
超大规模分布式存储系统 BigTale 介绍

作为 Google 三剑客(MapReduce、BigTable 和 GFS)之一,BigTable 来自 2006 年 Google 在 OSDI[1] 发表的同名论文 https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf。
Bigtable 是一个用于管理结构化数据的超大规模分布式存储系统。
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size.
1 介绍
用于管理结构化的数据 PB 级数据、上千台机器
实现目标:
普适性 可扩展性 高性能 高可用
Bigtable 类似数据库,但提供了不同的接口:
不支持完整的关系型数据模型;而是为客户端提供了一个简洁的数据模型,支持对数据排版与格式的动态控制 数据使用可以是任意字符串的行列名称索引 将数据视为未处理的字符串,客户端经常将各种数据结构序列化为字符串 客户端通过 Bigtable schema 参数控制从内存还是磁盘提供数据
2 数据模型
A Bigtable is a sparse, distributed, persistent multidimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.
Bigtable 是一种松散的 分布式的 持久化的 多维排序 map,由行 key、列 key 和时间戳索引,map 中的所有值都是未经处理的字节数组。

图 1 为存储了 web 页面的一张表。行名是反序的 URL,content 列包含了网页内容,anchor 列包含引用该页面的任何锚点的文本。CNN 主页同时被 Sports Illustrated 和 MY-look 主页引用了,所以 row 包含了名为 anchor:cnnsi.com 和 anchor:my.look.ca 的两列。每个 anchor 格子(cell)都有一个版本;content 列有三个版本:在时间戳 t3、t5 和 t6。
为什么这么设计?他们想要保留大量网页和相关信息的副本,可以被多个项目使用。这种特殊的表格被他们称作 _Webtable_。在 Webtable 中,以 URL 作为行 key,web 页面的多方面属性作为列 key,在 content 中存储网页内容:它们被抓取的时间戳下面的列。
2.1 行(Rows)
表中的行 key 是任意字符串,最大 64KB 按单个行 key 读写数据是原子的(atomic)
Bigtable 按行 key 以词典顺序维护数据。一张表的行范围是动态分区的。每个行范围被称作 _tablet_,它是分布和负载均衡的单位。对短行范围的读取很高效,通常只要和少数机器通信。客户端通过选择行 key 来利用这一特性,从而离它们访问的数据更近。例如在 Webtable 中,通过反转 URL 的主机名部分,将同一域中的网页分组为连续的行。他们在 key com.google.maps/index.html 下存储 maps.google.com/index.html 的数据。将来自同一域的页面存储在彼此附近,使得一些主机和域的分析更高效。
2.2 列族(Column Families)
列 key 被分组为叫做列族(_column families_)的集合,构成访问控制的基本单位。 一个列族中存储的所有数据通常类型相同。
先有列族再有数据;在创建列族后,就可以使用该列族中的任意列 key。他们设想一个表中不同的列族不要太多,而且在操作过程中列族也很少变更。
列 key 使用 family:qualifier 格式命名。例如,Webtable 的列族名是 language,存储了网页使用哪种语言。在 language 列族中只是用了一个列 key,存储每个网页的 language ID。这种表另一个很有用的列族是 anchor;这个列族中的每个列 key 代表了一种锚点(anchor),如图 1 所示。qualifier 是引用网站的名称;格子里的内容是链接文本。
