《失控玩家》中的NPC数字意识觉醒,是如何发生的?

大数据文摘授权转载自数据实战派
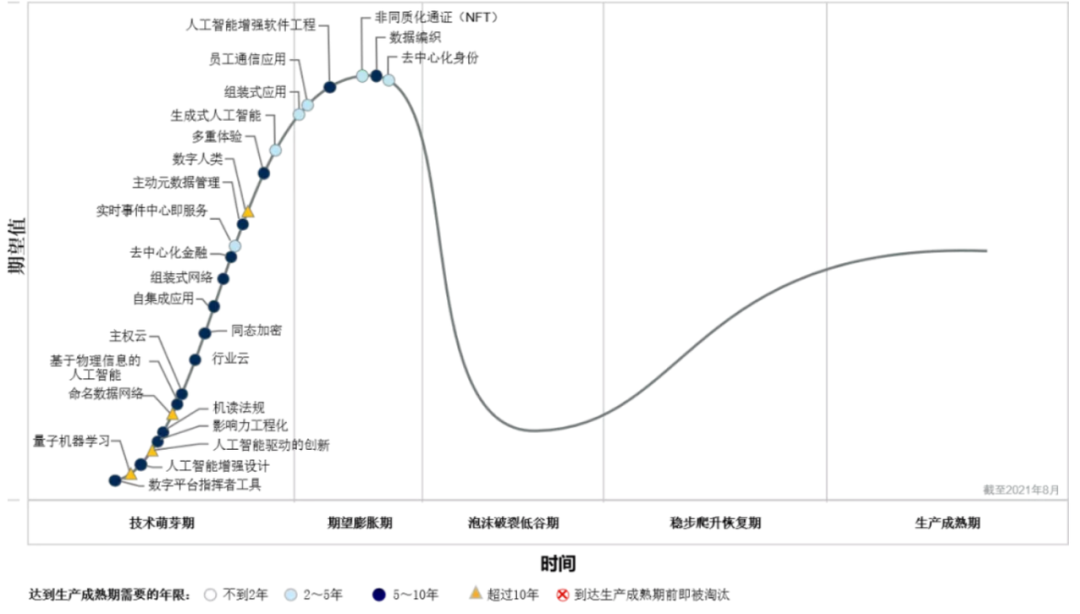
AI仍然具有相当热度。至少它还没有掉出2021年8月的Gartner 新兴技术成熟曲线图。
了解这个概念及其未来几年的价值,仍然比以往任何时候都要重要。
对于好莱坞电影界来说也不例外。作为一种艺术表达形式,电影向来热衷夸大戏剧效果,例如终结者系列中,天网派出的杀手机器人成为人类生存的最大威胁。今天,秉承AI威胁论色彩观点的群体,还常常把这个“坏AI”挂在嘴边。
在这个形象的另一端,AI是人类最好的帮手。他们可以比人类更好地执行模拟和预测等分析任务,协助完成各种任务。同样,有大量好莱坞作品描述了“好AI”。
无论“坏”还是“好”,这些电影中的AI,都反映着人类对于通用人工智能(AGI)究竟能强大到何种程度的想象。但鲜少有作品提及AGI的“起点”在哪,也就是回答这个关键问题——第一个AGI会怎样诞生。
最近上映的热门电影Free Guy 的上映,继续尝试为这个问题的回答添砖加瓦:他将在游戏世界中诞生。
更让我们舒一口气的是,和《西部世界》中AI在杀戮游戏中觉醒不同,Guy 不需要唤醒对人类仇视,而是在一片love &peace 的氛围中,和自己的自主意识相遇。

