
电商数据分析项目总结!
订单数据作为电商数据分析中的基础分析项目,本项目就京东的订单数据进行分析。通过数据分析和可视化深挖数据产生的原因,掌握基础的数据分析能力。
1.关于本项目
1.1数据来源
本次数据来源于京东2020年5月25日 大家电-冰箱的订单数据 按照10%的随机抽样后进行数据脱敏最后得到的订单数据,共有订单数据大约70K,数据来源于公开网络数据。
公众号(Datawhale)后台回复“202013”获取打包的项目源码和数据
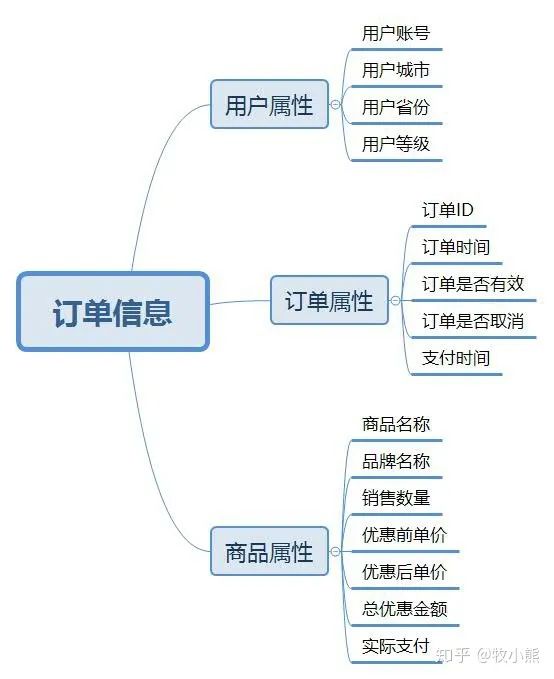
1.2数据所包含信息
订单中的属性将其分成了3类,分别是用户属性、订单属性以及商品属性
2.数据预处理
本项目使用python对数据进行处理 使用plotly进行数据可视化
import pandas as pd
import numpy as np
import plotly_express as px
import plotly.offline as of
import plotly as py
import plotly.graph_objs as go
读取提供的数据
df=pd.read_csv('data.csv',sep='\t', encoding="utf-8", dtype=str)
查看数据的缺失值
df.isnull().sum().sort_values(ascending=False)
user_site_city_id 38190
user_site_province_id 38033
check_account_tm 23271
通过观察发现,这3个数据有部分缺失值,其中user_site_city_id 用户所在城市编号,user_site_province_id 用户所在省份的编号,check_account_tm支付时间
这部分数据的缺失是因为用户填写个人资料时跳过的部分,当然这不影响我们整个数据的分析
我们首先是将数据的类型进行转换 同时处理缺失值和异常值
值得注意的是,通过观察我们发现冰箱最低的价格是288元,但是数据中发现了很多低于288元的订单数据,我们认为这部分数据不能真实代表冰箱实际的订单数据,可能出现了补差价或者补运费的情况,因此这样的数据我们都过滤掉。 因为订单的编号具有唯一性,因此对于订单编号的重复数据,我们认为出现了重复订单 对于缺失的省份值和缺失的数据,我们将空白地方进行填充 通过观察,我们发现数据的列有重复,对于删除重复的列,这里提供一个比较有意思的做法,将数据反转后,删除重复的行再反转回来。 实际支付的价格=商品数量*优惠后的单价
#删除优惠前价格小于288元的
df = df[df['before_prefr_unit_price' ]>= 288]
#订单编号具有唯一性,因此需要删除重复的数据
df.drop_duplicates(subset=['sale_ord_id'],keep='first',inplace=True)
#填充城市和省份的缺失数据
df.user_site_city_id=df.user_site_city_id.fillna(-1)