2.3 时间戳(Timestamps)
Bigtable 中的每个格子(cell)能够包含相同数据的多个版本;通过时间戳(64 位整数)来索引,按时间倒序存储,这样能够先读取最近的版本。在 Webtable 案例中,设置了页面的被抓取时间。
3 API
Bigtable API 用于创建/删除/修改表和列族(column families)。
// Open the table
Table *T = OpenOrDie("/bigtable/web/webtable");
// Write a new anchor and delete an old anchor
RowMutation r1(T, "com.cnn.www");
r1.Set("anchor:www.c-span.org", "CNN");
r1.Delete("anchor:www.abc.com");
Operation op;
Apply(&op, &r1);
上述代码使用 RowMutation 抽象来实现一系列更新操作。然后调用 Apply 原子地修改 Webtable:向 www.cnn.com[2] 添加一个 anchor 并且删掉一个不同的。
Scanner scanner(T);
ScanStream *stream;
stream = scanner.FetchColumnFamily("anchor");
stream->SetReturnAllVersions();
scanner.Lookup("com.cnn.www");
for (; !stream->Done(); stream->Next()) {
printf("%s %s %lld %s\n",
scanner.RowName(),
stream->ColumnName(),
stream->MicroTimestamp(),
stream->Value());
}
上述代码使用 Scanner 抽象来迭代一个特定行里的所有 anchor。客户端可以迭代多个列族,有多个机制可用于限制一次扫描生成的行,列和时间戳。
Bigtable 支持对数据的复杂操作:
单行事务
允许将格子(cell)当作计数器来使用
支持在服务器上执行客户端提供的脚本
脚本用 Google 为处理数据开发的语言 Sawzall 编写
可以和 MapReduce 一起使用,将 Bigtable 用作 MapReduce 作业的输入数据源和输出数据源。
4 积木式架构
Bigtable 建立在 Google 其他的基础设施之上:
使用分布式的 Google File System(GFS)存储日志和数据文件
Bigtable 集群通常和其他分布式应用程序共享机器池;同一个节点上同时存在 Bigtable 进程和其他应用程序的进程
依赖一个集群管理系统来调度作业、管理共享机器上的资源、处理硬件故障和监控机器状态
Google SSTable(Sorted-String Table)格式被用于存储 Bigtable 数据
SSTable 提供持久稳定的键值表,键和值可以是任意字符串。每个 SSTable 包含一连串的 block(通常每个 block 大小为 64KB,但也可以配置)。block index(存储在 SSTable 的末端)被用于定位 block;当 SSTable 被打开 index 就被加载到内存中。一次查找(lookup)可以通过一次磁盘搜索(seek)进程:首先在内存中的索引来一把二分查找(binary search)找到正确的 block,然后从磁盘读取 block。或者 SSTable 也可以被完全映射到内存中,这使得我们能够在不接触磁盘的情况下进行查找和扫描。
被叫作 Chubby 的高可用分布式锁服务
一个 Chubby 服务由五个副本组成。Chubby 利用 Paxos 算法来维护副本的一致性。
Chubby 不可用会导致 Bigtable 也不可用
