
全面分析Uber的高性能日志库Zap
简介
zap 是什么?
⚡ZAP[1] 是uber 开源的提供快速,结构化,高性能的日志记录包。
zap 高性能体现在哪里?
在介绍zap包的优化部分之前,让我们看下zap日志库的工作流程图
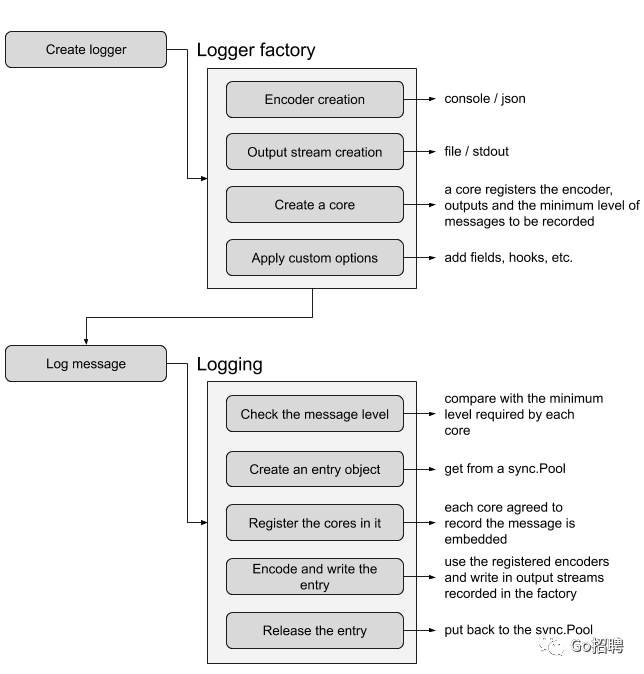
大多数日志库提供的方式是基于反射的序列化和字符串格式化,这种方式代价高昂,而 Zap 采取不同的方法。
避免 interface{} 使用强类型设计
封装强类型,无反射
使用零分配内存的 JSON 编码器,尽可能避免序列化开销,它比其他结构化日志包快 4 - 10 倍。
logger.Info("failed to fetch URL",
zap.String("url", "https://baidu.com"),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
)
使用 sync.Pool 以避免记录消息时的内存分配
详情在下文 zapcore 模块介绍。
Example
安装
go get -u go.uber.org/zap
Zap 提供了两种类型的 logger
SugaredLogger Logger
在性能良好但不是关键的情况下,使用 SugaredLogger,它比其他结构化的日志包快 4-10 倍,并且支持结构化和 printf 风格的APIs。
例一 调用 NewProduction 创建logger对象
func TestSugar(t *testing.T) {
logger, _ := zap.NewProduction()
// 默认 logger 不缓冲。
// 但由于底层 api 允许缓冲,所以在进程退出之前调用 Sync 是一个好习惯。
defer logger.Sync()
sugar := logger.Sugar()
sugar.Infof("Failed to fetch URL: %s", "https://baidu.com")
}
对性能和类型安全要求严格的情况下,可以使用 Logger ,它甚至比前者SugaredLogger更快,内存分配次数也更少,但它仅支持强类型的结构化日志记录。
例二 调用 NewDevelopment 创建logger对象
func TestLogger(t *testing.T) {
logger, _ := zap.NewDevelopment()
defer logger.Sync()
logger.Info("failed to fetch URL",
// 强类型字段
zap.String("url", "https://baidu.com"),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
)
}
不需要为整个应用程序决定选择使用 Logger 还是 SugaredLogger ,两者之间都可以轻松转换。
例三 Logger 与 SugaredLogger 相互转换
// 创建 logger
logger := zap.NewExample()
defer logger.Sync()
// 转换 SugaredLogger
sugar := logger.Sugar()
// 转换 logger
plain := sugar.Desugar()
例四 自定义格式
自定义一个日志消息格式,带着问题看下列代码。
debug 级别的日志打印到控制台了吗? 最后的 error 会打印到控制台吗 ?
package main
import (
"os"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
func NewCustomEncoderConfig() zapcore.EncoderConfig {
return zapcore.EncoderConfig{
TimeKey: "ts",
LevelKey: "level",
NameKey: "logger",
CallerKey: "caller",
FunctionKey: zapcore.OmitKey,
MessageKey: "msg",
StacktraceKey: "stacktrace",
LineEnding: zapcore.DefaultLineEnding,
EncodeLevel: zapcore.CapitalColorLevelEncoder,
EncodeTime: zapcore.TimeEncoderOfLayout("2006-01-02 15:04:05"),
EncodeDuration: zapcore.SecondsDurationEncoder,
EncodeCaller: zapcore.ShortCallerEncoder,
}
}
func main() {
atom := zap.NewAtomicLevelAt(zap.DebugLevel)
core := zapcore.NewCore(
zapcore.NewConsoleEncoder(NewCustomEncoderConfig()),
zapcore.NewMultiWriteSyncer(zapcore.AddSync(os.Stdout)),
atom,
)
logger := zap.New(core, zap.AddCaller(), zap.Development())
defer logger.Sync()
// 配置 zap 包的全局变量
zap.ReplaceGlobals(logger)
// 运行时安全地更改 logger 日记级别
atom.SetLevel(zap.InfoLevel)
sugar := logger.Sugar()
// 问题 1: debug 级别的日志打印到控制台了吗?
