
爆火的分布式数据库,到底是个啥?
免责声明~
任何文章不要过度深思!
万事万物都经不起审视,因为世上没有同样的成长环境,也没有同样的认知水平,更「没有适用于所有人的解决方案」;
不要急着评判文章列出的观点,只需代入其中,适度审视一番自己即可,能「跳脱出来从外人的角度看看现在的自己处在什么样的阶段」才不为俗人。
怎么想、怎么做,全在乎自己「不断实践中寻找适合自己的大道」
1 啥是分布式DB?
随着TiDB等分布式DB的兴起,关系型DB也逐渐增加了分布式特性。在这些分布式DB中,数据分片和分布式事务是内置的基础功能,使业务开发人员能够像使用传统关系型DB一样简便地使用JDBC接口。作为一种分布式DB中间件,shardingSphere除了提供标准化的数据分片解决方案外,还实现了分布式事务和DB治理功能。让我们一起探索这些强大的工具如何提高数据管理和操作的效率!
事实标准
当一款技术产品占据市场主导地位时,它就成为同类产品的标杆。就像关系型数据库中,Oracle成为了事实标杆,因为所有新版本的数据库产品都要和Oracle进行对比,比较各自的特性。这样一来,Oracle就拥有更多的用户和支持,而其他竞争对手则需要不断改进自己的产品才能与之匹敌。
2 外部视角:外部特性
分布式 DB具备啥特性,能解决啥痛点。
业务应用系统按交易类型分类:
-
联机交易(OLTP)
面向交易的处理过程,单笔交易的数据量小,但是要在很短的时间内给出结果,典型场景包括购物、缴费、转账等
-
联机分析(OLAP)
通常是基于大数据集的运算,典型场景包括生成个人年度账单和企业财务报表等。
难有一款产品中完全满足两者,因此在单体DB时代演化出两个不同技术体系,即两类不同的关系型DB。向分布式架构演进后,两者在架构设计也采用完全不同策略,很难在一个框架下说清。
先专注讨论OLTP场景下的分布式 DB。本教程所提“ DB”都默认“关系型DB”,分布式DB也都指支持关系模型的分布式DB。即不讨论NoSQL,整体看,关系型DB由于支持SQL、提供ACID事务,具有更好通用性,在更广泛场景中无法被NoSQL取代。通过NoSQL十余年来发展已被证实。