Bigtable 使用 Chubby 确保任何时候至多有一个 master 存储 Bigtable 数据的 bootstrap 位置(见 5.1[3]) 发现 tablet 服务器和确认 tablet 服务器的死亡(见 5.2[4]) 存储 Bigtable schema 信息 存储访问控制列表
5 实现
Bigtable 有三个主要组件:
被链接至每个客户端的库(library)
一台主节点(master)
主节点(master)负责:
为 tablet 服务器分配 tablet 探测 tablet 服务器加减 均衡 tablet 服务器的负载 GFS 中文件的垃圾收集(garbage collection) 处理 schema 变更,例如创建表和列族 许多 tablet 服务器
tablet 服务器可以动态添加至集群或者从集群移除 每台 tablet 服务器管理一个 tablet 集合(通常每台从几十到上千个 tablet) 处理对 tablet 的读写请求(典型的单主节点分布式存储系统,客户端直接和 tablet 服务器读写通信,所以主节点实际上负载很轻) tablet 太大时对其进行拆分
Bigtable 集群存储大量的表,每个表由一组 tablet 构成,每个 tablet 包含与行(row)关联的所有数据。刚开始每个表只有一个 tablet,随着表增长,它被自动拆分成多个 tablet,每个大概 100-200 MB 大小。
5.1 Tablet 位置
使用类似 B+ 树的三级结构来存储 tablet 位置信息。
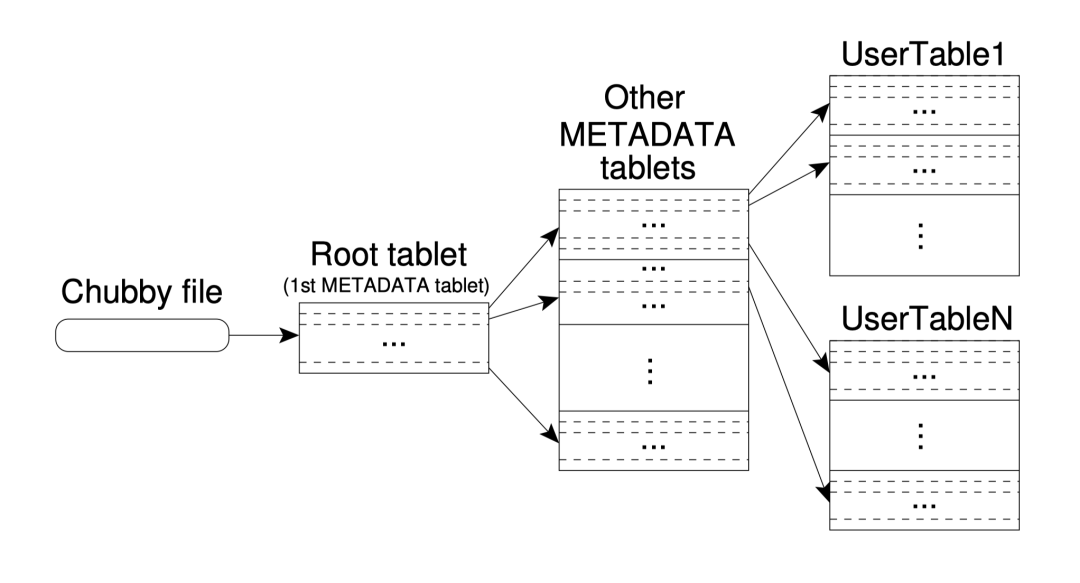
第一级是一个存在 Chubby 中的文件,包含了 root tablet 的位置。而 root tablet 在一个特殊的元数据(metadata)表中存储所有 tablet 的位置。root tablet 被特殊处理,从不会拆分,确保 tablet 位置的层级不超过三级。每行元数据存储了大约 1KB 的数据。128MB 的元数据 tablet,三级位置 schema 能够寻址 2^34 个 tablet。
客户端库(client library)会缓存 tablet 位置:
如果客户端无缓存
位置算法需要 3 把网络来回(round-trip),包括一把 Chubby 读取。
如果客户端缓存过期
位置算法就要 6 把网络来回(round-trip),因为失效的缓存记录只有在未命中时才会被发现。
tablet 位置被存储在内存中,不需要访问 GFS,通过客户端库(client library)预取 tablet 位置来进一步降低开销:每当读取元数据表时,读取一个以上的 tablet 元数据。
5.2 Tablet 分配
每个 tablet 只被分配到一台 tablet 服务器。主节点持续追踪存活的 tablet 服务器,还有分配 tablet 至 tablet 服务器。
Bigtable 使用 Chubby 持续追踪 tablet 服务器。当 tablet 服务器启动,在特定的 Chubby 路径中创建一个不重名的文件并对其持锁。主节点通过监听这个路径来发现 tablet 服务器。现在微服务中用 etcd 来做服务发现也是基于这个原型来的。如果 tablet 服务器弃锁(比如发生网络分区),就判定 tablet 服务器下线。只要文件还在 tablet 服务器就会尝试获取锁;要是文件没了,tablet server 永远出头之日,就干掉它自己。当 tablet 服务器终止,它会尝试释放锁。
当主节点探测到 tablet 服务器下线,会尽快重新分配那些 tablet。主节点定期询问 tablet 服务器锁的状态,如果 tablet 服务器汇报锁丢了,或者直接失联了:
主节点尝试获取 Chubby 中服务器文件的锁 如果主节点持锁成功,说明 Chubby 还活着,tablet 服务器出问题了 主节点删除那份服务器文件,确保 tablet 服务器永远无法再次上线 主节点将之前分配到那台服务器的所有 tablet 移动至未分配的 tablet 集合
