
Linux同步原语系列-spinlock及其演进优化
1. 引言
通常我们的说的同步其实有两个层面的意思:
一个是线程间的同步,主要是为了按照编程者指定的特定顺序执行;
另外一个是数据的同步,主要是为了保存数据。
为了高效解决同步问题,前人抽象出同步原语供开发者使用。不仅多核,单核也需要同步原语,核心的问题要保证共享资源访问的正确性。如果共享资源划分不合理,同步原语的开销会制约多核性能。
常见的同步原语有:互斥锁、条件变量、信号量、读写锁、RCU等。
本文主要聚焦于互斥锁,对应linux的spinlock,我们试图沿着时间的脉络去梳理spinlock的不断改进的进程,如果涉及CPU体系结构,我们主要关注ARM体系结构的实现。如果后续有时间我们会继续分析其他同步原语的演进和优化历程。
2. 演化进程
linux内核spinlock是互斥机制的最底层基础设施,它的性能直接关系到内核的性能,主要分为这么几个阶段:
linux-2.6.25之前,我们称之为
原始spinlock。对锁的实现,是使用原子操作去无序竞争全局的锁资源。
这个阶段对锁的争用处于无序竞争的状态。如果CPU核心数不多,资源相对充裕,好比我们去银行柜台办理业务,一共就1-2个人,无非你在前还是我在前的问题,公平性的问题并不突出,性能也没什么大的影响,但是一旦cpu核心数和锁的竞争者相对较多时,就会出现有些人因为某些优势(如CPU算力强,锁正好落在当前CPU的cacheline中等)总是能抢到锁,其他人总是抢不到的情况出现。
linux-2.6.25,在x86下实现了
ticket spinlock,替换原始spinlock。随着CPU核数的增多以及对共享资源的争用越发激烈,公平性问题就显现出来了。保证公平一个很自然的思路就是大家都来排队。如果对锁的争用比较激烈再加上如果此时核比较多,此时一旦释放锁,其实只有1个CPU能抢到锁,但是因为大家观察都是全局的一个锁,那其他CPU的cacheline会因此失效,会有相当程度的性能损耗。还是就以去银行柜台办理业务为例,它的实现相当于去银行取号、排队、等叫号这么一个过程,问题在于叫号相当是一个广播机制,所有人都要侦听,还是有点浪费时间精力。
linux-3.5,ARM体系结构用
ticket spinlock替换了原始spinlock。过了几个版本,ARM才替换,原因作者没有去考证,不得而知。
linux-3.15,实现了
mcs_spinlock,但未替换ticket spinlock。它把对全局锁转换成per-cpu的锁,减少争用的损耗,然后各个锁之间通过链表串起来排队,解决了公平性和性能损耗的问题。然后它却没有替代
ticket spinlock成为内核默认实现,因为spinlock太底层了,已经嵌入了内核的各种关键数据结构中,它的数据结构要比spinlock大,这是内核锁不能接受的,但是最终它还是合入了内核,只是没有人去用它。但是它的存在为后一步的优化,仍然起到了非常重要的作用。它的实现思路是把ticket spinlock的广播机制转变为击鼓传花,也就是实际上可以我并需要侦听广播,主要在我前面排队的人在使用完锁以后告诉我可以了。linux-4.2,实现了
queued spinlock(简称qspinlock),替换了ticket spinlock。它首先肯定要解决
mcs_spinlock占用大小,实际上它结合了ticket spinlock和mcs_spinlock的优点,大小保持一致,如果只有1个或2个CPU试图获取锁,只用这个新的spinlock,当有3个以上的CPU试图获取锁,才需要mcs_spinlock。它的数据结构有表示当前锁的持有情况、是否有还有一个竞争者,已经需要快速找到对应CPU的per-cpu结构的mcs_spinlock节点,这3个大的域被塞在ticket spinlock同样大小数据结构中。这种遵守原先架构约束的情况而做出的改进,非常值得我们学习。linux-4.19,ARM体系结构将
queued spinlock替换成默认实现。原因是什么,作者同样没去考证。
3. 原始spinlock实现
3.1 关键数据结构和公共代码
typedef struct {
volatile unsigned int lock;
} raw_spinlock_t;
typedef struct {
raw_spinlock_t raw_lock;
} spinlock_t;
#define spin_lock(lock) _spin_lock(lock)
void __lockfunc _spin_lock(spinlock_t *lock)
{
preempt_disable();
_raw_spin_lock(lock);
}
# define _raw_spin_lock(lock) __raw_spin_lock(&(lock)->raw_lock)
3.2 ARM体系结构的加锁实现
//arm32(那时候还没arm64)的实现,这个时期的内核大体对应ARMV6
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
unsigned long tmp;
__asm__ __volatile__(
"1: ldrex %0, [%1]\n" //1.