分布式DB目标正是融合传统关系型 DB与NoSQL DB的优势,而且已经取得不错效果。
3 定义
3.1 OLTP关系型 DB
仅用“OLTP场景”作为定语显然不够精准,我们来进一步看看OLTP场景具体的技术特点。
OLTP场景的通常有三个特点:
- 写多读少,指请求数量。而且读操作的复杂度较低,一般不涉及大数据集的汇总计算
- 低延时,用户对于延时的容忍度较低,通常在500毫秒以内,稍微放大一些也就是秒级,超过5秒的延时通常是无法接受的;
- 高并发,并发量随着业务量而增长,没有理论上限。
我们是不是可以有这样一个结论:分布式 DB是服务于写多读少、低延时、高并发的OLTP场景的 DB。
3.2 海量并发
你可能会说这个定义有问题,比如MySQL和Oracle这样的关系型 DB也是服务于OLTP场景的,但它们并不是分布式 DB。
相对传统关系型 DB,分布式 DB最大差异就是分布式 DB远高于前者的并发处理能力。
传统关系型 DB往往是单机模式,主要负载运行在一台机器。DB的并发处理能力与单机的资源配置是线性相关的,所以并发处理能力的上限也就受限于单机配置的上限。这种依靠提升单机资源配置来扩展性能的方式,即垂直扩展(Scale Up)。
在一台机器中,随随便便就能多塞进些CPU和内存来提升提性能吗?当然没那么容易。所以,物理机单机配置上限的提升是相对缓慢的。即在一定时期内,依赖垂直扩展的 DB总会存在性能的天花板。很多银行采购小型机或大型机的原因之一,就是相比x86服务器,这些机器能够安装更多的CPU和内存,可以把天花板推高一些。
而分布式 DB不同,在维持关系型 DB特性不变的基础上,它通过水平扩展增加机器数量,提供远高单体 DB的并发量。这个并发量几乎不受单机性能限制,我将这个级别的并发量称为“海量并发”。
“海量并发”到底多大
没权威数字。虽然理论上是可以找一台世界上最好的机器来测试一下,但考虑到商业因素,这个数字不会有什么实际价值。不过,我可以给出一个经验值,这个“海量并发”的下限大致是10,000TPS。
2.0版本的定义:分布式 DB是服务于写多读少、低延时、海量并发OLTP场景的关系型 DB。
3.3 +高可靠