sugar.Debug("debug")
sugar.Info("info")
sugar.Warn("warn")
sugar.DPanic("dPanic")
// 问题 2: 最后的 error 会打印到控制台吗?
sugar.Error("error")
}
结果见下图
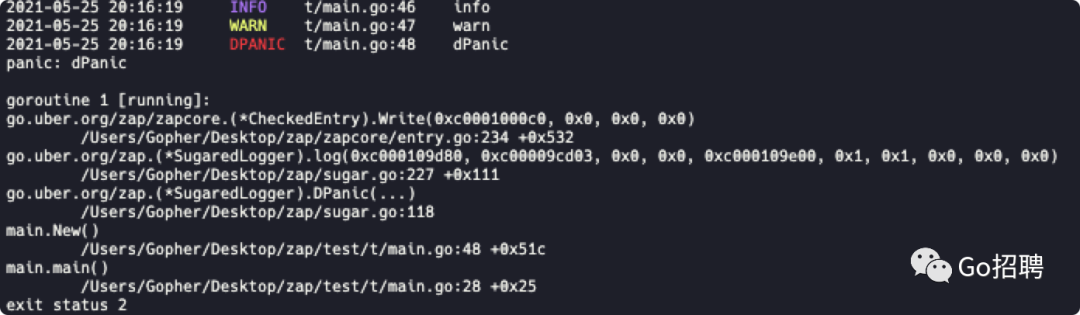
问题 1:
没有打印。AtomicLevel 是原子性可更改的动态日志级别,通过调用 atom.SetLevel 更改日志级别为 infoLevel 。
问题 2:
没有打印。zap.Development() 启用了开发模式,在开发模式下 DPanic 函数会引发 panic,所以最后的 error 不会打印到控制台。
源码分析
此次源码分析基于 Zap 1.16
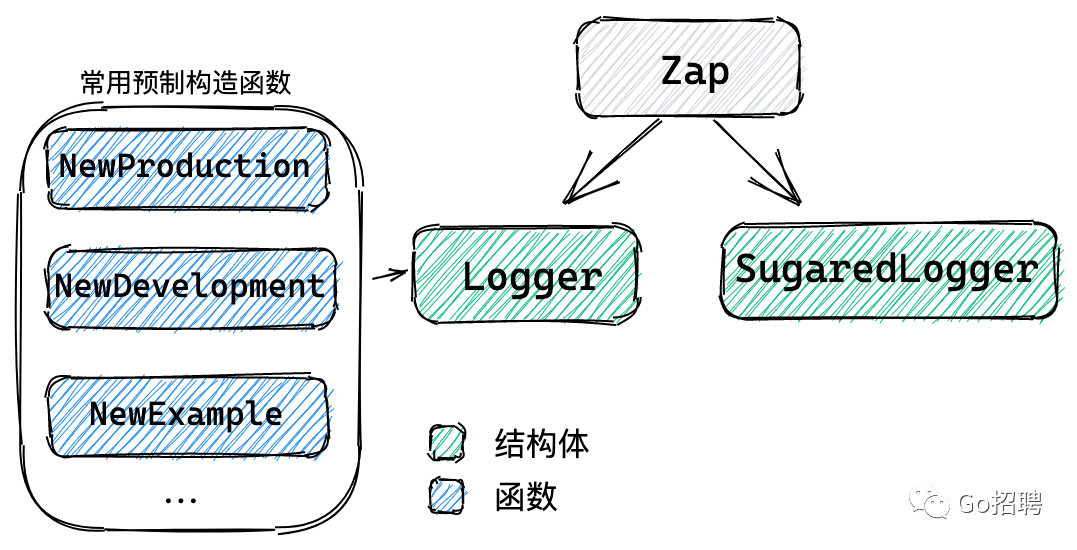
上图仅表示 zap 可调用两种 logger,没有表达 Logger 与 SugaredLogger 的关系,继续往下看,你会更理解。
Logger
logger 提供快速,分级,结构化的日志记录。所有的方法都是安全的,内存分配很重要,因此它的 API 有意偏向于性能和类型安全。
zap@v1.16.0 - logger.go
type Logger struct {
// 实现编码和输出的接口
core zapcore.Core
// 记录器开发模式,DPanic 等级将记录 panic
development bool
// 开启记录调用者的行号和函数名
addCaller bool
// 致命日志采取的操作,默认写入日志后 os.Exit()
onFatal zapcore.CheckWriteAction
name string
// 设置记录器生成的错误目的地
errorOutput zapcore.WriteSyncer
// 记录 >= 该日志等级的堆栈追踪
addStack zapcore.LevelEnabler
// 避免记录器认为封装函数为调用方
callerSkip int
// 默认为系统时间
clock Clock
}
在 Example 中分别使用了 NewProduction 和 NewDevelopment ,接下来以这两个函数开始分析。下图表示 A 函数调用了 B 函数,其中箭头表示函数调用关系。图中函数都会分析到。
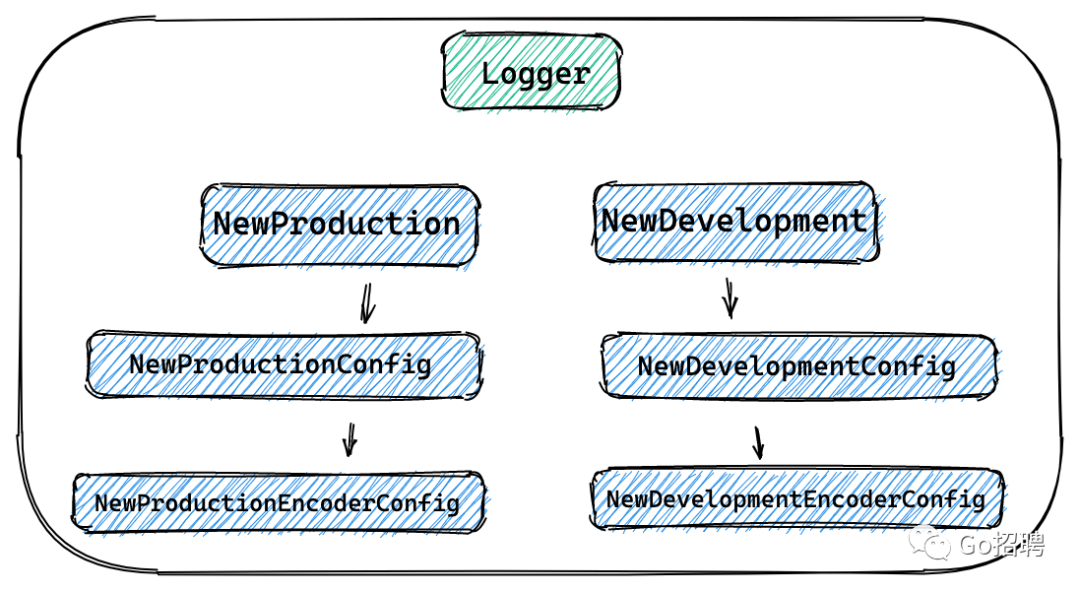
NewProduction
从下面代码中可以看出,此函数是对 NewProductionConfig().Build(...) 封装的快捷方式。
zap@v1.16.0 - logger.go
func NewProduction(options ...Option) (*Logger, error) {
return NewProductionConfig().Build(options...)
}
NewProductionConfig
在 InfoLevel 及更高级别上启用了日志记录。它使用 JSON 编码器,写入 stderr,启用采样。
zap@v1.16.0 - config.go
func NewProductionConfig() Config {
return Config{
// info 日志级别