" teq %0, #0\n" //2.
" strexeq %0, %2, [%1]\n" //3.
" teqeq %0, #0\n" //4.
#ifdef CONFIG_CPU_32v6K
" wfene\n" //5.
#endif
" bne 1b" //6.
: "=&r" (tmp)
: "r" (&lock->lock), "r" (1)
: "cc");
smp_mb(); //7.
}
通过数据结构,可以看出,此时的lock还是一个unsigned int类型的数据,加锁的时候,首先会关闭抢占,然后会转到各个体系结构的实现,我们关注ARM的实现,__raw_spin_lock的分析如下:
读取lock的状态值给tmp,并将&lock->lock标记为独占。
判断lock的状态是否为0。如果是0说明可以继续往下走(跳到第3步);如果不为0,说明自旋锁处于上锁状态,不能访问,跳到第5步(如果不支持WFE则直接跳到第6步)自旋,最后回到第1步自旋。teq执行会影响标志寄存器中Z标志位,后面带eq或者ne后缀的执行都受该标志位影响。
执行
strex执行,只有从上一次ldrex执行到本次strex这个被标记为独占的地址(&lock->lock)没有改变,才会执行成功(lock的状态改写为1)。通过strex执和ldrex实现原子性操作。继续判断lock的状态是否为0,为0说明获得锁;不为0说明没有获得锁,跳到第5步(如果支持WFE的话)。
执行
WFE指令(如果支持的话),CPU进低功耗状态,省点功耗。如果收到
SEV指令(如果有第五步的话),继续判断lock的状态是否为0,不为0跳到第1步,继续循环;如果lock为0,继续跳到第7步执行barrier(多核情况下为)
DMB指令,保证访存顺序按我们的编程顺序执行(即后面的load/store绝不允许越过smp_mb()屏障乱序到前面执行)。
3.3 ARM体系结构的解锁实现
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
smp_mb();
__asm__ __volatile__(
" str %1, [%0]\n"
#ifdef CONFIG_CPU_32v6K
" mcr p15, 0, %1, c7, c10, 4\n" /* DSB */
" sev"
#endif
:
: "r" (&lock->lock), "r" (0)
: "cc");
}
解锁的操作相对简单,str将lock->lock赋值,然后使用DSB保序,使用sev通知持锁cpu得到锁。
4. ticket spinlock
4.1 关键数据结构和公共代码
typedef struct {
union {
u32 slock;
struct __raw_tickets { //只考虑小端
u16 owner;
u16 next;
} tickets;
};
} arch_spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
} raw_spinlock_t;
typedef struct spinlock {
union {
struct raw_spinlock rlock;
};
} spinlock_t;
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
#define raw_spin_lock(lock) _raw_spin_lock(lock)
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
do_raw_spin_lock();
}
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
arch_spin_lock(&lock->raw_lock);
}
4.2 AArch32的加锁实现
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
__asm__ __volatile__(
"1: ldrex %0, [%3]\n" //1.
" add %1, %0, %4\n" //2.
" strex %2, %1, [%3]\n" //3.
" teq %2, #0\n" //4.
" bne 1b" //5.
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) { //6.
wfe(); //7.
lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);//8.
}
smp_mb(); //9.
}
把lock->slock值保存到lock_val
newval = lockval + (1 << TICKET_SHIFT)= lockval + (1 << 16),等价于newval =lockval.tickets.next++,相当于从银行取号机取号。
strex tmp, newval, [&lock->slock],将新的值newval 存在lock中,strex将是否成功结果存入在tmp中
检查是否写入成功lockval.tickets.next
成功则跳到第6步,否则返回第1步重试,同上文类似也是实现原子操作
lockval.tickets.next和owner成员是否相等,相等跳到第9步,成功获得锁;没有则跳到第7步。成功的话,相当于银行柜台已经叫我的号了,我就可以去办理业务了,没有的话,我还要继续等。
执行
WFE指令,CPU进低功耗状态,省点功耗。如果收到
SEV指令,从低功耗状态恢复,重新获得新的owner值,因为一般是别人释放了锁才会发送SEV指令,这时owner的值已经发生了变化,需要重新从内存中获取(ACCESS_ONCE本身的实现就是增加了volatile这个关键字,它确保编译器每次访问的变量都是从内存中获取,防止编译器优化)。执行barrier,同上文描述,不再赘述。
4.3 AArch32的解锁实现
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 slock;
smp_mb();
__asm__ __volatile__(
" mov %1, #1\n" //1.
