部添加对应的导入代码,是不是很酷!
以pandas为例,当我们使用到pd.xxx便会在头部添加import pandas as pd,而在使用它之前,变量pd只是pyforest占位符。
但使用别人配置好的缺点就是自己想额外添加一些第三方库会比较困难,好在开发者已经预设了上百个常用库,从数据分析到机器学习、深度学习都有,基本上不用额外设置,感兴趣的话可以尝试一下~
如果你也想快速上手pandas,你可以打开我的网站进行学习👇

推荐阅读
欢迎长按扫码关注「数据管道」