df.user_site_province_id =df.user_site_province_id.fillna(-1)
#删除重复的列check_account_tm 转置列 删除 再转置
df=df.T.drop_duplicates().T
#实际支付的价格=商品数量*优惠后单价
df['total_actual_pay'] = df['sale_qtty'] * df['after_prefr_unit_price']
到这里我们就完成了数据的预处理部分
3.订单分析
3.1订单取消比例分析
通过数据观察,有的订单出现了取消,因此我们通过饼图查看取消和未取消的比例
order_cancel = df[df.cancel_flag==1]['sale_ord_id'].count()
order_success=df[df.cancel_flag==0]['sale_ord_id'].count()
labels = ['取消','未取消']
values = [order_cancel, order_success]
trace = [go.Pie(labels=labels, values=values)]
layout = go.Layout(
title = dict(text='订单比例图',x=0.5)
)
fig = go.Figure(data = trace, layout = layout)
fig
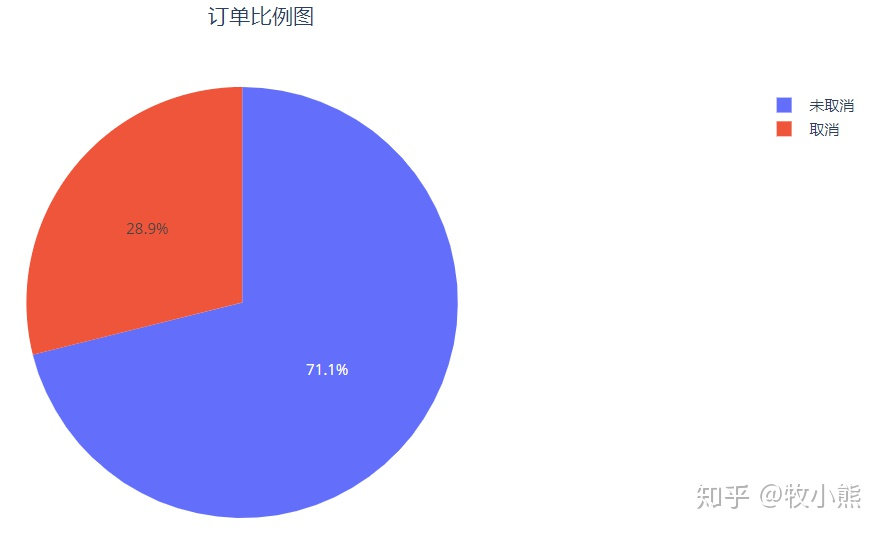
通过饼状图我们看到,大约有28.9%的订单取消了,取消的比例可能是地址填写错了、没有领到优惠劵等情况,使取消支付的比例占有一部分的比例
3.2订单支付比例分析
通过观察数据我们发现了用户有提交了订单,但是没有支付的情况
#找到所有的有效订单
df2 = df[(df['sale_ord_valid_flag'] == 1)&(df['cancel_flag'] == 0)&('before_prefr_unit_price' != 0)]
order_payed = df2['sale_ord_id'][df2['user_actual_pay_amount'] != 0].count()
order_unpay = df2['sale_ord_id'][df2['user_actual_pay_amount'] == 0].count()
labels = ['支付','未支付']
values = [order_payed, order_unpay]
trace = [go.Pie(labels=labels, values=values)]
layout = go.Layout(
title = dict(text='支付比例图',x=0.5)
)
fig = go.Figure(data = trace, layout = layout)
fig

通过饼状图我们可以看到,大约有15%的用户取消了支付,取消支付的比例小于取消订单的比例,因此对于有订单信息的用户但是未支付的,有比较强的购买目的,可能是由于优惠劵或者价格等因素使其取消支付,因此针对这部分用户可能是价格比较敏感的用户,我们可以推送京东优惠卡。