"1: ldrex %0, [%2]\n" //2.
" uadd16 %0, %0, %1\n" //3.
" strex %1, %0, [%2]\n" //4.
" teq %1, #0\n" //5.
" bne 1b" //6.
: "=&r" (slock), "=&r" (tmp)
: "r" (&lock->slock)
: "cc");
dsb_sev(); //7.
}
将tmp赋值为1
将lock->slock的值赋值给slock。
将slock的低16bit,也就是owner成员的值加1。
将新的值新的ower,使用
strex写入中lock->slock,将是否成功结果存入在tmp中检查是否写入成功,成功,跳到第7步,实现了原子操作;不成功跳到第6步;
tmp不等于0(不成功),继续返回
label 1重试,即跳回第2步
4.4 AArch64的加锁实现
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
" prfm pstl1strm, %3\n" //1.
"1: ldaxr %w0, %3\n" //2.
" add %w1, %w0, %w5\n" //3.
" stxr %w2, %w1, %3\n" //4.
" cbnz %w2, 1b\n" //5.
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n" //6.
" cbz %w1, 3f\n" //7.
" sevl\n" //8.
"2: wfe\n" //9.
" ldaxrh %w2, %4\n" //10.
" eor %w1, %w2, %w0, lsr #16\n" //11.
" cbnz %w1, 2b\n" //12.
"3:" //13.
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
核心逻辑与AArch32类似,汇编实现会有不一样,这里不再展开。
从lock(memory)预取数据到L1cache中,加速执行。
使用
ldaxr指令(Load-acquire exclusive register,带Exclusive和Acquire-Release 两种语义),将lock的值赋值给lockval。newval = lockval + (1 << TICKET_SHIFT)= lockval + (1 << 16),等价于newval =lockval.tickets.next++,相当于从银行取号机取号。
使用
stxr指令,将newval赋值给lock,并将exclusive是否设置成功结果存放到tmp中。如果tmp != 0,说明exclusive失败,需要重新跳到开始处(第2步)重试,因为这时候其他CPU核心可能有是执行流插入,抢在我们前面执行。否则继续。
用
eor 异或运算实现lockval.tickets.next和owner成员是否相等的判断如果相等,跳到
label3(对应13步),获得锁进入临界区。否则往下,执行自旋。使用
SEVL指令(发送本地事件,Send Event Locally),唤醒本CPU核心,防止有丢失unlock的情况出现。执行
WFE指令,CPU进低功耗状态,省点功耗。获取当前的Owner值存放在tmp中
判断lockval.tickets.next和owner成员的值是否相等
如果不相等就回跳到
label2(对应第9步)。相等继续往下。结束退出。
4.5 AArch64的解锁实现
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
asm volatile(
" stlrh %w1, %0\n"
: "=Q" (lock->owner)
: "r" (lock->owner + 1)
: "memory");
}
解锁的操作相对简单,stlrh除了将lock->owner++(相当于银行柜台叫下一个排队者的号码),将会兼有SEV和DSB的功能。
5. mcs spinlock
5.1 关键数据结构和变量
struct mcs_spinlock {
struct mcs_spinlock *next; //1.
int nt locked; //2.
};
当一个CPU试图获取一个spinlock时,它就会将自己的MCS lock加到这个spinlock的等待队列的队尾,然后
next指向这个新的MCS lock。locked的值为1表示已经获得spinlock,为0则表示还没有持有该锁。
5.2 加锁的实现
static inline void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *prev;
node->locked = 0; //1.
node->next = NULL;
prev = xchg(lock, node); //2
if (likely(prev == NULL)) { //3
return;
}
ACCESS_ONCE(prev->next) = node; //4
arch_mcs_spin_lock_contended(&node->locked); //5.
}
先看下两个参数:
第1个参数
lock:是指向指针的指针(二级指针),是因为它指向的是末尾节点里的next域,而next本身是一个指向struct mcs_spinlock的指针。第2个参数
node:试图加锁的CPU对应的MCS lock节点。
接下来看代码逻辑
初始化node节点
找队列末尾的那个mcs lock。
xchg完成两件事,一是给一个指针赋值,二是获取了这个指针在赋值前的值,相当于下面两句:prev = *lock; //队尾的lock
*lock = node; //将lock指向新的node如果队列为空,CPU可以立即获得锁,直接返回;否则继续往下。不需要基于"locked"的值进行spin,所以此时
locked的值不需要关心。等价于
prev->next = node,把自己这个node加入等待队列的末尾。调用
arch_mcs_spin_lock_contended,等待当前锁的持有者将锁释放给我。
#define arch_mcs_spin_lock_contended(l) \
do { \
while (!(smp_load_acquire(l))) \ //1.
arch_mutex_cpu_relax(); \ //2.
