
Python下载文件的11种方式
使用Requests

使用wget


下载重定向的文件


分块下载大文件

下载多个文件(并行/批量下载)

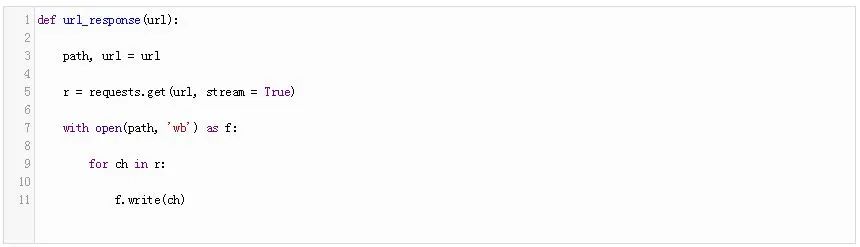



使用进度条进行下载

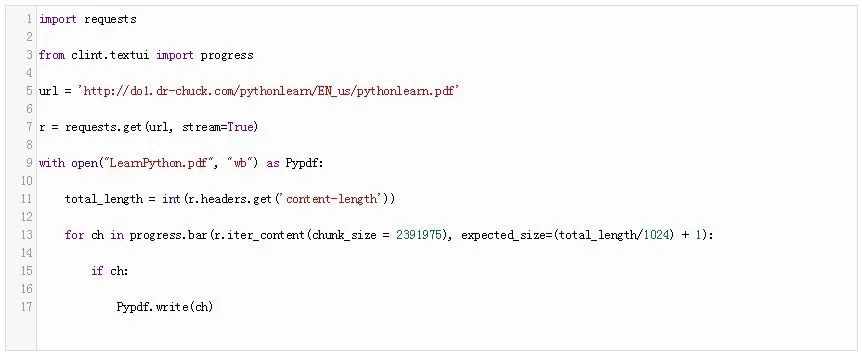
使用urllib下载网页


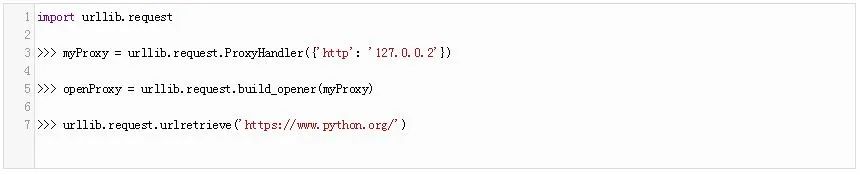
通过代理下载

使用urllib3






使用Boto3从S3下载文件





Bucket名称
你需要下载的文件名称
文件下载之后的名称



使用asyncio



-END- 往期精彩推荐 -- -- 1、这个在线代码编辑器,可以分享给任何人 -- 2、Python 造假数据,用Faker就够了 -- 3、在Python中玩转Json数据 -- 你 “三连” 了吗?

评论