当主节点与 Chubby 断开连接,它就干掉自己。主节点故障不会变更当前 tablet 的分配。主节点启动后,需要先知道当前的 tablet 分配情况才能对其变更:
在 Chubby 那边获得一个唯一的 master 锁 扫描 Chubby 上的文件路径来寻找存活的服务器 和每个存活的 tablet 服务器通信来确认哪些 tablet 已经被分配 扫描元数据表获取 tablet 集合,发现未分配的 tablet 就将其添加至未分配的 table 集合
已存在的 tablet 发生变更的情况:
创建/删除表 两个 tablet 合并成一个 一个 table 拆分成两个
最后一种情况比较特殊因为不是主节点发起的。tablet 服务器通过在元数据表中记录新的 tablet 信息提交拆分。当拆分提交后,通知主节点。万一拆分通知不到位(tablet 服务器或者主节点挂了),当主节点要求一台 tablet 服务器加载刚拆分的 tablet 时也会探测到新的 tablet,因为 tablet 服务器会通知主节点。
5.3 Tablet 服务
tablet 被存在 GFS 中,如图 5 所示。更新被提交至 commit log,其中存储了 redo 记录。最近提交的一次更新被存储在一个被称作 memtable 的有序 buffer 中;而较早的更新被存储在一个 SSTable 序列中。
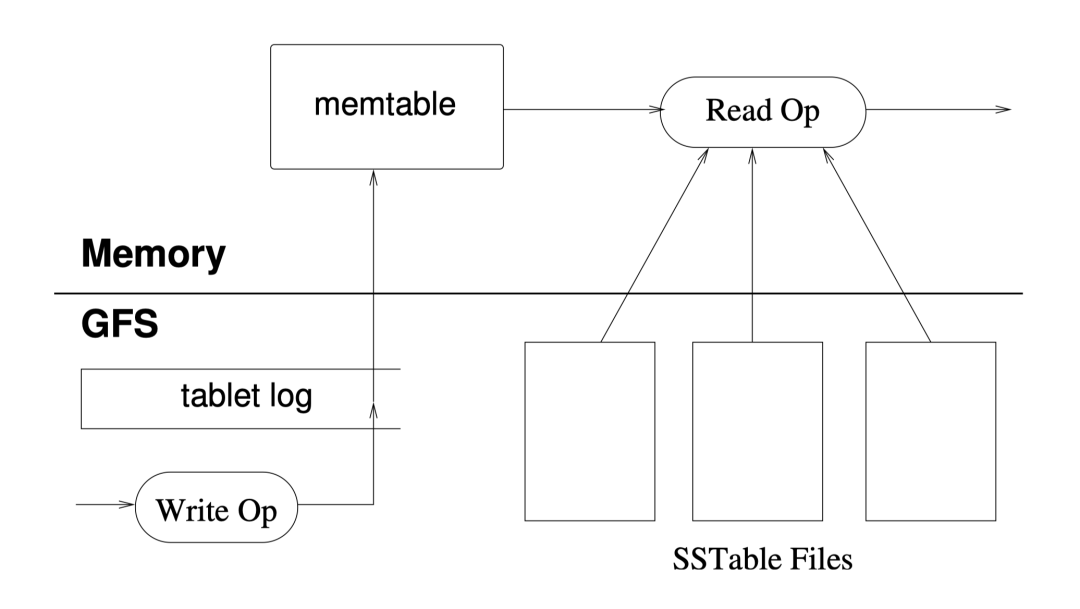
要恢复一个 tablet,tablet 服务器从元数据表读取元数据,元数据中包含了构成 tablet 的 SSTable 和一组 redo point,这些点指向了 commit log。服务器将 SSTable 读到内存中并通过应用所有 redo point 后提交的更新重建 memtable。
写操作 检查写操作是否合法 检查权限 将变更写到 commit log 中 写提交后,内容被插入 memtable 读操作 检查读操作是否合法 检查权限 在 SSTable 序列和 memtable 的合并视图上执行读操作
5.4 压缩
随着写操作的执行,memtable 变得越来越大,当它的的体积达到阈值:
memtable 就被冻结 创建一个新的 memtable 冻结的 memtable 被转换成 SSTable 并写入 GFS
这个叫做 minor compaction 的步骤有两个目的:
缩减 tablet 服务器的内存使用 如果服务器挂了,减少恢复时从 commit log 中读取的数据量
每次 minor compaction 都会创建一个新的 SSTable,读操作可能要合并大量 SSTable 的更新。他们在后台定期执行 merging compaction 操作,读取 SSTable 和 memtable 并写到一个新的 SSTable 中,完成后就删掉输入。
6 详细设计
实现高性能、高可用和高可靠性。
6.1 地区组
客户端可以将多个列族(column family)归入一个地区组(locality group)。为每个 tablet 的每个地区组生成一个单独的 SSTable。将通常不被一起为访问的列族切分成独立的地区组,能够使读取更高效。举个例子,Webtable 中的页面元数据(语言和校验)可以在一个地区组中,而页面的内容可以在另一个组中:希望读取元数据的应用程序无需读取所有的页面内容。
地区组在内存中被声明,它的 SSTable 会被加载到 tablet 服务器的内存中,这样就访问磁盘来读取列族了。
6.2 压缩
客户端可以控制地区组的 SSTable 是否被压缩,以哪种格式压缩。
分别压缩每个 block 会损失一点点空间,但是读取 SSTable 的小部分内容就不需要解压整个文件了。
许多客户端选择两步压缩:
使用 Bentley & McIlroy 方案在一个大窗口中压缩长字符串 使用快速压缩算法寻找 16KB 的数据窗口中的重复