} while (0)
上文中的
node->locked==0,说明没有获得锁,需要继续往下执行;说明已经获得锁,直接退出ARM64中
arch_mutex_cpu_relax调用cpu_relax函数的,有一个内存屏障指令防止编译器优化。从4.1开始还存一个yield指令。该指令,为了提高性能,占用cpu的线程可以使用该给其他线程。
5.3 解锁的实现
static inline void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *next = ACCESS_ONCE(node->next); //1.
if (likely(!next)) { //2.
if (likely(cmpxchg(lock, node, NULL) == node)) //3
return;
while (!(next = ACCESS_ONCE(node->next))) //4.
arch_mutex_cpu_relax(); //5.
}
arch_mcs_spin_unlock_contended(&next->locked); //6.
}
找到等待队列中的下一个节点
当前没有其他CPU试图获得锁
直接释放锁。如果
*lock == node,将*lock = NULL,然后直接返回;反之,说明当前队列中有等待获取锁的CPU。继续往下。cmpxchg作用翻译大致如下所示:cmpxchg(lock, node, NULL)
{
ret = *lock;
if (*lock == node)
*lock = NULL;
return ret;
}距离函数开头获得"next"指针的值已经过去一段时间了,在这个时间间隔里,可能又有CPU把自己添加到队列里来了。需要重新获得next指针的值。于是,待新的node添加成功后,才可以通过arch_mcs_spin_unlock_contended()将spinlock传给下一个CPU
如果next为空,调用
arch_mutex_cpu_relax,作用同上文。arch_mcs_spin_unlock_contended(l),实际上是调用smp_store_release((l), 1),将next->locked设置为1。将spinlock传给下一个CPU
6. queued spinlock
6.1 概述
它首先肯定要解决mcs_spinlock的占用空间问题,否则设计再好,也无法合入主线。它是这样的:大部分情况用的锁大小控制在跟以前ticket spinlock一样的水平,设计了两个域:分别是locked和pending,分别表示锁当前是否被持有,已经在持有时,是否又来了一个申请者竞争。争锁好比抢皇位,皇位永远只有1个(对应locked域),除此之外还有1个太子位(对应pending域),防止皇帝出现意外能随时候补上,不至于出现群龙无首的状态,他们可以住在紫禁城内(使用qspinlock)。这两个位置被占后,其他人还想来竞争皇位,只有等皇帝和太子都移交各自的位子以后才可以,在等待的时候你需要在紫禁城外待在自己的府邸里(使用mcs_spinlock),减小紫禁城的拥挤(减少系统损耗)。
即当锁的申请者小于或等于2时,只需要1个qspinlock就可以了,其所占内存的大小和ticket spinlock一样。当锁的竞争者大于2个时候,才需要(N-2)个mcs_spinlock。qspinlock还是全局的,为降低锁的竞争,使用退化到per-cpu的mcs_spinlock锁,所有的mcs_spinlock锁串行构成一个等待队列,这样cacheline invalide带来的损耗减轻了很多。这是它的基本设计思想。
在大多数情况下,per-cpu的mcs lock只有1个,除非发生了嵌套task上下文被中断抢占,因为中断上下文只有3种类(softirq、hardirq和nmi),所有每个CPU核心至多有4个mcs_spinlock锁竞争。而且,所有mcs_spinlock会串联到一个等待队列里的。
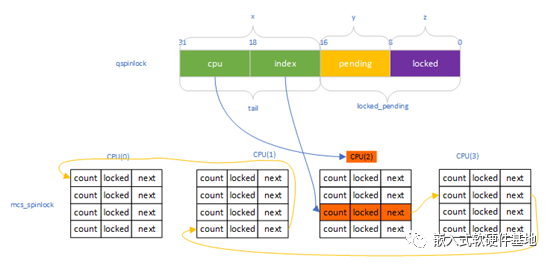
上图展示的是:qspinlock的locked和pending位都被占,需要进入mcs_spinlock等待队列,而CPU(2)是第1个进入等待队列的,qspinlock的tail.cpu则被赋值成2,CPU(2)的mcs_spinlock数组的第3个成员空闲,则qspinlock的tail.index被赋值成3。入队的是CPU(3)、CPU(1)和CPU(0),通过mcs_spinlock的next域将大家连成队列。
假如等到竞争qspinlock的2个锁的持有者,都释放了,则CPU(2)的第3个空闲成员则获得锁,完成它的临界区访问后,通过qspinlock的tail.cpu(类似于页表基址)和tail.index(类似于页表内的偏移),快速找到下个mcs_spinlock的node节点。
下面要进入细节分析了,本文只考虑小端模式、NR_CPUS < 16K的情况,不考虑虚拟化这块,去掉qstats统计,力图聚焦在该锁实现的核心逻辑上。