Level: NewAtomicLevelAt(InfoLevel),
// 非开发模式
Development: false,
// 采样设置
Sampling: &SamplingConfig{
Initial: 100, // 相同日志级别下相同内容每秒日志输出数量
Thereafter: 100, // 超过该数量,才会再次输出
},
// JSON 编码器
Encoding: "json",
// 后面介绍
EncoderConfig: NewProductionEncoderConfig(),
// 输出到 stderr
OutputPaths: []string{"stderr"},
ErrorOutputPaths: []string{"stderr"},
}
}
Config 结构体
通过 Config 可以设置通用的配置项。
zap@v1.16.0 - config.go
type Config struct {
// 日志级别
Level AtomicLevel `json:"level" yaml:"level"`
// 开发模式
Development bool `json:"development" yaml:"development"`
// 停止使用调用方的函数和行号
DisableCaller bool `json:"disableCaller" yaml:"disableCaller"`
// 完全停止使用堆栈跟踪,默认为 `>=WarnLevel` 使用堆栈跟踪
DisableStacktrace bool `json:"disableStacktrace" yaml:"disableStacktrace"`
// 采样设置策略
Sampling *SamplingConfig `json:"sampling" yaml:"sampling"`
// 记录器的编码,有效值为 'json' 和 'console' 以及通过 `RegisterEncoder` 注册的有效编码
Encoding string `json:"encoding" yaml:"encoding"`
// 编码器选项
EncoderConfig zapcore.EncoderConfig `json:"encoderConfig" yaml:"encoderConfig"`
// 日志的输出路径
OutputPaths []string `json:"outputPaths" yaml:"outputPaths"`
// zap 内部错误的输出路径
ErrorOutputPaths []string `json:"errorOutputPaths" yaml:"errorOutputPaths"`
// 添加到根记录器的字段的集合
InitialFields map[string]interface{} `json:"initialFields" yaml:"initialFields"`
}
NewDevelopment
从下面代码中可以看出,此函数是对 NewDevelopmentConfig().Build(...) 封装的快捷方式
zap@v1.16.0 - logger.go
func NewDevelopment(options ...Option) (*Logger, error) {
return NewDevelopmentConfig().Build(options...)