2.0版仍有问题。是不是没有海量并发需求,就不需要使用分布式 DB了呢?不是的,你还要考虑 DB的高可靠性。
一般来说,可靠性是与硬件设备的故障率有关的。
与银行不同,很多互联网公司和中小企业通常是采用x86服务器的。x86服务器有很多优势,但故障率会相对高一些,坊间流传的年故障率在5%左右。
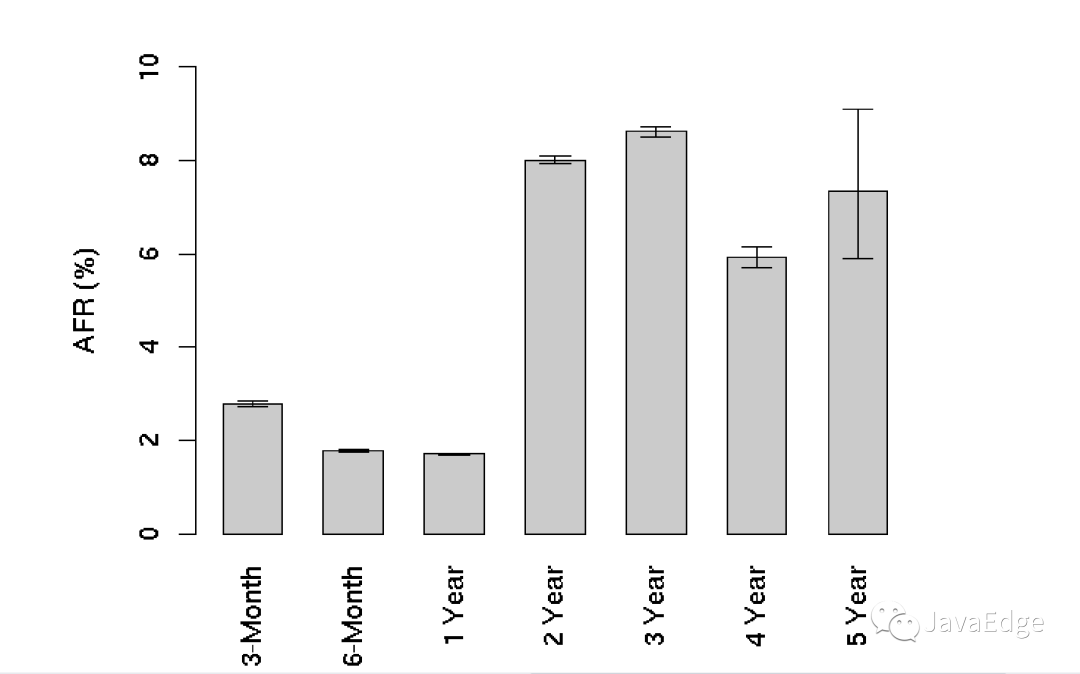
一些更加可靠的数据来自Google的论文Failure Trends in a Large Disk Drive Population,文中详细探讨了通用设备磁盘的故障情况。它给出的磁盘年度故障率的统计图,如下所示:
 img
img可以看到,前三个月会超过2%的磁盘损坏率,到第二年这个数字会上升到8%左右。
你可能会说,这个数字也不是很高啊。
但你要知道,对金融行业的关键应用系统来说,通常是要求具备5个9的可靠性(99.999%),也就是说,一年中系统的服务中断时间不能超过5.26分钟(365*24*60*(1-99.999%) ≈ 5.26 )。
而且,不只是金融行业,随着人们对互联网的依赖,越来越多的系统都会有这样高的可靠性要求。
根据这两个数字,我们可以设想一下,如果你所在的公司有四、五个关键业务系统,十几台 DB服务器,磁盘数量一定会超过100个吧?那么我们保守估计,按照损坏率2%来算,一年中就会碰到2次磁盘损坏的情况,要达到5个9的可靠性你就只有5.26分钟,能处理完一次磁盘故障吗?这几乎是做不到的,可能你刚冲到机房,时间就用完了。
我猜你会建议用RAID(独立冗余磁盘阵列)来提高磁盘的可靠性。这确实是一个办法,但也会带来性能上的损耗和存储空间上的损失。分布式 DB的副本机制可以比RAID更好地平衡可靠性、性能和空间利用率三者的关系。副本机制就是将一份数据同时存储在多个机器上,形成多个物理副本。
回到 DB的话题上,可靠性还要更复杂一点,包括两个度量指标,恢复时间目标(Recovery Time Objective, RTO)和恢复点目标(Recovery Point Objective, RPO)。RTO是指故障恢复所花费的时间,可以等同于可靠性;RPO则是指恢复服务后丢失数据的数量。