6.2 关键数据结构和变量
struct qspinlock
数据简化如下:
typedef struct qspinlock {
union {
atomic_t val;
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
};
} arch_spinlock_t;
struct qspinlock包含了三个主要部分:
locked(0- 7bit):表示是否持有锁,只有1和0两个值,1表示某个CPU已经持有锁,0则表示没有持有锁。pending(8bit):作为竞争锁的第一候补,第1个等待自旋锁的CPU只需要简单地设置它为1,则表示它成为第一候补,后面再有CPU来竞争锁,则需要创建mcs lock节点了;为0则表示该候补位置是空闲的。tail(16-31bit): 通过这个域可以找到自旋锁队列的最后一个节点。又细分为:tail cpu(18-31bit):来记录和快速索引需要访问的mcs_spinlock位于哪个CPU上,作用类似于页表基址。tail index(16-17bit):用来标识当前处在哪种context中。Linux中一共有4种context,分别是task, softirq, hardirq和nmi,1个CPU在1种context下,至多试图获取一个spinlock,1个CPU至多同时试图获取4个spinlock。当然也表示嵌套的层数。对应per-cpu的mcs_spinlock的数组(对应下文的struct mcs_spinlock mcs_nodes[4])的下标,作用类似于类似于页表内的偏移。
struct mcs_spinlock
mcs_spinlock的数据结构如下:
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
int count; /* nesting count, see qspinlock.c */
};
struct qnode {
struct mcs_spinlock mcs;
};
static DEFINE_PER_CPU_ALIGNED(struct mcs_spinlock, mcs_nodes[4]);
使用per-cpu的struct mcs_spinlock mcs_nodes[4],可以用来减少对cacheline的竞争。数组数量为4前文已经解释过了。struct mcs_spinlock具体含义如下:
locked:用来通知这个CPU你可以持锁了,通过该域完成击鼓传花,当然这个动作是上一个申请者释放的时候通知的。count:嵌套的计数。只有第0个节点这个域才有用,用来索引空闲节点的。next:指向下一个锁的申请者,构成串行的等待队列的链表。
6.3 加锁实现
核心逻辑概述
我们把一个qspinlock对应的**( tail, pending, locked)称为一个三元组(x,y,z)**,以此描述锁状态及其迁移,有2中特殊状态:
初始状态(无申请者竞争):(0, 0, 0)
过渡状态(类似于皇帝正在传位给太子,处于交接期):(0, 1, 0)
按加锁原有代码只有慢速路径和非慢速路径,我们为了行文方便,将源代码的慢速路径又分为中速路径和慢速路径,这样就有以下三组状态:
| 不同路径 | 出现情况 | 核心功能所在的函数和使用锁的种类 |
|---|---|---|
| 快速路径 | 锁没有持有者,locked位(皇位)空缺 | queued_spin_lock,使用qspinlock |
| 中速路径 | 锁已经被持有,但pending位(太子位)空缺 | queued_spin_lock_slowpath,使用qspinlock |
| 慢速路径 | 锁已经被持有,locked位和pending位都没空缺 | queued_spin_lock_slowpath,使用mcs_spinlock |
核心逻辑就变成:
如果没有人持有锁,那我们进入快速路径,直接拿到锁走人,走之前把
locked位(皇位)标记成已抢占状态。期间,只需要使用qspinlock。如果有人持有锁(抢到了皇位成为皇帝),但
pending位(太子位)空缺,那我们先抢这个位置,进入的是中速路径,等这个人(皇帝)释放锁(传位)了,我们就可以拿到锁了。期间,只需要用到qspinlock。如果这两个位置我们都抢不到,则进入慢速路径,需要使用per-cpu的
mcs_spinlock。
总体状态流程图如下:
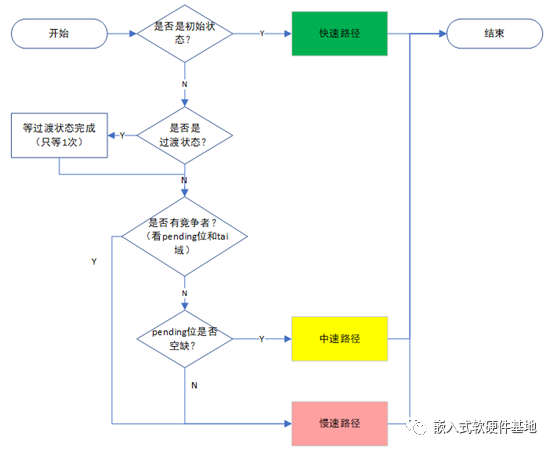
梳理一下对应伪码描述:
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
if (初始状态){ //没人持锁
//进入快速路径
return;}
queued_spin_lock_slowpath(lock, val); //进入中速或者慢速路径
}