}
NewDevelopmentConfig
此函数在 DebugLevel 及更高版本上启用日志记录,它使用 console 编码器,写入 stderr,禁用采样。
zap@v1.16.0 - config.go
func NewDevelopmentConfig() Config {
return Config{
// debug 等级
Level: NewAtomicLevelAt(DebugLevel),
// 开发模式
Development: true,
// console 编码器
Encoding: "console",
EncoderConfig: NewDevelopmentEncoderConfig(),
// 输出到 stderr
OutputPaths: []string{"stderr"},
ErrorOutputPaths: []string{"stderr"},
}
}
NewProductionEncoderConfig 和 NewDevelopmentEncoderConfig 都是返回编码器配置。
zap@v1.16.0 - config.go
type EncoderConfig struct {
// 设置 编码为 JSON 时的 KEY
// 如果为空,则省略
MessageKey string `json:"messageKey" yaml:"messageKey"`
LevelKey string `json:"levelKey" yaml:"levelKey"`
TimeKey string `json:"timeKey" yaml:"timeKey"`
NameKey string `json:"nameKey" yaml:"nameKey"`
CallerKey string `json:"callerKey" yaml:"callerKey"`
FunctionKey string `json:"functionKey" yaml:"functionKey"`
StacktraceKey string `json:"stacktraceKey" yaml:"stacktraceKey"`
// 配置行分隔符
LineEnding string `json:"lineEnding" yaml:"lineEnding"`
// 配置常见复杂类型的基本表示形式。
EncodeLevel LevelEncoder `json:"levelEncoder" yaml:"levelEncoder"`
EncodeTime TimeEncoder `json:"timeEncoder" yaml:"timeEncoder"`
EncodeDuration DurationEncoder `json:"durationEncoder" yaml:"durationEncoder"`
EncodeCaller CallerEncoder `json:"callerEncoder" yaml:"callerEncoder"`
// 日志名称,此参数可选
EncodeName NameEncoder `json:"nameEncoder" yaml:"nameEncoder"`
// 配置 console 编码器使用的字段分隔符,默认 tab
ConsoleSeparator string `json:"consoleSeparator" yaml:"consoleSeparator"`
}
NewProductionEncoderConfig
zap@v1.16.0 - config.go
func NewProductionEncoderConfig() zapcore.EncoderConfig {
return zapcore.EncoderConfig{
TimeKey: "ts",
LevelKey: "level",
NameKey: "logger",
CallerKey: "caller",
FunctionKey: zapcore.OmitKey,
MessageKey: "msg",
StacktraceKey: "stacktrace",
// 默认换行符 \n
LineEnding: zapcore.DefaultLineEnding,
// 日志等级序列为小写字符串,如:InfoLevel被序列化为 "info"
EncodeLevel: zapcore.LowercaseLevelEncoder,
// 时间序列化成浮点秒数
EncodeTime: zapcore.EpochTimeEncoder,
// 时间序列化,Duration为经过的浮点秒数
EncodeDuration: zapcore.SecondsDurationEncoder,
// 以 包名/文件名:行数 格式序列化
EncodeCaller: zapcore.ShortCallerEncoder,
}
}
该配置会输出如下结果,此结果出处参见 Example 中的例一
{"level":"info","ts":1620367988.461055,"caller":"test/use_test.go:24","msg":"Failed to fetch URL: https://baidu.com"}
NewDevelopmentEncoderConfig
zap@v1.16.0 - config.go
func NewDevelopmentEncoderConfig() zapcore.EncoderConfig {
return zapcore.EncoderConfig{
// keys 值可以是任意非空的值
TimeKey: "T",
LevelKey: "L",
NameKey: "N",
CallerKey: "C",
FunctionKey: zapcore.OmitKey,
MessageKey: "M",
StacktraceKey: "S",
// 默认换行符 \n
LineEnding: zapcore.DefaultLineEnding,
// 日志等级序列为大写字符串,如:InfoLevel被序列化为 "INFO"
EncodeLevel: zapcore.CapitalLevelEncoder,
// 时间格式化为 ISO8601 格式
EncodeTime: zapcore.ISO8601TimeEncoder,
EncodeDuration: zapcore.StringDurationEncoder,
// // 以 包名/文件名:行数 格式序列化
EncodeCaller: zapcore.ShortCallerEncoder,
}
}
该配置会输出如下结果,此结果出处参见 Example 中的例二
2021-05-07T14:14:12.434+0800 INFO test/use_test.go:31 failed to fetch URL {"url": "https://baidu.com", "attempt": 3, "backoff": "1s"}
NewProductionConfig 和 NewDevelopmentConfig 返回 config 调用 Build 函数返回 logger,接下来我们看看这个函数。
zap@v1.16.0 - config.go
func (cfg Config) Build(opts ...Option) (*Logger, error) {
enc, err := cfg.buildEncoder()
if err != nil {
return nil, err
}
sink, errSink, err := cfg.openSinks()
if err != nil {
return nil, err
}
if cfg.Level == (AtomicLevel{}) {
return nil, fmt.Errorf("missing Level")
}
log := New(
zapcore.NewCore(enc, sink, cfg.Level),
cfg.buildOptions(errSink)...,
)
if len(opts) > 0 {
log = log.WithOptions(opts...)