DB存储着重要数据,而金融行业的 DB更是关系到客户资产安全,不能容忍任何数据丢失。所以, DB高可靠意味着RPO等于0,RTO小于5分钟。
传统上,银行通过两种方法配合来实现这个目标。
第一种还是采购小型机和大型机,因为它们的稳定性优于x86服务器。
第二种是引入专业存储方案,例如EMC的Symmetrix远程镜像软件(Symmetrix Remote Data Facility, SRDF)。DB采用主备模式,在高端共享存储上保存 DB文件和日志,使 DB近似于无状态化。主库一旦出现问题,备库启动并加载共享存储的文件,继续提供服务。这样就可以做到RPO为零,RTO也比较小。
但是,这套方案依赖专用的软硬件,不仅价格昂贵,而且技术体系封闭。在去IOE(IBM小型机、Oracle DB和EMC存储设备)的大背景下,我们必须另辟蹊径。分布式 DB则是一个很好的备选方案,它凭借节点之间的互为备份、自动切换的机制,降低了x86服务器的单点故障对系统整体的影响,提供了高可靠性保障。
令人兴奋的是,这种单点故障处理机制甚至可以延展到机房层面,通过远距离跨机房部署。如此一来,即使在单机房整体失效的情况下,系统仍然能够正常运行, DB永不宕机。
3.0定义,分布式 DB是服务于写多读少、低延时、海量并发OLTP场景的,高可靠的关系型 DB。
3.4 海量存储
虽然单体 DB依靠外置存储设备可以扩展存储能力,但这种方式本质上不是 DB的能力。现在,借助分布式的横向扩展架构,通过物理机的本地磁盘就可以获得强大的存储能力,这让海量存储成为分布式 DB的标配。
最后,我们终于得到一个4.0终极版本的定义,分布式 DB是服务于写多读少、低延时、海量并发OLTP场景的,具备海量数据存储能力和高可靠性的关系型 DB。
4 内部视角:内部构成
具有相同的外在特性和功效,未必就是同样的事物。
“日心说”反驳“地心说”要用到34个圆周解释天体运动轨迹;而100多年后,开普勒只用7个椭圆就达到同样效果,彻底摧毁“地心说”。从哥白尼到开普勒,效果近似,简洁程度大不一样,这背后代表的是巨大科学进步。
因此,讲完外部特性,还要从内部视角观察。