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val) //lock是原始锁,val是之前拿到的lock->val的值
{
//代码片段1:过渡状态判断:看是否处于过渡状态,尝试等这个状态完成
//代码片段2:慢速路径判断:看是否有其他申请者竞争,则直接进入慢速路径的核心片段
//代码片段3:中速路径
queue:
//代码判断4:慢速路径
//1. 调用__this_cpu_inc(mcs_nodes[0].count)将当前cpu竞争锁的数量+1
//2. mcs node的寻址和初始化
//3. 调用queued_spin_trylock(),看看准备期间spinlock是不是已经被释放了
//4. 处理等待队列已经有人的情况,重点是arch_mcs_spin_lock_contended();
//5. 处理我们加入队列就是队首的情况
locked:// 已经等到锁了
//6.处理我们是队列最后一个节点的情况
//7.处理我们前面还有节点的情况
//8.调用arch_mcs_spin_unlock_contended()通知下一个节点
release:
//9.__this_cpu_dec(mcs_nodes[0].count);
}
下面我们开始分析
queued_spin_lock和queued_spin_lock_slowpath函数的实现细节。
实现细节分析
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
u32 val;
val = atomic_cmpxchg_acquire(&lock->val, 0, _Q_LOCKED_VAL); //1
if (likely(val == 0)) //2
return;
queued_spin_lock_slowpath(lock, val); //3
}
通过
atomic_cmpxchg_acquire,与之前的cmpxchg类似,用原子操作实现:将val赋值为lock->val。
lock->val值如果为0(没人拿到锁),将lock->val的值设为1(即*_Q_LOCKED_VAL*),三元组状态由**( tail, pending, locked)**= (0, 0, 0)迁移为(0, 0, 1)。
lock->val值如果不为0,保持lock->val的值不变。
如果当前没有人获得锁,直接拿到锁返回。三元组的状态迁移已经在上一步完成了。否则需要继续往下,走中速/慢速路径。
进入中速/慢速路径,调用
queued_spin_lock_slowpath函数
快速路径
lock->val值==0(没人拿到锁),三元组状态由**( tail, pending, locked)**= (0, 0, 0)迁移为(0, 0, 1)。快速返回,不用等待。
下面进入queued_spin_lock_slowpath函数的分析,我们先分析过渡状态判断和中速路径两个代码片段:
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
/* 过渡状态判断 */
if (val == _Q_PENDING_VAL) { //0.
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,(VAL != _Q_PENDING_VAL) || !cnt--);
}
/*其他部分代码*/
}
过渡状态判断
如果三元组( tail,pending,locked)状态如果是(0, 1, 0),则尝试等待状态变为 (0, 0, 1),但是只会循环等待1次。
简单翻译一下
atomic_cond_read_relaxed语句的意思为:如果(lock->val != _Q_PENDING_VAL) || !cnt--)则跳出循环,继续往下。
中速路径

进入中速路径的前提是当前没有其他竞争者在等待队列中排队以及pending位空缺,之后我们先将pending位占住。如果已经这段期间已经有人释放了,那直接获取锁并将pending位重置为空闲,反正则要自旋等持锁者释放锁再做其他动作。
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
/* ... 过渡状态判断及处理,代码省略 */
/* ... 判断是否有pending和tail是否有竞争者,有竞争者直接进入慢速路径排队,代码省略 */
/* 中速路径开始 */
val = atomic_fetch_or_acquire(_Q_PENDING_VAL, &lock->val); //1.
if (!(val & ~_Q_LOCKED_MASK)) { //2.
if (val & _Q_LOCKED_MASK) { //3.
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK)); //4.
}
clear_pending_set_locked(lock); //5.
return; //6.