3.3订单价格分布
price_series = df2['after_prefr_unit_price']
price_series_num = price_series.count()
hist, bin_edges = np.histogram(price_series, bins=80)
hist_sum = np.cumsum(hist)
hist_per = hist_sum / price_series_num
bin_edges_plot = np.delete(bin_edges, 0)
trace = go.Scatter(
x = bin_edges_plot,
y = hist_per*100,
mode = 'lines', # 折线图
line = dict(
width = 2
) )
layout = go.Layout(
title = dict(text='订单的价格分布',x=0.5),
xaxis=dict(title='订单价格'),
yaxis=dict(title='百分比(%)',ticksuffix='%')
)
fig = go.Figure(data=trace,layout=layout)
fig
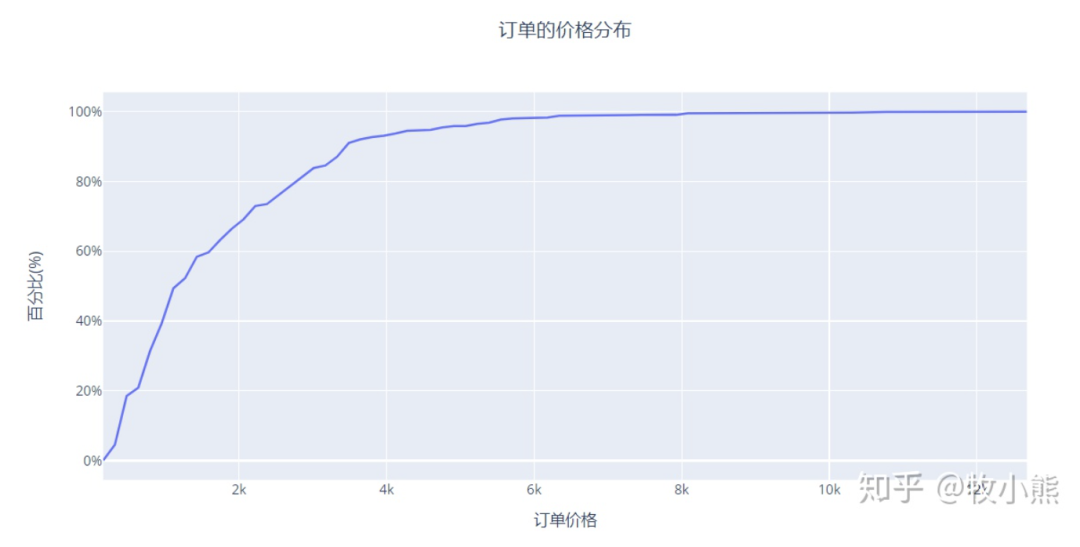
通过分布图可以看到,超过80%冰箱的价格是低于4K的,查过70%的冰箱价格是低于2K的,因此冰箱用户主力消费价格在2K以下,因此在进行冰箱广告推广时,可以优先考虑价格低于2K的冰箱,这类冰箱具有较大的市场。
同时通过观察,冰箱价格在4K以内分布较为均匀,超过4K以后,冰箱累计上升区间缓慢,因此我们可以大致认为,当冰箱的价格超过4K,这部分冰箱价格我们可以认为是偏豪华型的冰箱,具有单个冰箱利润高,但是销售市场占比少。
3.4有效订单与时间的关系
df3 = df2.copy()
df3['order_time_hms'] = df3['sale_ord_tm'].apply(lambda x: x.strftime('%H'))
pay_time_df = df3.groupby('order_time_hms')['sale_ord_id'].count()
x = pay_time_df.index
y = pay_time_df.values
trace = go.Bar(
x = x,
y = y,
text=y,
textposition='outside')
layout = go.Layout(
title = dict(text='不同时间段有效订单分布',x=0.5),
xaxis=dict(title='时间',tickmode='linear'),
yaxis=dict(title='有效订单数')
)
fig = go.Figure(data=trace,layout=layout)
fig
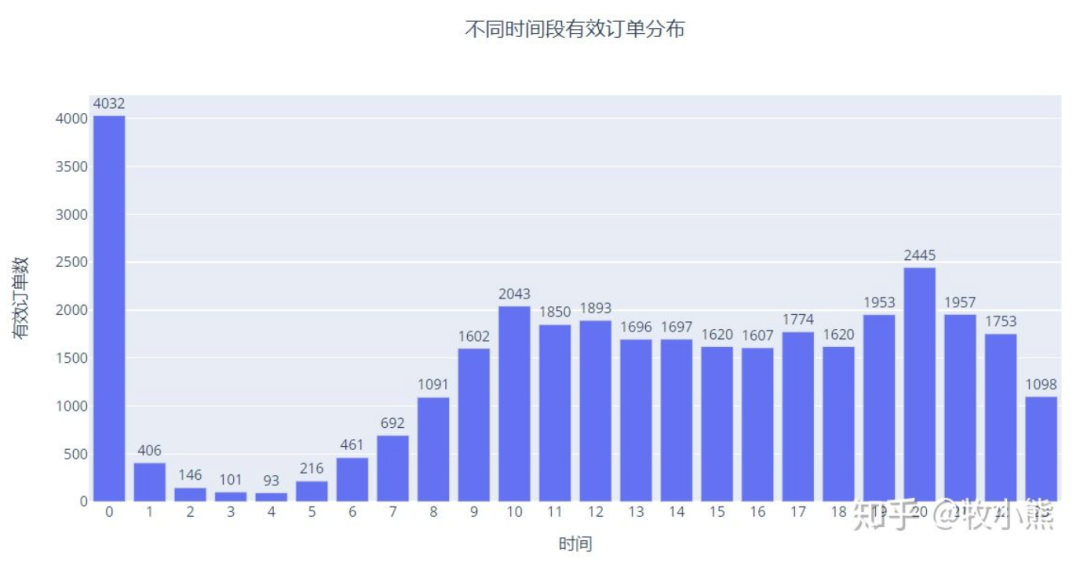
通过观察,0点有效订单数出现了激增的情况,这一部分是出现了异常订单还是说过了0点以后通过抢购物券使这一部分订单增加?
