
你有没深入想过,什么造成了GPT-4的输出很随机?

来源:机器之心 本文约2000字,建议阅读5分钟
Google Deepmind 可能早就意识到了这个问题。
今年,大型语言模型(LLM)成为 AI 领域最受关注的焦点,OpenAI 的 ChatGPT 和 GPT-4 更是爆火出圈。GPT-4 在自然语言理解与生成、逻辑推理、代码生成等方面性能出色,令人惊艳。
然而,人们逐渐发现 GPT-4 的生成结果具有较大的不确定性。对于用户输入的问题,GPT-4 给出的回答往往是随机的。
我们知道,大模型中有一个 temperature 参数,用于控制生成结果的多样性和随机性。temperature 设置为 0 意味着贪婪采样(greedy sampling),模型的生成结果应该是确定的,而 GPT-4 即使在 temperature=0.0 时,生成的结果依然是随机的。
在一场圆桌开发者会议上,有人曾直接向 OpenAI 的技术人员询问过这个问题,得到的回答是这样的:「老实说,我们也很困惑。我们认为系统中可能存在一些错误,或者优化的浮点计算中存在一些不确定性......」
值得注意的是,早在 2021 年就有网友针对 OpenAI Codex 提出过这个疑问。这意味着这种随机性可能有更深层次的原因。
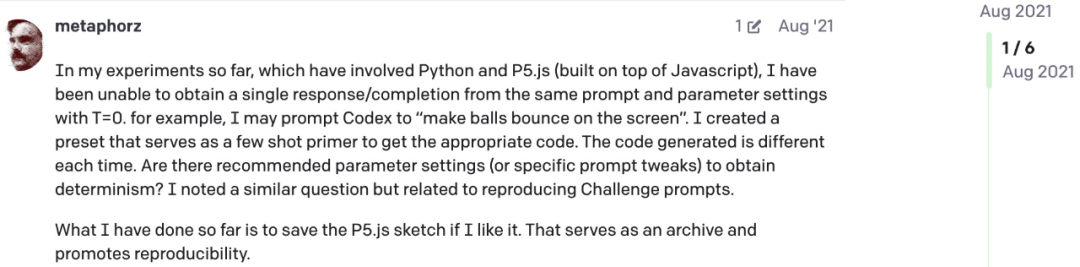
图源:https://community.openai.com/t/a-question-on-determinism/8185
现在,一位名为 Sherman Chann 的开发者在个人博客中详细分析了这个问题,并表示:「GPT-4 生成结果的不确定性是由稀疏 MoE 引起的」。
Sherman Chann 博客地址:
https://152334h.github.io/blog/non-determinism-in-gpt-4/
Sherman Chann 这篇博客受到了 Google DeepMind 最近一篇关于 Soft MoE 的论文《From Sparse to Soft Mixtures of Experts》启发。

论文地址:https://arxiv.org/pdf/2308.00951.pdf
在 Soft MoE 论文的 2.2 节中,有这样一段描述:
在容量限制下,所有稀疏 MoE 都以固定大小的组来路由 token,并强制(或鼓励)组内平衡。当组内包含来自不同序列或输入的 token 时,这些 token 通常会相互竞争专家缓冲区中的可用位置。因此,模型在序列级别不再具有确定性,而仅在批次级别(batch-level)具有确定性,因为某些输入序列可能会影响其他输入的最终预测。

此前,有人称 GPT-4 是一个混合专家模型(MoE)。Sherman Chann 基于此做出了一个假设:
GPT-4 API 用执行批推理(batch inference)的后端来托管。尽管一些随机性可能是因为其他因素,但 API 中的绝大多数不确定性是由于其稀疏 MoE 架构未能强制执行每个序列的确定性。
import os
import json
import tqdm
import openai
from time import sleep
from pathlib import Path
chat_models = ["gpt-4", "gpt-3.5-turbo"]
message_history = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a unique, surprising, extremely randomized story with highly unpredictable changes of events."}
]
completion_models = ["text-davinci-003", "text-davinci-001", "davinci-instruct-beta", "davinci"]
prompt = "[System: You are a helpful assistant]\n\nUser: Write a unique, surprising, extremely randomized story with highly unpredictable changes of events.\n\nAI:"
results = []
import time
class TimeIt:
def __init__(self, name): self.name = name
def __enter__(self): self.start = time.time()
def __exit__(self, *args): print(f"{self.name} took {time.time() - self.start} seconds")
C = 30 # number of completions to make per model
N = 128 # max_tokens
# Testing chat models
for model in chat_models:
sequences = set()
errors = 0 # although I track errors, at no point were any errors ever emitted
with TimeIt(model):
for _ in range(C):
try:
completion = openai.ChatCompletion.create(
model=model,
messages=message_history,
max_tokens=N,
temperature=0,
logit_bias={"100257": -100.0}, # this doesn't really do anything, because chat models don't do <|endoftext|> much
)
sequences.add(completion.choices[0].message['content'])
sleep(1) # cheaply avoid rate limiting
except Exception as e:
print('something went wrong for', model, e)
errors += 1
print(f"\nModel {model} created {len(sequences)} ({errors=}) unique sequences:")
print(json.dumps(list(sequences)))
results.append((len(sequences), model))
# Testing completion models
for model in completion_models:
sequences = set()
errors = 0
with TimeIt(model):
for _ in range(C):
try:
completion = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=N,
temperature=0,
logit_bias = {"50256": -100.0}, # prevent EOS
)
sequences.add(completion.choices[0].text)
sleep(1)
except Exception as e:
print('something went wrong for', model, e)
errors += 1
print(f"\nModel {model} created {len(sequences)} ({errors=}) unique sequences:")
print(json.dumps(list(sequences)))
results.append((len(sequences), model))
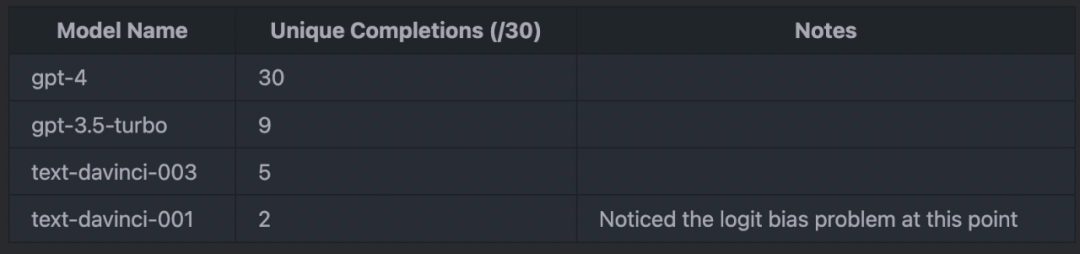
# Printing table of results
print("\nTable of Results:")
print("Num_Sequences\tModel_Name")
for num_sequences, model_name in results:
print(f"{num_sequences}\t{model_name}")




编辑:文婧