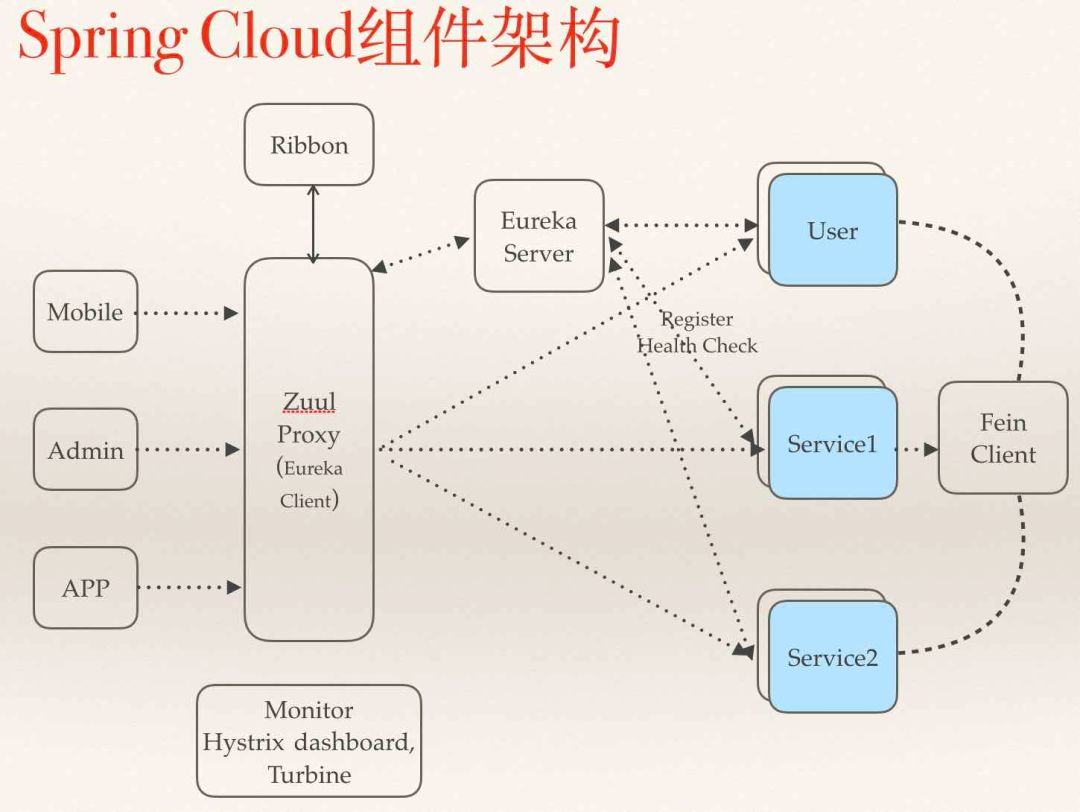
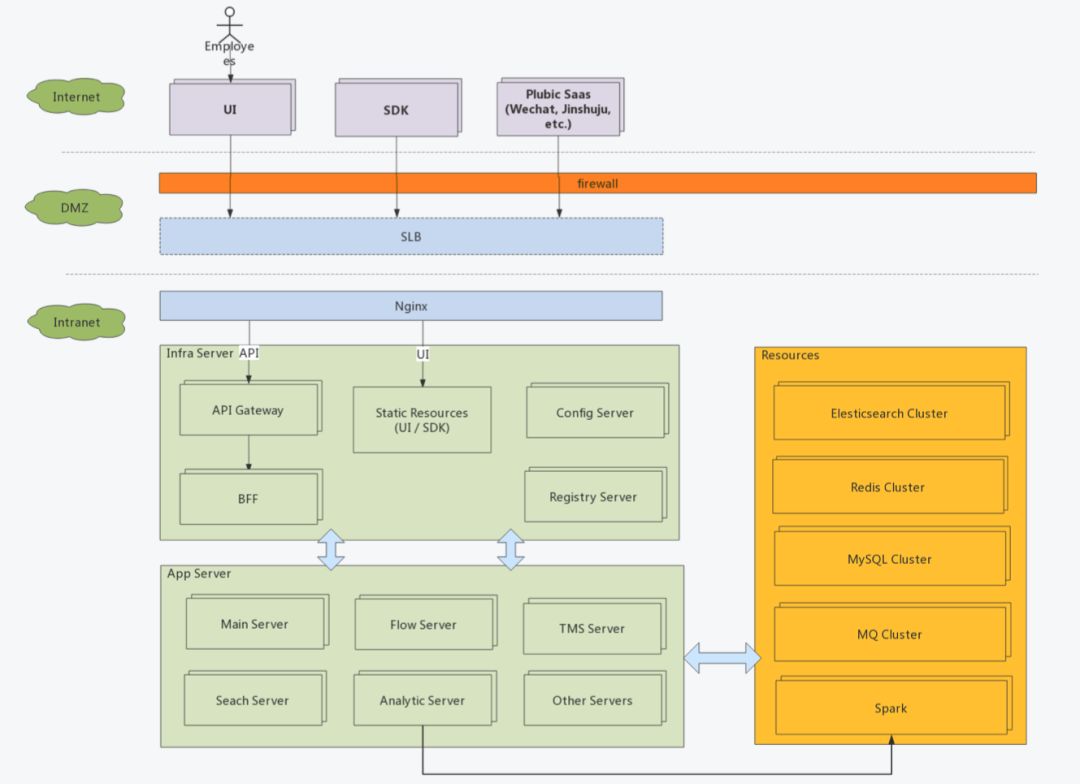
动作支持,POST / PUT / DELELE / GET ,这里有一个坑,PUT和PATCH都是更新,但是PUT是全量更新而PATCH是部分更新,前者如果传入的字段是空(未传也视为空)那么也会被更新到数据库中。目前我们虽然是使用PUT但是忽略空字段和未传字段,本质上是一种部分更新,这也带来了一些问题,比如确有置空的业务需要特殊处理。
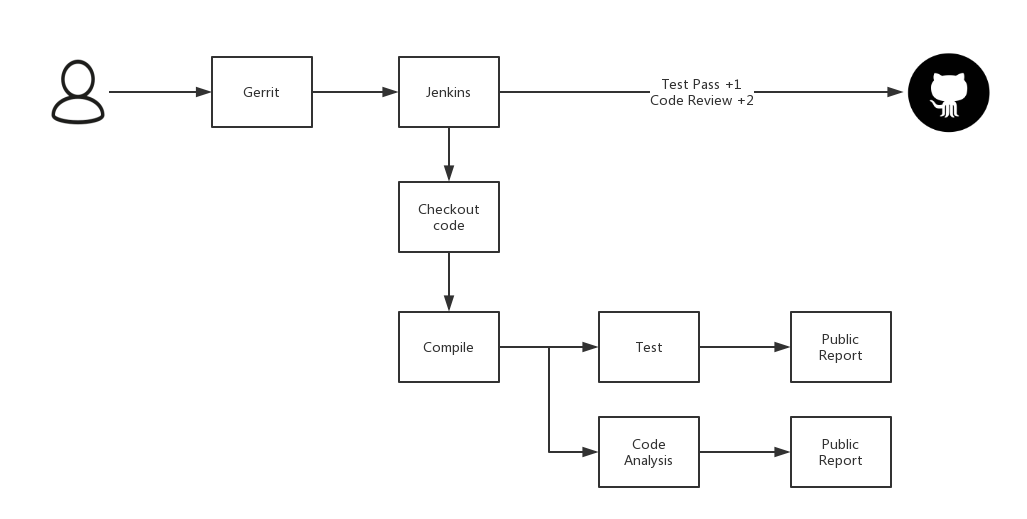
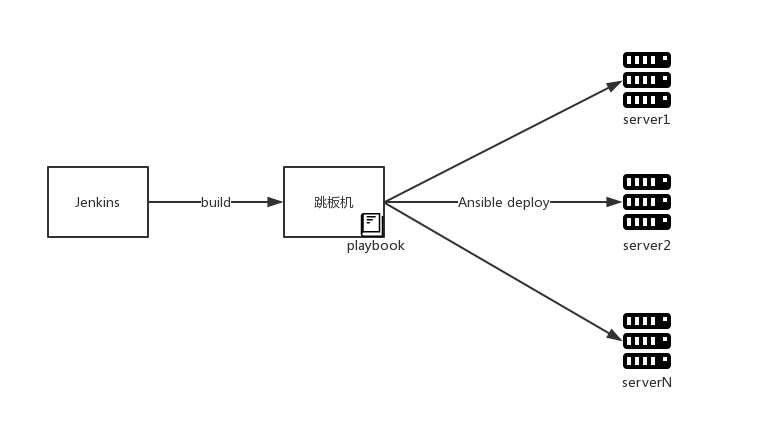
CI的改造主要是多了一部编译docker image并打包到Harbor的过程,部署时会直接从Harbor拉取镜像。另一个就是数据库的升级工具。之前我们使用flyway作为数据库升级工具,当应用启动时自动执行SQL脚本。随着服务实例越来越多,一个服务的多个实例同时升级的情况也时有发生,虽然flyway是通过数据库锁实现了升级过程不会有并发,但会导致被锁服务启动时间变长的问题。从实际升级过程来看,将可能发生的并发升级变为单一进程可能更靠谱。此外后期分库分表的架构也会使随应用启动自动升级数据库变的困难。综合考量,我们将升级任务做了拆分,每个服务都有自己的升级项目并会做容器化。在使用时,作为run once的工具来使用,即docker run -rm的方式。并且后续也支持了设定目标版本的功能,在私有化项目的跨版本升级中起到了非常好的效果。至于自动部署,由于服务之间存在上下游关系,例如config,eruka等属于基本服务被其他服务依赖,部署也产生了先后顺序。基于Jenkins做pipeline可以很好的解决这个问题。