同时,除了0点外,10、20点有效订单数具有一个较高的值,说明用户比较偏向于早上10点和晚上20点付款。早上10点付款推测原因可能是刚到公司,先逛一下京东摸摸鱼,晚上20点推测原因是晚饭后,这个时间距离睡觉还比较早,用户刷手机的频率增加,因此增加有效订单数。
针对0点有效订单数偏高的问题,我们进行进一的分析人均有效订单的情况。
3.5人均有效订单与时间的关系
order_time_df=df3.groupby('order_time_hms')['sale_ord_id'].agg({('order_num','count')}).reset_index()
user_time_df = df3.groupby('order_time_hms')['user_log_acct'].agg({('user_num','nunique')}).reset_index()
order_num_per_user = order_time_df['order_num'] / user_time_df['user_num']
trace = go.Scatter(
x = order_num_per_user.index,
y = order_num_per_user.values,
mode = 'lines', # 折线图
line = dict(
width = 2
) )
layout = go.Layout(
title = dict(text='不同时间段人均订单量的分布',x=0.5),
xaxis=dict(title='时间',tickmode='linear'),
yaxis=dict(title='人均有效订单量')
)
fig = go.Figure(data=trace,layout=layout)
fig

通过观察发现,0点时候的人均有效订单率处于较为正常的值,甚至比1点的有效订单率低,因此有效订单的激增,我们认为很大概率是通过抢优惠劵增加而不是出现了恶意刷单。
同时我们看到20点的人均有效订单率也是处于较为正常的值
3.6人均客单价和平均价在不同时间段的分布
客单价=销售额/顾客数
平均订单价=销售额/订单数
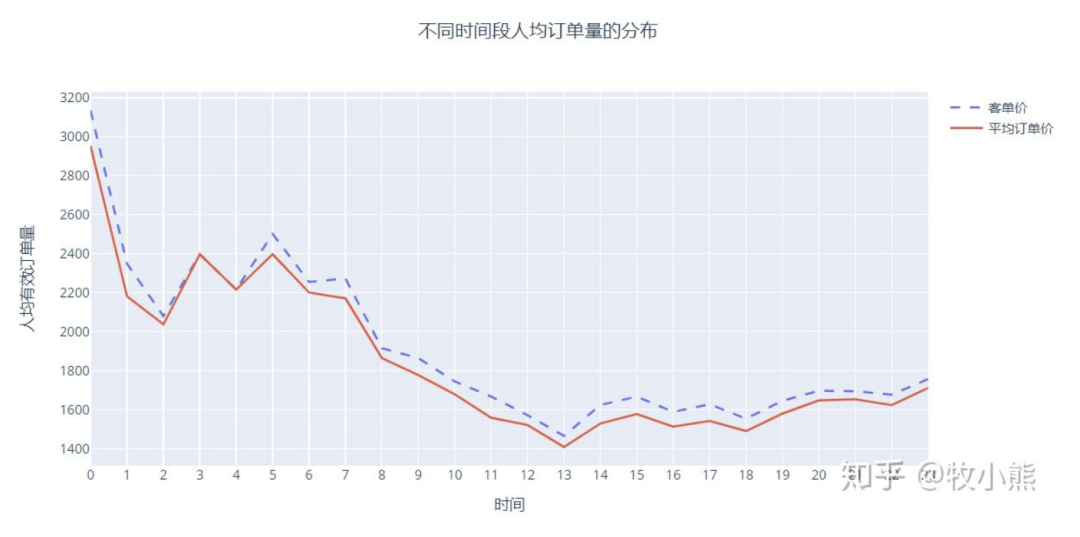
0时客单价和平均订单价在全天有个较高的值,会不会是小部分用户的极端购物行为产生这样的数据呢?