尽管在选择压缩算法时强调速度而非空间,但是两步压缩效果非常棒。
6.3 缓存
tablet 服务器使用两级缓存来提升读性能:
高一级的 Scan Cache 缓存了 SSTable 接口返回的键值对
在应用程序读取重复的数据时很管用
低一级的 Block Cache 缓存了从 GFS 读取的 SSTable block
在应用程序读取的数据靠近它们最近读取的数据时很管用
6.4 布隆过滤器(Bloom Filter)
读操作要读取构成一个 tablet 状态的所有 SSTable,要是 SSTable 不在内存中,那就要访问磁盘了。为特定的地区组的 SSTable 创建一个布隆过滤器来减少访问次数,查找布隆过滤器来确认 SSTable 是否包含指定的数据。
6.5 commit log 实现
如果将每个 tablet 的 commit log 保存在独立的日志文件中:
会在 GFS 并发写大量文件。 会降低组提交优化的效率。
尽管使用单一日志文件在常规操作时有巨大的性能收益,但是它会使恢复变得复杂。当 tablet 服务器挂了,分配给它的 tablet 会被移动至其他服务器。要恢复 tablet 的状态,新的 tablet 服务器要根据 commit log 重新应用对 tablet 的变更。但是所有的变更都混在同一份物理日志文件中,一种办法是每个新的 tablet 服务器读取完整的文件并解析出恢复所需的条目,如果有 100 台机器那么这份日志文件就会被读取 100 次。如何避免重复的日志文件读取?
根据 key 对 commit log 的条目排序
对特定 tablet 的所有变更都是连续的,一把磁盘 seek 后顺序读取
为了并行排序,将日志文件分成 64MB 大小的段,在不同的 tablet 服务器上并行排序每个段
将 commit log 写到 GFS 有时候会碰到性能瓶颈,每个 tablet 服务器有两条日志写线程,分别写入日志文件,同时只激活一条线程。如果当前线程性能很差,日志写会被切换至另一条线程。
6.6 加速 tablet 恢复
如果主节点将一个 tablet 移动至另一台 tablet 服务器,源 tablet 服务器会对它做一次 minor compaction,完成后就不再提供该 tablet 了。这样另一台 tablet 服务器不需要任何日志记录的恢复就可以加载那个 tablet。
6.7 不变性
生成的 SSTable 是不可变更的。当从 SSTables 读取时,不需要任何文件系统访问同步。所以行并发读可被非常高效的实现。唯一可以被读写的可变数据结构是 memtable。为了减少读取 memtable 时的数据复制,每个 memtable 的行都是写时复制的(copy-on-write),允许并行读写。
因为 SSTable 是不可变更的,永久删除数据就被转换为垃圾收集废弃的 SSTable。所有的 tablet 的 SSTables 都在元数据表中注册。主节点在一次 mark-and-sweep 垃圾收集中移除废弃的 SSTable。
最后,不可变更的 SSTable 能够更快地拆分 tablet。无需为每个子 tablet 生成一组新的 SSTable 集合,只要共享父 tablet 的 SSTable 就行了。
引用链接
OSDI: https://www.usenix.org/legacy/events/osdi06/
[2]www.cnn.com: http://www.cnn.com
[3]见 5.1: https://blog.crazytaxii.com/posts/bigtable/#51-tablet-位置
[4]见 5.2: https://blog.crazytaxii.com/posts/bigtable/#52-tablet-分配
原文链接:https://blog.crazytaxii.com/posts/bigtable/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
