
对象很大,你忍一下
你好,我是坤哥
上一篇Java 进阶之字节码剖析中我曾经提到这么一段话
int[128][2] ,int[256] 这两个数组看起来一样,但实际上前者比后者多了 246% 的额外开销
针对这句话我收到了几位读者的私信,表示不明白为啥不过一个简单的二维数组会有这么大的开销,本来这个问题在我正在写的类加载机制中有详述,不过文章还没写完(估计本周发),所以我专门抽出这个问题探讨一下,五分钟就能看懂
Java 对象模型
HotSpot JVM 底层使用名为 oops (Ordinary Object Pointers) 的数据结构来表示对象的对象头
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
...
}
JVM 每创建一个对象,相当于创建了一个 oopDesc 的对象,即 instanceOopDesc 来表示这个对象,保存在堆中,如下图所示
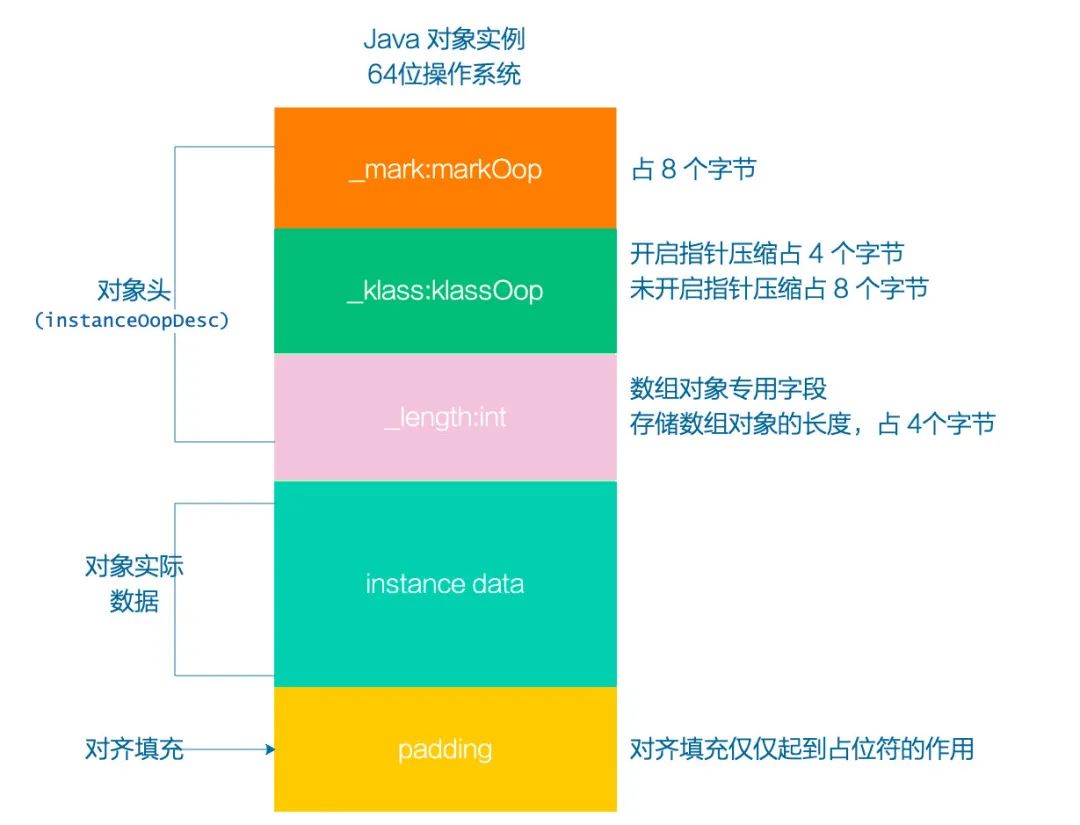
可以看到 Java 对应主要由以下三部分组成
对象头(Header)
对象实例数据(instance data)
对齐填充(Padding)
其中对象头又包含三个部分
markWord: 即 _mark:markOop,用于存储对象运行时的数据,好比 HashCode、锁状态标志、GC分代年龄等。这部分在 64 位操作系统下占 8 字节,32 位操作系统下占 4 字节
指针:指向方法区中的类元数据(类信息)的指针,这部分就涉及到指针压缩的概念,在开启指针压缩的状况下占 4 字节,未开启状况下占 8 字节,默认是开启的
数组长度:这部分只有是数组对象才有,若是非数组对象就没这部分。这部分占 4 字节。
除此之外对象还有两个部分值得我们注意
对象实例数据(instanceData): 用于存储对象中的各种类型的字段信息(包括从父类继承来的)
对齐填充:Java 对象大小默认按 8 字节对齐的,如果「对象头」+「对象实际数据」不足8的位数,对齐填充会补齐相应的字节以让对象大小达到 8 的倍数
Java 数组大小
知道了对象模型的表示,再来看数组的大小,首先必须明确两点
在 Java 中数组是一种特殊的对象(也是对象,也有对象头)
一个多维数组是一个简单数组的数组, 例如,一个二维数组的每一行都是一个独立的数组对象