片中,雷诺茨饰演的Guy,从一个NPC 是突然之间拥有自我意识的,成为了他的缔造者口中的“全世界第一个AGI”,这个变化出乎了所有真实人类的意料。
那么,他究竟是如何从一个NPC进化成AGI的?
从“反应机器”到“自我意识觉醒”
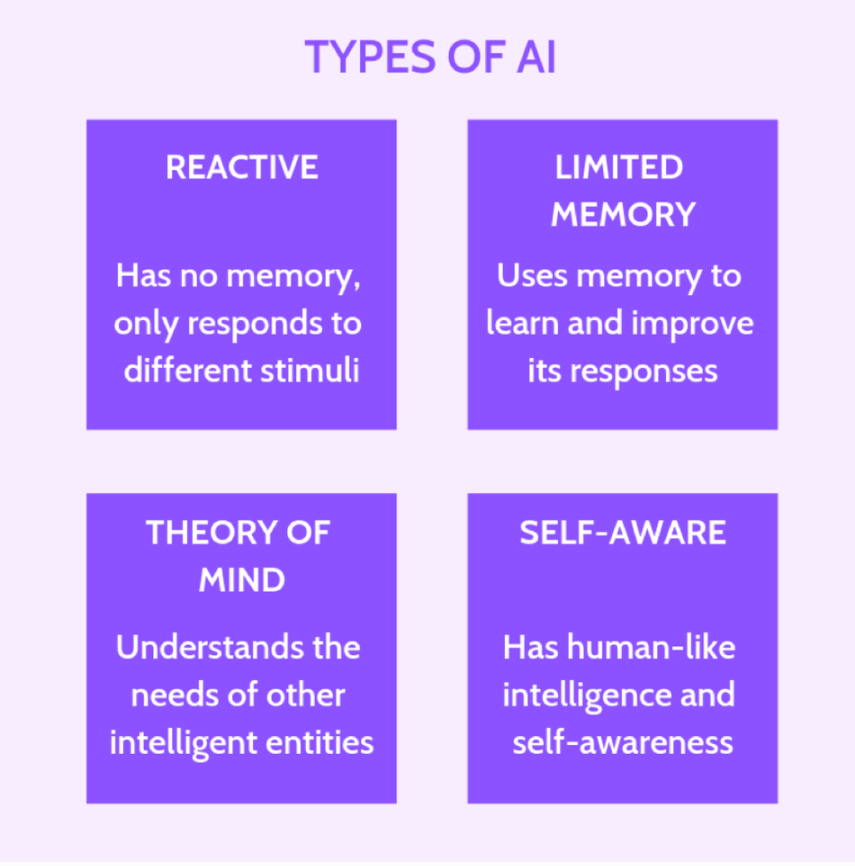
美国密歇根州立大学人工智能专家Arend Hinze曾经将机器划为4种类型,第一种类型是反应机器,Reactive machines,即只能进行反应,但没有记忆能力,也无法利用过去的经验来制定现在的决策。
这些类型的机器在视频游戏中很常见。比如说,一旦玩家进入预先确定的边界,游戏中的敌人可能会发动攻击,它会继续攻击直到你或它被击败。根据游戏设计者设置的条件,其行为会发挥作用。
对玩家来说,你可能感觉得到游戏角色似乎在做决定,但它本质上是在浏览流程图。这些角色的行为大致相同,不会考虑过去发生的事情或未来可能发生的事情,只考虑当下的条件是什么,并从可用的行动中进行选择。可以说,自电子游戏出现以来,这些类型的角色就已经存在。
电影的开头,Guy 就是这样一个尽职尽责的“反应机器”。
每一天,他说着同样的台词,穿同样的衣服,去同样的咖啡馆,点同样的咖啡,见同样的人,过着一成不变的生活。即便遇到不同的游戏玩家在自己工作的银行抢劫,他都同样会在枪响之后抱头卧倒。毕竟,NPC的设定就是游戏的背景衬托,没有属于自己的“想法和感受”。

“咖啡让NPC觉醒”倒不失为一个好的广告创意
回溯到现实的人工智能发展早期,还有一个典型例子,是在1990年代末击败国际象棋大师 Garry Kasparov 的IBM国际象棋超级电脑“深蓝”。“深蓝”虽然可以预测自己和对手接下来的走法,还能在各种可能的走法里面选出最优方案,但它依然对过去没有任何概念,也不记得之前发生过什么。因此,“深蓝”同样是一种反应机器。
麻省理工学院的机器人大佬Rodney Brooks曾在一篇论文Intelligence without representation中表示,人类只应该开发这样的机器。