}
return log, nil
}
从上面的代码中,通过解析 config 的参数,调用 New 方法来创建 Logger。在 Example 中例四,就是调用 New 方法来自定义 Logger。
SugaredLogger
Logger 作为 SugaredLogger 的属性,这个封装优点在于不是很在乎性能的情况下,可以快速调用Logger。所以名字为加了糖的 Logger。
zap@v1.16.0 - logger.go
type SugaredLogger struct {
base *Logger
}
zap.ReplaceGlobals(logger) // 重新配置全局变量
zap.S().Info("SugaredLogger") // S 返回全局 SugaredLogger
zap.L().Info("logger") // L 返回全局 logger
与Logger不同,SugaredLogger不强制日志结构化。所以对于每个日志级别,都提供了三种方法。
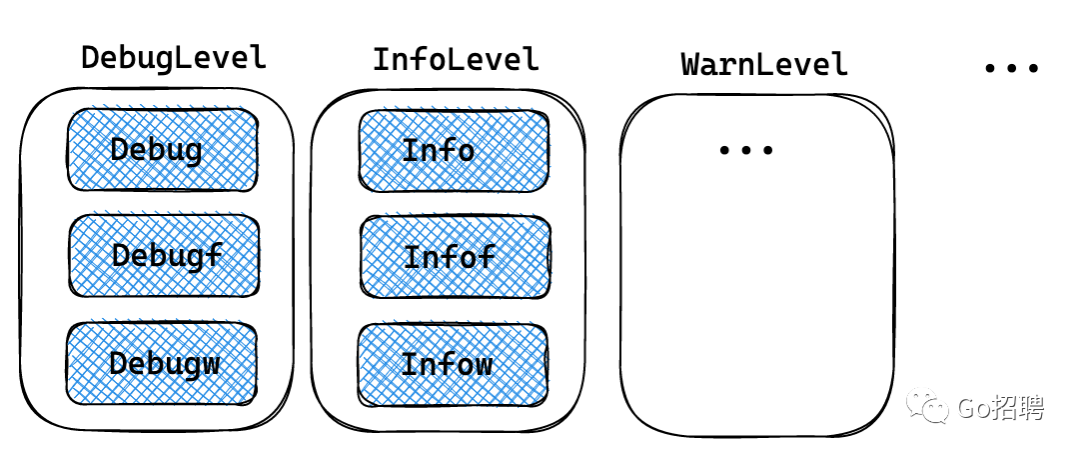
zap@v1.16.0 - sugar.go
以 info 级别为例,相关的三种方法。
// Info 使用 fmt.Sprint 构造和记录消息。
func (s *SugaredLogger) Info(args ...interface{}) {
s.log(InfoLevel, "", args, nil)
}
// Infof 使用 fmt.Sprintf 记录模板消息。
func (s *SugaredLogger) Infof(template string, args ...interface{}) {
s.log(InfoLevel, template, args, nil)
}
// Infow 记录带有其他上下文的消息
func (s *SugaredLogger) Infow(msg string, keysAndValues ...interface{}) {
s.log(InfoLevel, msg, nil, keysAndValues)
}
在 sugar.Infof("...") 打上断点,从这开始追踪源码。
在调试代码之前,先给大家看一下SugaredLogger 的 Infof 函数的调用的大致工作流,其中不涉及采样等。
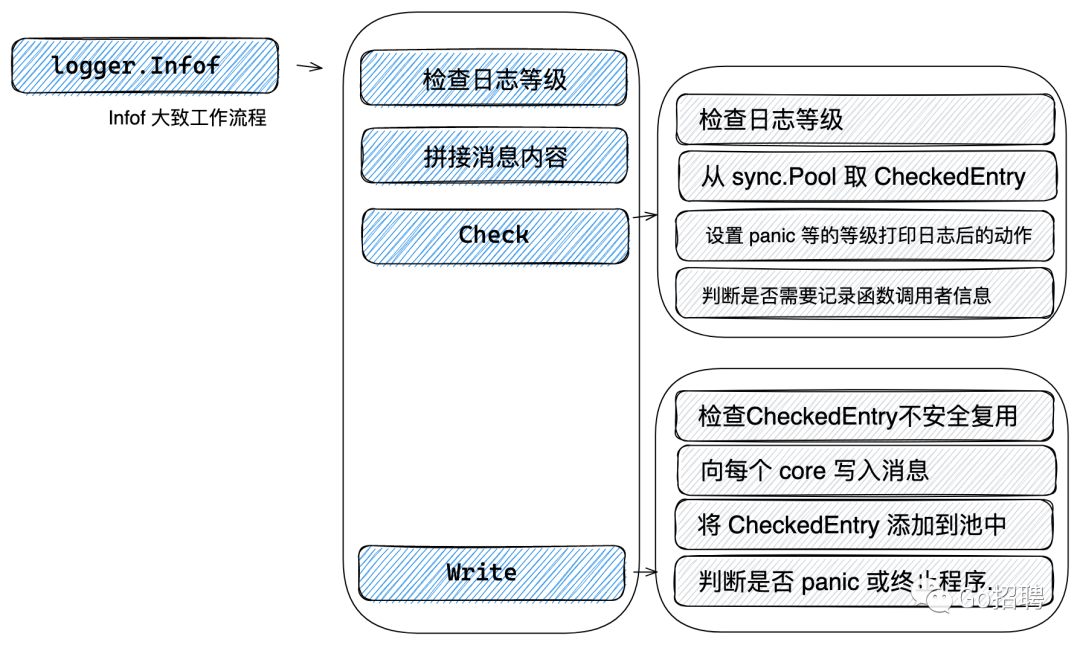
Info , Infof, Infow 三个函数都调用了 log 函数,log 函数代码如下
zap@v1.16.0 - sugar.go
func (s *SugaredLogger) log(lvl zapcore.Level, template string, fmtArgs []interface{}, context []interface{}) {
// 判断是否启用的日志级别
if lvl < DPanicLevel && !s.base.Core().Enabled(lvl) {
return
}
// 将参数合并到语句中
msg := getMessage(template, fmtArgs)
// Check 可以帮助避免分配一个分片来保存字段。
if ce := s.base.Check(lvl, msg); ce != nil {
ce.Write(s.sweetenFields(context)...)