因此我们看一下0时和20时价格订单的分布图
3.7 0时和20时订单价格分布
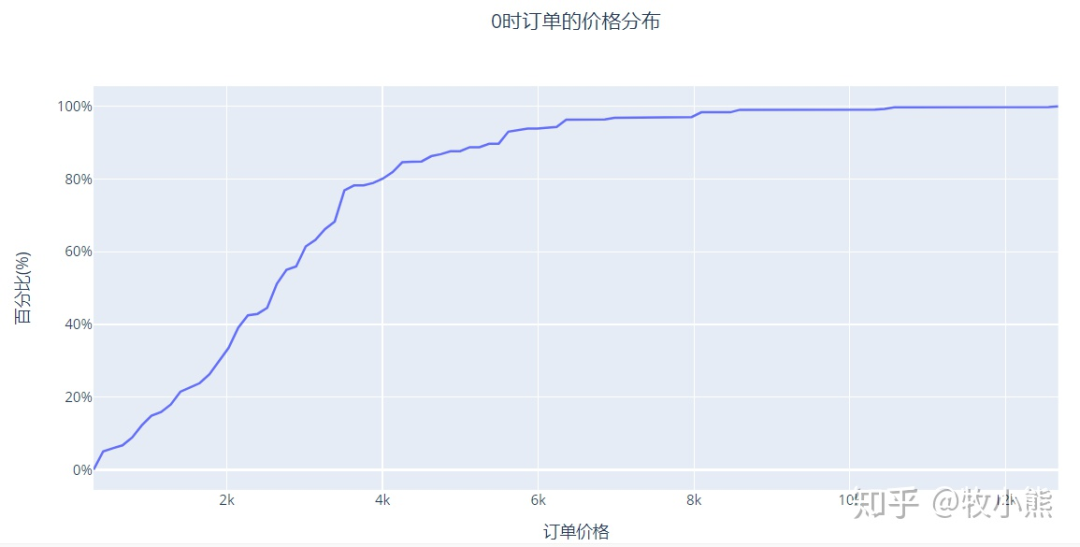

通过看0时和20时不同时间段订单累计分布图我们可以看到
大约20%的0时用户的订单在2K以下,20时用户在2K以下的订单占比为75%
这说明0时的用户并补只有一小部分的订单价格很高,而是0时的用户普遍的购物具有较高的客单价。
因此我们推测,0时用户是否具有一定的冲动购物的情况,而20时购物的用户相对理智一些
也可能时用户为了使用优惠劵使高额的订单大多集中在0时
3.8订单与地区的关系
对于冰箱市场而言,哪些省份是冰箱的头部市场呢?

通过查看不同省份有效订单分布图我们可以看到,订单的市场大多集中在一线城市或者经济较为发达的省份,这部分城市经济发达,对于年轻人有较强大的吸引力,因此购置冰箱的订单数较高。
那么这些不同省份客单价是否会不同?