}
if (!(val & _Q_PENDING_MASK)) //7.
clear_pending(lock);
/* 中速路径结束 */
/*其他部分代码*/
}
这部分代码的核心逻辑是在竞争qspinloc的pending,即竞争太子位。进入中速路径的前提是三元组( tail,pending,locked)=(0, 0, *)
离“是否是过渡状态”和“除锁的持有者者之外是否竞争者”的判断已经过了一段时间了。需要用
atomic_fetch_or_acquire函数,通过原子操作,重新看一下锁的状态,执行了两个动作:执行完,三元组状态会从(0, 0, *)改为(0, 1, *)。
val = lock->val(成为“原始的lock->val”)
lock->val的
peding域被置位。如果原始的
lock->val的pending和tail域都为0,则表明没有pending位没有其他竞争者,即太子位空闲可以去竞争;否则,则表明有其他竞争者,不满足中速路径的条件,需要进入慢速路径。lock->val的和tail域就不用关心了。所以此时的三元状态可以使(*, 1, *)如果
locked域为1,表明位置被占着,已经有人在持锁了,我们需要跳到第4步,等锁被释放;否则,没有人持锁,皇位是空着的,我们跳到第5步,直接去上位就好了。spin等待,直到
lock->val的locked域变回0,也就是等皇位空出来。三元组状态会从(*, 1, 1) 转变为( *, 1, 0)拿到锁了,可以登基上位了,但还要做些清理工作,调用
clear_pending_set_locked,将lock->val的pending域清零以及将locked置1。即三元组状态由(*, 1, 0) 转变为( *, 0, 1)。结束,提前返回。
如果没有进入中速路径,第1步开始时获得的锁的状态是(n, 0, *) ,需要把在第一步设置的现在锁的
pending域恢复成0。
慢速路径
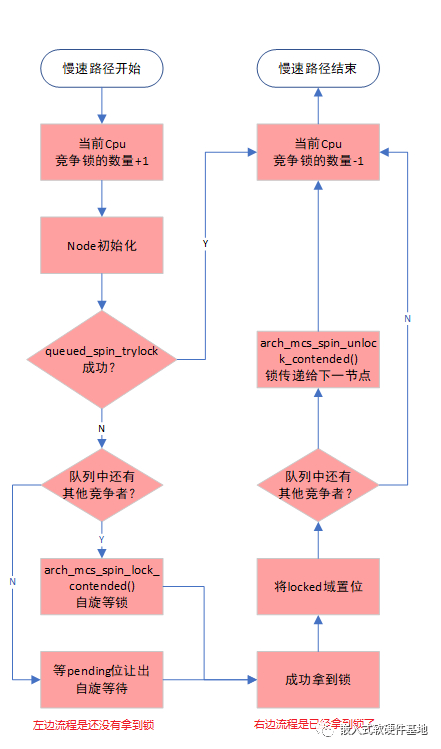
上面流程图有些地方不太准确,但没有关系,可以先帮我们建立起总体流程印象,细节后续我们会展开。
在拿到mcs lock的空闲节点之后,我们先用queued_spin_trylock函数,检查一下在我们准备的这段时间里,是不是已经有人释放了该锁了,如果有人释放了,就提前返回了。
获得锁之前,要分两种情况分别处理:
如果队列中只有我们,那只用自旋等lock的
pending位空出来即可。如果队列中还有其他竞争者在排在我们前面,则需要自旋等前序节点释放该锁。
获得锁之后,也要分两种情况处理:
如果队列中只有我们,将锁的
locked位置位,表明锁已经被我们持有了,不需要再做其他处理。如果队列中还有其他竞争者在排在我们后面,则需要将锁传递这位竞争者,当然需要要等它正式加入。
慢速路径的简化代码如下所示:
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 old, tail;
int idx;
/* ... 过渡状态判断及处理,省略 */
/* 先判断是否有pending和tail是否有竞争者,有竞争者直接进入慢速路径排队 */
if (val & ~_Q_LOCKED_MASK)
goto queue;
/* 中速路径代码开始 */
val = atomic_fetch_or_acquire(_Q_PENDING_VAL, &lock->val);
if (!(val & ~_Q_LOCKED_MASK)) {
// ...中速路径处理,省略
return;
}
/* 中速路径代码结束 */
/* 之前代码的收尾清理工作 */
if (!(val & _Q_PENDING_MASK))
clear_pending(lock); //将pending状态恢复。
//慢速路径代码开始位置
queue://进入mcs lock队列
node = this_cpu_ptr(&mcs_nodes[0]); //1.
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
node += idx; //2.
barrier();
node->locked = 0;
node->next = NULL;
if (queued_spin_trylock(lock)) //3.
goto release;
smp_wmb();
old = xchg_tail(lock, tail); //4.
next = NULL;
if (old & _Q_TAIL_MASK) { //5.
prev = decode_tail(old); //6.