}
}
函数的第一个参数 InfoLevel 是日志级别,其源码如下
zap@v1.16.0 - zapcore/level.go
const (
// Debug 应是大量的,且通常在生产状态禁用.
DebugLevel = zapcore.DebugLevel
// Info 是默认的记录优先级.
InfoLevel = zapcore.InfoLevel
// Warn 比 info 更重要.
WarnLevel = zapcore.WarnLevel
// Error 是高优先级的,如果程序顺利不应该产生任何 err 级别日志.
ErrorLevel = zapcore.ErrorLevel
// DPanic 特别重大的错误,在开发模式下引起 panic.
DPanicLevel = zapcore.DPanicLevel
// Panic 记录消息后调用 panic.
PanicLevel = zapcore.PanicLevel
// Fatal 记录消息后调用 os.Exit(1).
FatalLevel = zapcore.FatalLevel
)
getMessage 函数处理 template 和 fmtArgs 参数,主要为不同的参数选择最合适的方式拼接消息
zap@v1.16.0 - sugar.go
func getMessage(template string, fmtArgs []interface{}) string {
// 没有参数直接返回 template
if len(fmtArgs) == 0 {
return template
}
// 此处调用 Sprintf 会使用反射
if template != "" {
return fmt.Sprintf(template, fmtArgs...)
}
// 消息为空并且有一个参数,返回该参数
if len(fmtArgs) == 1 {
if str, ok := fmtArgs[0].(string); ok {
return str
}
}
// 返回所有 fmtArgs
return fmt.Sprint(fmtArgs...)
}
关于 s.base.Check ,这就需要介绍zapcore ,下面分析相关模块。
zapcore
zapcore包 定义并实现了构建 zap 的低级接口。通过提供这些接口的替代实现,外部包可以扩展 zap 的功能。
zap@v1.16.0 - zapcore/core.go
// Core 是一个最小的、快速的记录器接口。
type Core interface {
// 接口,决定一个日志等级是否启用
LevelEnabler
// 向 core 添加核心上下文
With([]Field) Core
// 检查是否应记录提供的条目
// 在调用 write 之前必须先调用 Check
Check(Entry, *CheckedEntry) *CheckedEntry
// 写入日志
Write(Entry, []Field) error
// 同步刷新缓存日志(如果有)
Sync() error
}
Check 函数有两个入参。第一个参数表示一条完整的日志消息,第二个参数为 nil 时会从 sync.Pool 创建的池中取出*CheckedEntry对象复用,避免重新分配内存。该函数内部调用 AddCore 实现获取 *CheckedEntry对象,最后调用 Write 写入日志消息。
相关代码全部贴在下面,更多介绍请看代码中的注释。
zap@v1.16.0 - zapcore/entry.go
// 一个 entry 表示一个完整的日志消息
type Entry struct {
Level Level
Time time.Time
LoggerName string
Message string
Caller EntryCaller
Stack string
}
// 使用 sync.Pool 复用临时对象
var (
_cePool = sync.Pool{New: func() interface{} {
return &CheckedEntry{
cores: make([]Core, 4),
}
}}
)
// 从池中取出 CheckedEntry 并初始化值
func getCheckedEntry() *CheckedEntry {
ce := _cePool.Get().(*CheckedEntry)
ce.reset()
return ce
}
// CheckedEntry 是 enter 和 cores 集合。
type CheckedEntry struct {
Entry
ErrorOutput WriteSyncer
dirty bool // 用于检测是否重复使用对象
should CheckWriteAction // 结束程序的动作
cores []Core
}
// 重置对象
func (ce *CheckedEntry) reset() {
ce.Entry = Entry{}
ce.ErrorOutput = nil
ce.dirty = false
ce.should = WriteThenNoop
for i := range ce.cores {
// 不要保留对 core 的引用!!