为应对海量存储和海量并发,很多解决方案在效果上跟V4定义相似。但它们向用户暴露了太多的内部复杂性。用户约束太多、使用过程太复杂、不够内聚的方案,不能称为成熟产品。同时,业界的主流观点并不认为它们是分布式 DB。
来看分类:
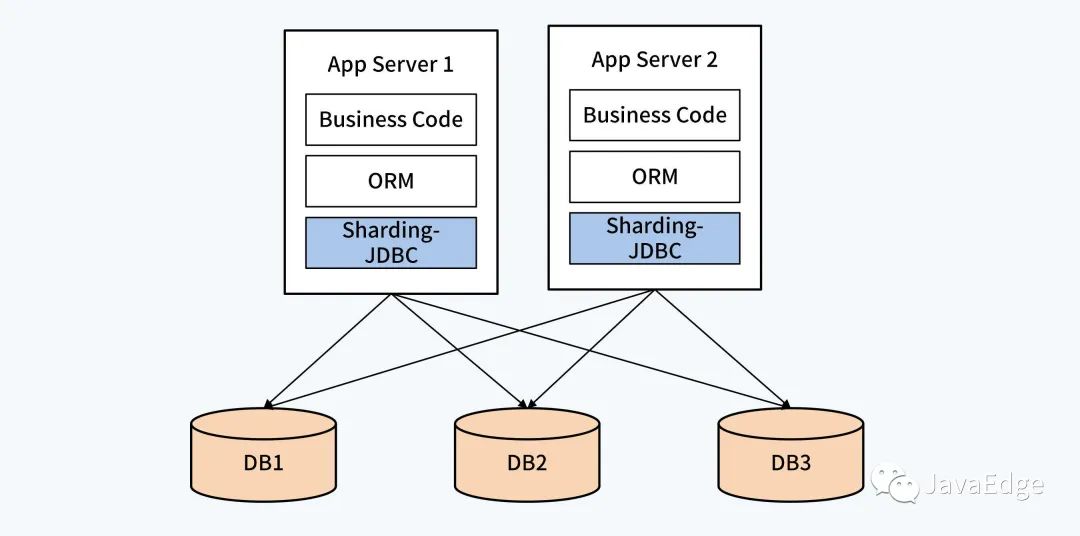
4.1 客户端组件 + 单体 DB
通过独立的逻辑层建立数据分片和路由规则,实现单体 DB的初步管理,使应用能够对接多个单体 DB,实现并发、存储能力的扩展。其作为应用系统的一部分,对业务侵入比较深。
这种客户端组件的典型产品是Sharding-JDBC。
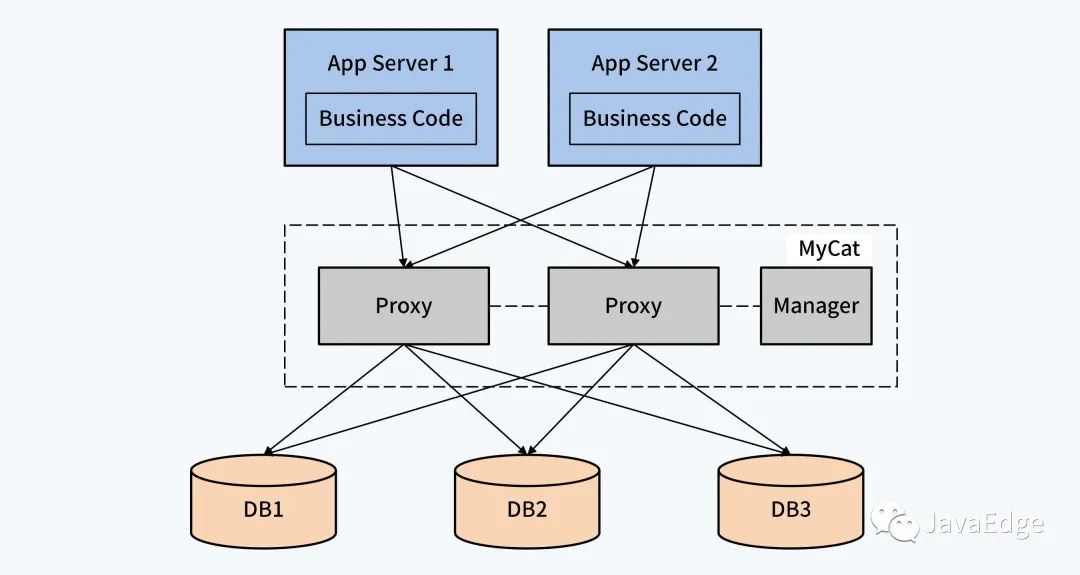
4.2 代理中间件 + 单体 DB
以独立中间件的方式,管理数据规则和路由规则,以独立进程存在,与业务应用层和单体 DB相隔离,减少了对应用的影响。随着代理中间件的发展,还会衍生出部分分布式事务处理能力。
这种中间件的典型产品是MyCat。
 img
img4.3 单元化架构 + 单体 DB
单元化架构是对业务应用系统的彻底重构,应用系统被拆分成若干实例,配置独立的单体 DB,让每个实例管理一定范围的数据。例如对于银行贷款系统,可以为每个支行搭建独立的应用实例,管理支行各自的用户,当出现跨支行业务时,由应用层代码通过分布式事务组件保证事务的ACID特性。
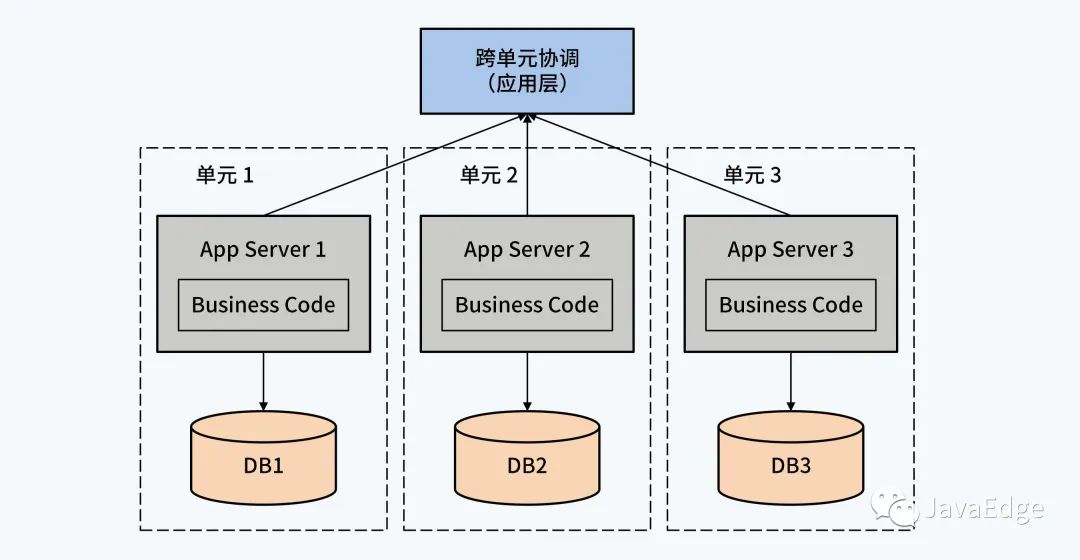
根据不同的分布式事务模型,应用系统要配合改造,复杂性也相应增加。例如TCC模型下,应用必须能够提供幂等操作。
在分布式 DB出现前,一些头部互联网公司使用过这种架构风格,该方案的应用系统的改造量最大,实施难度也最高。
共同的特点是单体DB仍能够被应用系统感知到。相反,分布式 DB则是将技术细节收敛到产品内部,以一个整体面对业务应用。
分布式 DB的内部架构到底长什么样?它跟这三种方案有什么区别呢?敬请期待系列教程后文。
5 亚马逊的Aurora
和这里说的分布式DB有明显差别,了解Aurora或同类产品吗?和本文分布式DB差异在哪?为啥会有这种差异?