接下来我们来看看一维数组 int[256] 在内存中有多大,一维数组其实可以认为是普通的对象,首先对象头可以知道是 8(markword) + 4(kclass) + 4(数组长度)= 16 字节,对象实际数据大小为 256 * 4(int 大小为 4 个字节) = 1024 字节,所以此时总的字节数为 16 + 1024 = 1040 字节,是 8 的位数(1040/8 = 130),所以 padding 为 0, 也就是说 int[256] 一维数组的字节大小为 1040 字节
再来看一下二维数组 int[128][2] 的大小,我们知道在 C 语言中二维数组(事实上是任何多维数组)本质上是一维数组通过指针操作来实现的,但在 Java 中多维数组是由一系列的嵌套数组组成,也就是说对于二维数组而言,每一行(int[0][…],int[1][…],…,int[127][…])都对应一个数组对象,都需要额外的开销,一图胜千言,如下所示
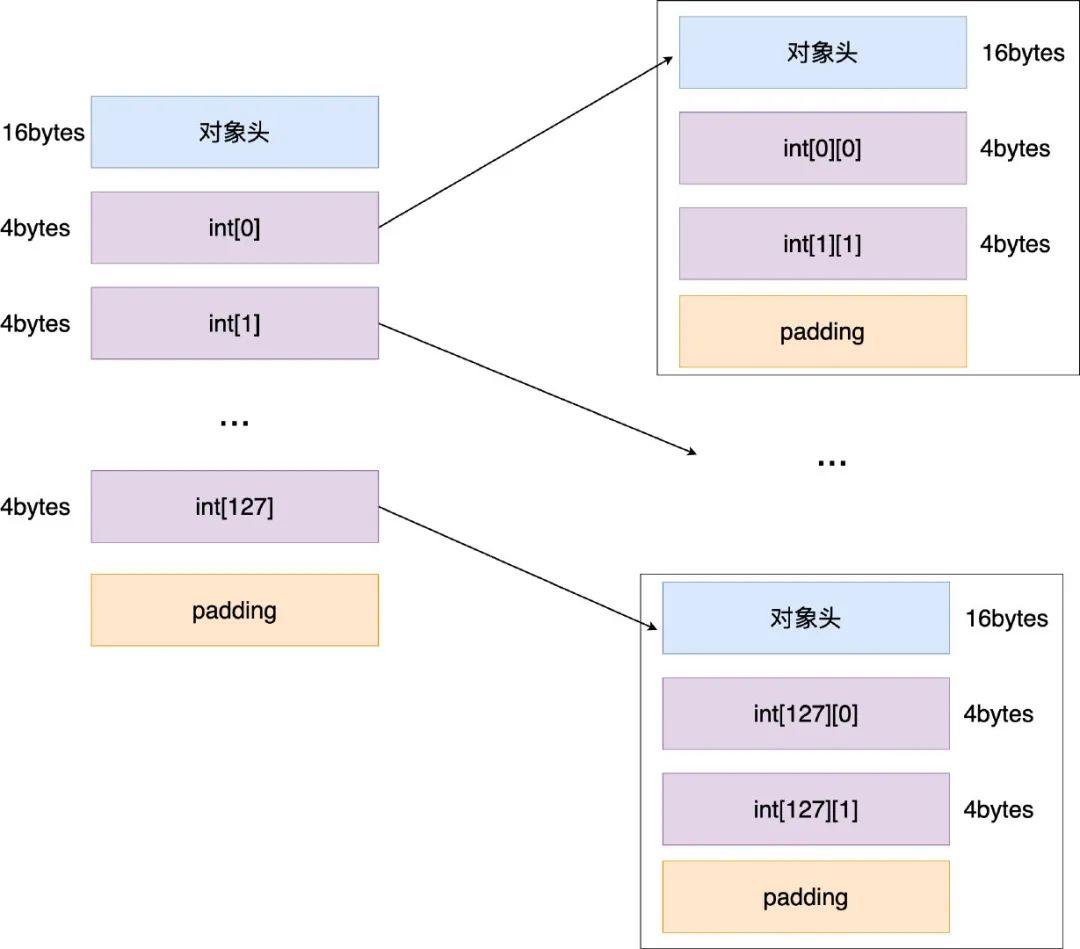
先来看左边的对象大小:
数组的每一行 int[0],int[1],..int[127] 其实都是指向数组的指针,为 4 个字节,所以左边对象占用空间大小为 16 + 4 * 128 = 528,是 8 的倍数(528/8 = 66),所以 padding 为 0,所以总大小为 528
再来看左边的 int[0] 等指向的数组对象大小:
由于左边每个行数组的指向都指向了两个元素的数组(int[x][0],int[x][1]),它们的对象大小为 16 + 4 + 4 = 24,是 8 的倍数,所以 padding 为 0 ,而总共有 128 个这样的对象,所以右边总的对象大小为 128 * 24 = 3072
由此可知 int[128][2] 对象大小为 528 + 3072 = 3600 字节,比一维数组 int[256](1024 字节)多了 246% !
上述计算的是否正确呢,我们可以用 JDK 自带的 ObjectSizeCalculator 来计算一下,如下:

与我们的计算结果完全一致!
其实不光是二维数组,包括字节串,普通的对象开销也一般会比对象实际数据大几倍,到此我相信你不难明白上一篇中开头这样一段话的含义了:kafka 中为啥要使用 pageCache 了, 因为如果不用页缓存,而是用 JVM 进程中的缓存,对象的内存开销会非常大(通常是真实数据大小的几倍甚至更多)
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。