ce.cores[i] = nil
}
ce.cores = ce.cores[:0]
}
// 将 entry 写入存储的 cores
// 最后将 CheckedEntry 添加到池中
func (ce *CheckedEntry) Write(fields ...Field) {
if ce == nil {
return
}
if ce.dirty {
if ce.ErrorOutput != nil {
// 检查 CheckedEntry 的不安全重复使用
fmt.Fprintf(ce.ErrorOutput, "%v Unsafe CheckedEntry re-use near Entry %+v.\n", ce.Time, ce.Entry)
ce.ErrorOutput.Sync()
}
return
}
ce.dirty = true
var err error
// 写入日志消息
for i := range ce.cores {
err = multierr.Append(err, ce.cores[i].Write(ce.Entry, fields))
}
// 处理内部发生的错误
if ce.ErrorOutput != nil {
if err != nil {
fmt.Fprintf(ce.ErrorOutput, "%v write error: %v\n", ce.Time, err)
ce.ErrorOutput.Sync()
}
}
should, msg := ce.should, ce.Message
// 将 CheckedEntry 添加到池中,下次复用
putCheckedEntry(ce)
// 判断是否需要 panic 或其它方式终止程序..
switch should {
case WriteThenPanic:
panic(msg)
case WriteThenFatal:
exit.Exit()
case WriteThenGoexit:
runtime.Goexit()
}
}
func (ce *CheckedEntry) AddCore(ent Entry, core Core) *CheckedEntry {
if ce == nil {
// 从池中取 CheckedEntry,减少内存分配
ce = getCheckedEntry()
ce.Entry = ent
}
ce.cores = append(ce.cores, core)
return ce
}
Doc
https://pkg.go.dev/go.uber.org/zap
QA
设计问题
为什么要在Logger性能上花费这么多精力呢?
当然,大多数应用程序不会注意到Logger慢的影响:因为它们每次操作会需要几十或几百毫秒,所以额外的几毫秒很无关紧要。
另一方面,为什么不使用结构化日志快速开发呢?与其他日志包相比SugaredLogger的使用并不难,Logger使结构化记录在对性能要求严格的环境中成为可能。在 Go 微服务的架构体系中,使每个应用程序甚至稍微更有效地加速执行。
为什么没有Logger和SugaredLogger接口?
不像熟悉的io.Writer和http.Handler、Logger和SugaredLogger接口将包括很多方法。正如 Rob Pike 谚语指出[2]的,"The bigger the interface, the weaker the abstraction"(接口越大,抽象越弱)。接口也是严格的,任何更改都需要发布一个新的主版本,因为它打破了所有第三方实现。
Logger和SugaredLogger成为具体类型并不会牺牲太多抽象,而且它允许我们在不引入破坏性更改的情况下添加方法。您的应用程序应该定义并依赖只包含您使用的方法的接口。
为什么我的一些日志会丢失?
在启用抽样时,通过zap有意地删除日志。生产配置(如NewProductionConfig()返回的那样)支持抽样,这将导致在一秒钟内对重复日志进行抽样。有关为什么启用抽样的更多详细信息,请参见"为什么使用示例应用日志"中启用采样.
为什么要使用示例应用程序日志?
应用程序经常会遇到错误,无论是因为错误还是因为用户使用错误。记录错误日志通常是一个好主意,但它很容易使这种糟糕的情况变得更糟:不仅您的应用程序应对大量错误,它还花费额外的CPU周期和I/O记录这些错误日志。由于写入通常是序列化的,因此在最需要时,logger会限制吞吐量。
采样通过删除重复的日志条目来解决这个问题。在正常情况下,您的应用程序会输出每个记录。但是,当类似的记录每秒输出数百或数千次时,zap 开始丢弃重复以保存吞吐量。
为什么结构化的日志 API 除了接受字段之外还可以接收消息?
主观上,我们发现在结构化上下文中附带一个简短的描述是有帮助的。这在开发过程中并不关键,但它使调试和操作不熟悉的系统更加容易。
更具体地说,zap 的采样算法使用消息来识别重复的条目。根据我们的经验,这是一个介于随机抽样(通常在调试时删除您需要的确切条目)和哈希完整条目(代价高)之间的一个中间方法。
为什么要包括全局 loggers?
由于许多其他日志包都包含全局变量logger,许多应用程序没有设计成接收logger作为显式参数。更改函数签名通常是一种破坏性的更改,因此zap包含全局logger以简化迁移。
尽可能避免使用它们。
为什么包括专用的Panic和Fatal日志级别?
一般来说,应用程序代码应优雅地处理错误,而不是使用panic或os.Exit。但是,每个规则都有例外,当错误确实无法恢复时,崩溃是很常见的。为了避免丢失任何信息(尤其是崩溃的原因),记录器必须在进程退出之前冲洗任何缓冲条目。
Zap 通过提供在退出前自动冲洗的Panic和Fatal记录方法来使这一操作变得简单。当然,这并不保证日志永远不会丢失,但它消除了常见的错误。
有关详细信息,请参阅 Uber-go/zap#207 中的讨论。
什么是DPanic?