为啥说Aurora不是分布式DB?Aurora存算分离,使亚马逊云存储服务更高效、易使用。算是NewSQL中比较成功的了。
特点
Aurora是提出一种新的单体架构以减少网络IO和同步阻塞,逻辑上可以看做一个庞大的单体 DB,用分布式来支持容错和高吞吐量。:
-
Aurora分片的方式是将 DB的总容量划分为固定大小的数据段,在每一段内存储数据,每一个段是一组机器(六个),个人觉得算支持分片
-
写多读少、低延时这就是Aurora所重点的做的事情,通过log is database和支持异步来实现
-
海量存储可靠堆机器(当然这些机器肯定是有一个控制中心来管理的,论文中没有提)
-
高可靠则是靠每一个数据段把数据冗余到三个可用区的六台机器
-
而且它同样也是关系型DB
但Aurora特点是Share storage,计算节点垂直扩展,存储节点水平扩展,写入性能收单机资源的影响。
投票机制
aurora也用到了,6个副本,半数以上就确认写入成功。但无分片,不能多写,肯定不算分布式。
不能多写(重点!),适用场景有很大区别,所以这是个重要标准。但因为Aurora是基于共享存储,所以说它是分布式也不是没道理。定标准只是为让学习思路清晰。
实际场景Aurora和分布式存储的应用的差别
Aurora还是关系型 DB,而分布式存储系统范围较广,比如HBase这样的分布式键值系统。两者在功能上有很大差异。
AWS aurora,阿里polarDB,腾讯CynosDB,华为的Taurus等产品都是类似架构:计算存储分离。所有计算节点都访问存储节点上的同一份数据,也可以说是分布式架构。这架构的局限是写入不能横向扩展,对很多小规模应用够了,所以不影响它取得商业成功。
阿里的PolarDB是分布式DB?它采用哪种方案?
PolarDB和Aurora架构类似,存算分离,计算节点垂直扩展,存储节点水平扩展。代表其写入能力有上限,但因简化了日志存储和其他一些优化,单点能力比普通MySQL强很多。
6 总结
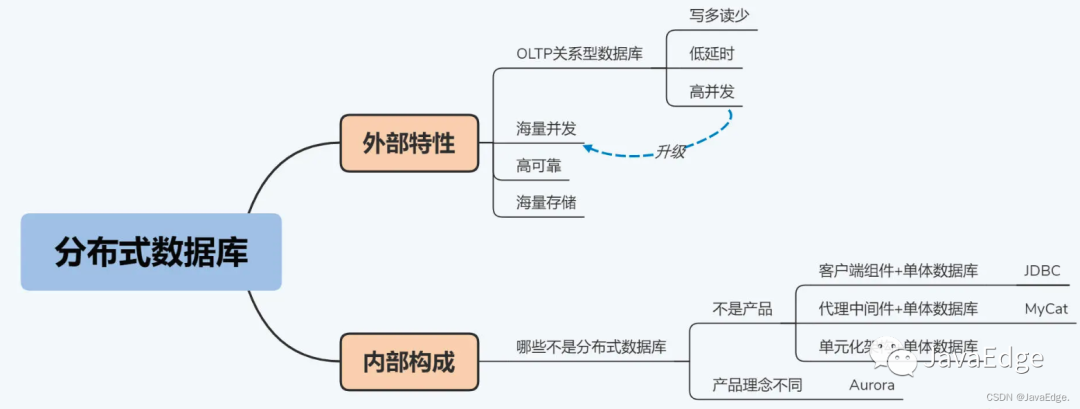
逐层递进,勾勒出分布式 DB的六个外部特性:写多读少、低延时、海量并发、海量存储、高可靠性、关系型 DB。
也存在一些与分布式 DB能力近似解决方案,它们不足之处是都需要对应用系统进行一定的改造,对应用的侵入程度更深;其优势则在于可以最大程度利用单体 DB的稳定可靠,毕竟这些特性已经历经无数次的考验。
分布式DB的名称做一些延伸。
“分布式 DB”在字面上可以分解为“分布式”和“ DB”两部分,代表了它是跨学科的产物,它的理论基础来自两个领域。这同时也呼应了产品发展的两条不同路径,一些产品是从分布式存储系统出发,进而增加关系型 DB的能力;另外一些产品是从单体 DB出发,增加分布式技术元素。而随着分布式 DB的走向工业应用,在外部需求的驱动下,这两种发展思路又呈现出进一步融合的趋势。
7 FAQ
① 写多读少不应加入分布式DB的定义?