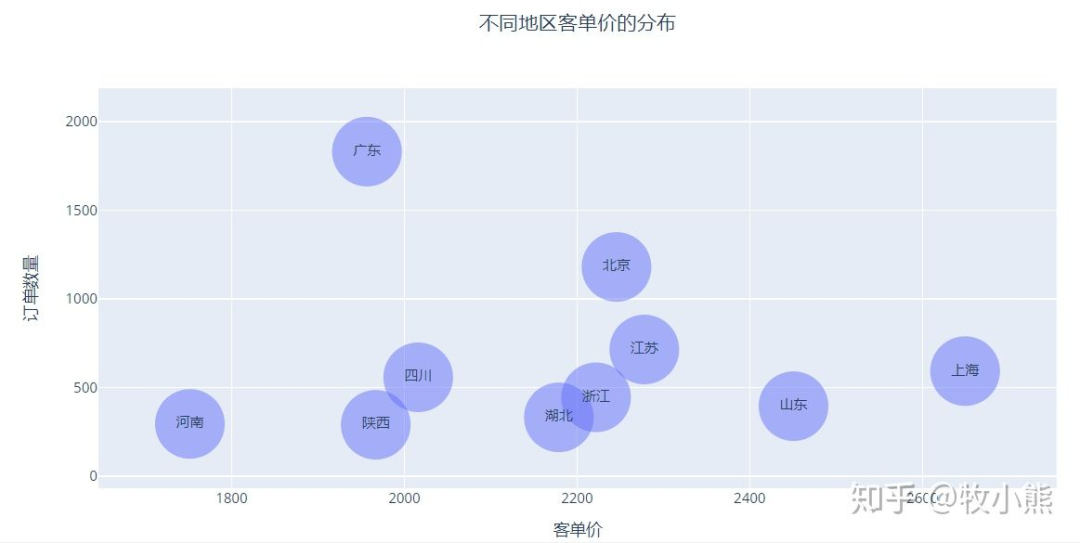
其中上海客单价最高,广东的订单数量最多,因为广州在外贸上具有较大的优势,因此有具有较大的实体工厂,能吸纳较多的低端人才,因此出现订单数量多而客单价不高的情况。
与之相反的是上海作为国家的金融中心,汇聚了较多的金融方向的从业者,因此在消费品质上有一个较大的提升。
最后我们来看看不同品牌的客单价
3.9不同品牌客单价
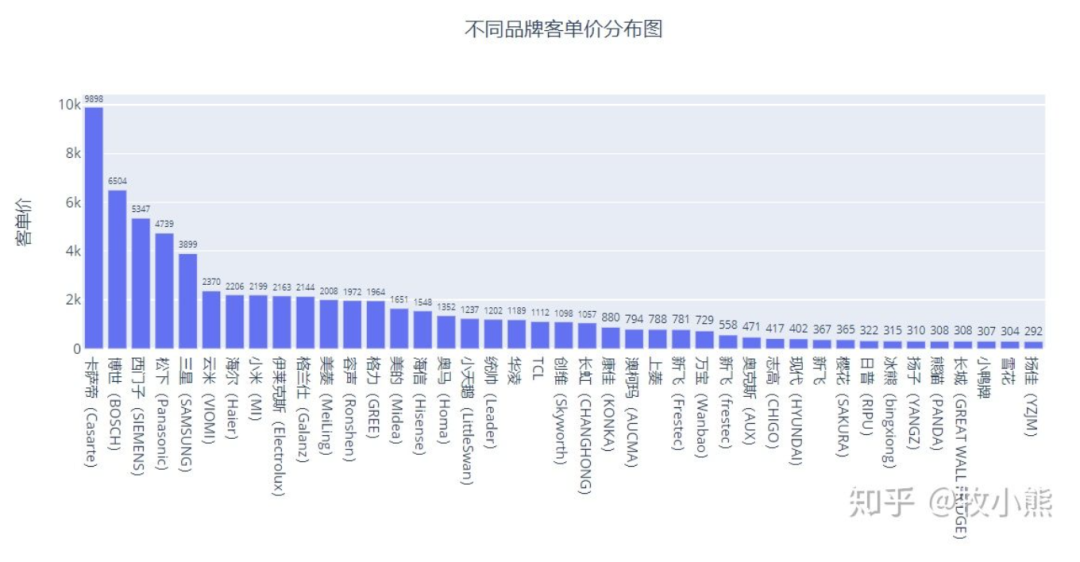
通过图中我们可以看到,卡萨帝稳居客单价排行第一的品牌,妥妥的豪华冰箱品牌
价格的第一梯队品牌有 博世、西门子、松下、三星 平均价格在4K以上
价格的第二梯队品牌有 海尔、小米、伊莱克斯、格兰仕、美的 平均价格在2K以上 其中有不少国产品牌的身影
剩下的品牌价格都在2K以下,这部分市场消费需求大,因此各大品牌在这一区间段价格竞争比较激烈。
4.小结
本项目针对京东的冰箱订单数据进行了分析,在分析过程中没用使用复杂的模型以及炫酷的图表,而是通过普通的数据展示一步步深挖数据产生的原因,并提出了一部分产生数据的原因。因此在数据分析中,往往数据指标的建立对于数据的深挖具有较大的意义,同时针对异常数据提出一定的推测和假设,通过有效的数据分析进行小心求证。
5.项目源码和数据
数据采用utf-8编码,直接打开可能会出现乱码的情况,因此在读取数据时需要指定字符编码集
公众号(Datawhale)后台回复“202013”获取打包的项目源码和数据