DPanic代表"panic in development."。在development中,它会打印Panic级别的日志:反之,它将发生在Error级别的日志,DPanic更加容易捕获可能但实际上不应该发生的错误,而不是在生产环境中Panic。
如果你曾经写过这样的代码,就可以使用DPanic:
if err != nil {
panic(fmt.Sprintf("shouldn't ever get here: %v", err))
}
安装问题
错误expects import "go.uber.org/zap"是什么意思?
要么zap安装错误,要么您引用了代码中的错误包名。
Zap 的源代码托管在 GitHub 上,但 import path[3]是 go.uber.org/zap,让我们项目维护者,可以更方便地自由移动源代码。所以在安装和使用包时需要注意这一点。
如果你遵循两个简单的规则,就会正常工作:安装zapgo get -u go.uber.org/zap并始终导入它在你的代码import "go.uber.org/zap",代码不应包含任何对github.com/uber-go/zap的引用.
用法问题
Zap是否支持日志切割?
Zap 不支持切割日志文件,因为我们更喜欢将此交给外部程序,如logrotate.
但是,日志切割包很容易集成,如 `gopkg.in/natefinch/lumberjack.v2`[4] 作为zapcore.WriteSyncer.
// lumberjack.Logger is already safe for concurrent use, so we don't need to
// lock it.
w := zapcore.AddSync(&lumberjack.Logger{
Filename: "/var/log/myapp/foo.log",
MaxSize: 500, // megabytes
MaxBackups: 3,
MaxAge: 28, // days
})
core := zapcore.NewCore(
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig()),
w,
zap.InfoLevel,
)
logger := zap.New(core)
插件
我们很希望zap 本身能满足的每一个logging需求,但我们只熟悉少数日志摄入(log ingestion)系统、参数解析(flag-parsing)包等。所以我们更愿意发展 zap 插件生态系统。
下面扩展包,可以作为参考使用:
| 包 | 集成 |
|---|---|
github.com/tchap/zapext | Sentry, syslog |
github.com/fgrosse/zaptest | Ginkgo |
github.com/blendle/zapdriver | Stackdriver |
github.com/moul/zapgorm | Gorm |
性能比较
说明 : 以下资料来源于 zap 官方,Zap 提供的基准测试清楚地表明,zerolog[5]是与 Zap 竞争最激烈的。zerolo还提供结果非常相似的基准测试[6]:
记录一个10个kv字段的消息:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 862 ns/op | +0% | 5 allocs/op |
| ⚡ zap (sugared) | 1250 ns/op | +45% | 11 allocs/op |
| zerolog | 4021 ns/op | +366% | 76 allocs/op |
| go-kit | 4542 ns/op | +427% | 105 allocs/op |
| apex/log | 26785 ns/op | +3007% | 115 allocs/op |
| logrus | 29501 ns/op | +3322% | 125 allocs/op |
| log15 | 29906 ns/op | +3369% | 122 allocs/op |
使用一个已经有10个kv字段的logger记录一条消息:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 126 ns/op | +0% | 0 allocs/op |
| ⚡ zap (sugared) | 187 ns/op | +48% | 2 allocs/op |
| zerolog | 88 ns/op | -30% | 0 allocs/op |
| go-kit | 5087 ns/op | +3937% | 103 allocs/op |
| log15 | 18548 ns/op | +14621% | 73 allocs/op |
| apex/log | 26012 ns/op | +20544% | 104 allocs/op |
| logrus | 27236 ns/op | +21516% | 113 allocs/op |
记录一个字符串,没有字段或printf风格的模板:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 118 ns/op | +0% | 0 allocs/op |
| ⚡ zap (sugared) | 191 ns/op | +62% | 2 allocs/op |
| zerolog | 93 ns/op | -21% | 0 allocs/op |
| go-kit | 280 ns/op | +137% | 11 allocs/op |
| standard library | 499 ns/op | +323% | 2 allocs/op |
| apex/log | 1990 ns/op | +1586% | 10 allocs/op |
| logrus | 3129 ns/op | +2552% | 24 allocs/op |
| log15 | 3887 ns/op | +3194% | 23 allocs/op |
相似的库
logrus[7] 功能强大
zerolog[8] 性能相当好的日志库
参考资料
⚡ZAP: https://github.com/uber-go/zap
[2]Rob Pike 谚语指出: https://go-proverbs.github.io/
[3]import path: https://golang.org/cmd/go/#hdr-Remote_import_paths
[4]gopkg.in/natefinch/lumberjack.v2: https://godoc.org/gopkg.in/natefinch/lumberjack.v2
[5]zerolog: https://github.com/rs/zerolog
[6]基准测试: https://github.com/rs/zerolog#benchmarks
[7]logrus: https://github.com/sirupsen/logrus
[8]zerolog: https://github.com/rs/zerolog
推荐阅读