分布式DB服务写多读少应用,我觉得不管写多读多都可应用分布式,关键是单体承担不了这么多请求了(不论读写),所以高并发就够了,写多读少不应加入分布式DB的定义?
强调写多读少,是因为:
- 写操作的负载只能是单体DB的主节点,无法转移
- 而读操作,如对一致性要求不高,可转移到备节点,甚至在某些条件下还能保证一致性。就是说单体DB可通过一主多备解决读负载大问题,而无需引入分布式DB
云dbms在分布式基础上,更关注计算存储分离后可独立扩展,甚至动态扩缩容,self-driven搞起来,更好卖了。这也引发不少问题,aurora类 DB提出log is database思想,降低写压力,snowflake通过建立中间分布式换存层,降低网络瓶颈等。
② 分布式DB V.S 分库分表
分布式关系型DB,感觉就是把客户端或中间件的方案直接作为DB服务端的特性组件,把分库分表做得更自动化?
最大区别在于:
- 分布式DB使用体验很接近关系型DB,无需应用进行额外控制,大大降低业务代码开发难度
- 而分库分表方案在分布式事务和跨节点查询等方面,支持的都不好
③ MyCat这种怎么说?
随分布式DB发展,MyCat这类中间件市场会越来越小。当然,它的使用场景也可能转向对异构DB支持,就像Presto。
④ 都说互联网应用数据请求“读多写少”
所以有了一主多从读写分离、全量数据缓存等解决“读”问题的扩容手段。如果说的是同一个指标,是否意味着分布式DB不适合互联网应用?
互联网确实可通过一主多满足“读多写少”,但前提是对读对一致性要求低。而金融场景,很多读操作依然无法在备库运行,就是一致性不满足要求。所以,对互联网也不能一概而论,还是区分场景。
⑤ 交易场景下,交易代码配合分布式 DB而做出的交易补偿或者数据回放等
如需要交易代码配合做出补偿和回放,这很可能意味着它不是分布式DB。分布式DB成熟前,确有不少应用代码配合单体 DB。这类应用代码也会被抽离出来形成独立框架,如阿里SOFA。
⑥ Newsql落地如何?
如北京银行和光大银行都上线TiDB,Oceanbase也在南京银行落地。
⑦ BigTable算特殊的(代理中间件 + 单体 DB(分布式文件系统))吗?
毕竟靠Chubby作为一个中间层,不过数据的获取是直接与文件系统中交互完成。
BigTable是分布式KV系统,不属于分布式DB。因为这里所说的分布式DB是分布式架构实现的关系型DB。当然它底层依赖一个分布式文件系统,所以看上去也分两层,但职能和DB差别很大,建议关注PGXC风格分布式DB。
⑧ 基于OLAP使用场景的分布式关系型DB产品
最典型的MPP架构DB,如Greenplum和华为的GaussDB 200,内核都使用PostgreSQL。还有Vertica。OLAP不再强调事务支持,如果弱化对数据更新要求,很多大数据生态的产品都可纳入,如Clickhouse,Hive on spark,甚至Kylin都算是广义OLAP分布式DB。
end
* 版权声明: 转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。
长按识别图中二维码
关注获取更多资讯
不点关注,我们哪来故事?

点个再看,你最好看