WRITE_ONCE(prev->next, node); //7.
arch_mcs_spin_lock_contended(&node->locked); //8.
next = READ_ONCE(node->next); //9.
if (next)
prefetchw(next);
}
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK)); //10.
locked:
if (((val & _Q_TAIL_MASK) == tail) && //11.
atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release; /* No contention */
set_locked(lock); //12.
if (!next) //13.
next = smp_cond_load_relaxed(&node->next, (VAL));
arch_mcs_spin_unlock_contended(&next->locked); //14.
release:
__this_cpu_dec(mcs_nodes[0].count); //15.
}
之前是进入queued_spin_lock_slowpath函数,有“是否过渡状态的判断”及处理,“是否要进入慢速路径的判断”及处理,如果进了中速路径的处理。下面正式进入慢速路径的处理。因为系统可能有多个cpu并发,即使在同一个cpu上也可能切换了4种context上下文的中一种,说不定大家竞争的锁已经都被释放了也说不准,所以此时三元组的状态是未知的。
获得local CPU上的第0个节点
mcs_spinlock类型的node节点,并将节点的count值+1,count值记录了local CPU上空闲节点的起始下标,该值也只在第0个有意义。encode_tail函数,节点编号编码成tail(2bit的tail index和14bit的tail cpu),同时还完成:区分到底是tail域没有指向任何节点,还是指向了第0个CPU的第0个节点。
检查当前CPU上自旋锁嵌套的层数是否超过4层。
根据idx取到取到空闲节点,相当于node = mcs_nodes[idx]。这里有
barrier保序,防止编译器优化。然后对空闲节点进行初始化。调用
queued_spin_trylock函数,检查一下在我们准备的这段时间里,是不是已经有人释放了该锁了。如果成功获得锁,则直接跳到lable release处;否则,继续往下。queued_spin_trylock函数的作用具体来讲是这样:连续两次使用原子操作检查锁的状态:如果val为0(对应三元组(0, 0, 0))并且再次读取val的
locked域也为0,则表示可以获得锁。上文说过,此时锁的状态是未知的。在调用
xchg_tail函数之前,有smp_wmb内存屏障,保证tail值获得的正确性。该函数将lock->tail设置为新生成的tail值,并将旧的值存在old中。如果旧的tail为0,说明队列里只有我们这个新生成的节点,直接跳到第10步;否则继续往下执行
通过旧的tail拿到等待队列的尾结点
prev。将当前节点插入等待队列,作为新的尾节点。
自旋等待本节点的
locked域变为1。在local CPU上自旋等待自己的locked成员被置位。arch_mcs_spin_lock_contended在arm64上最终会调用__cmpwait_case_##name宏,展开后同arm64的tick spinlock的arch_spin_lock的实现类似。核心功能都是在自旋时执行WFE节省部分能耗。后面3行代码,是看下在我们后面是否还有其他人在排队,如果有的话,使用
prfm指令,提前将相关值预取到local CPU的cache中,加速后续的执行。使用原子操作重新获取
lock->val的值,并且循环等到直到pending和locked都为0。三元组( tail, pending, locked)的值为(*, 0, 0),也就是说需要等到皇位和太子位都是空闲的状态才是我们真正获得了锁的条件。如果tail还是我们设置的,说明我们同时是等待队列的最后一个节点或者说是唯一节点,后面没人在排队了。通过
atomic_try_cmpxchg_relaxed原子的将locked域设置为1,至此才真正完成了锁的合法拥有,直接跳到最后1步。三元组的状态迁移是(n, 0, 0) --> (0, 0, 1)。否则,如果tail发生了改变,说明后面还有节点或者pending位被占,则继续往下处理。先将
locked设置为1。三元组的状态迁移是(*, *, 0) --> (*, 0, 1)。等待的下一个节点还有正式加入进来,则需要等next变成非空(非空才真正了完成加入)。
调用
arch_mcs_spin_unlock_contended,将下一个节点的locked值设置成1 ,完成了锁的传递。也就是完成了击鼓传花。释放本节点。
6.4 解锁实现
static __always_inline void queued_spin_unlock(struct qspinlock *lock)
{
smp_store_release(&lock->locked, 0);
}
将qspinlock的locked清零即可。
【参考资料】
1. 【原创】linux spinlock/rwlock/seqlock原理剖析(基于ARM64)
2. 宋宝华:几个人一起抢spinlock,到底谁先抢到?
3. Linux内核同步机制之(四):spin lock,蜗窝科技
4. Linux中的spinlock机制[一] - CAS和ticket spinlock,兰新宇,知乎