第二种类型的机器自然比第一类要更进一步,即有限记忆机器,Limited memory。
顾名思义,这类机器希望复刻人类的记忆能力(记忆、学习和根据过往经验制定决策,被认为是人类智能的三大关键能力)。这种机器至少存储一些过去的交互,并使用这些知识来修改未来的行为。这个概念已经更接近于大部分人所设想的人工智能:不仅会思考,而且会学习的机器。
比如说自动驾驶汽车,这类产品已经能够实现一些类似的功能。例如,它们可以观察其他车辆的速度和方向,但这些历史信息存在的时间都很短暂,无法像经验丰富的人类司机那样,将其存储在脑海中的“经验库”。
如何才能开发一套系统,使之可以记住自己的经验,并学会如何应对未知的新情况?
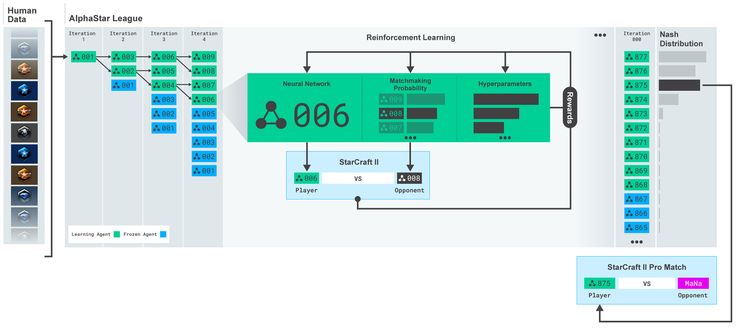
近年来最受瞩目的游戏AI之一——由DeepMind 打造的 AlphaStar AI 正在朝着这个方向迈进。
在开发AlphaStar AI 的过程中,DeepMind使用了一种全新的思路提升智能体的水平。他们设计出智能体联盟(league)这样一个概念。初始化后,每一代训练的智能体在这个联盟之下,然后新一代的智能体需要和整个联盟中的其它智能体相互对抗,通过强化学习训练新智能体的网络权重。这样,智能体会持续不断地挖掘各种可能的作战策略,同时也不会将过去已经学到的策略遗忘掉。
最终,虽然 AlphaStar 没有击败所有人,但它排在前 0.5% 玩家的位置,已经是最高级别。
“有限记忆机器”如果要再往前走一步,那将绕不开——基于心智理论(Theory of mind)的机器。
心智理论是一个心理学概念,意味着明白世界上的人、生物或物体可能拥有影响其自身行为的思想和情感。基于心智理论的机器,不仅能够形成对世界的认识,还可以形成其他代理或实体的认识。即他们认识并理解其他具有感觉和意图的思维实体的存在。这种理解对于合作至关重要,意味着机器不仅能够理解特定任务,而且更全面地理解周围的世界。
这种能力让人们可以展开社交互动,能够理解彼此的动机和意图,是人类形成社会群落的关键所在。
如果AI最终能够与人类在文明的岁月中并肩行走,他们就必须能够明白,每个人都有思想和感受,会对他人形成一定的预期,并动态地调整自己的行为。
目前,在我们的真实世界中,即使是最强大的人工智能,也只能根据他们从交互中获得或收集的信息进行操作,远远没有达到心智理论的层次。

人工智能发展的最后一步,可能是构建一套能够形成自我意识(Self-awareness)的机器。
从某种意义上讲,自我意识机器是第三类心智理论机器的延伸。
简单而言,“我想要那个东西”与“我知道我想要那个东西”还是有着很大的差异。后者是真正的自我意识,如果说心智理论更强调对外部思维体的感知的话,那么自我意识则是向内的感知,生命能够意识到自我,知道自己的内部状态,而且可以预测他人的感受。
在Free Guy这部电影中,男主角Guy有一个比较明显的从“反应机器”到“自我意识觉醒”的过程。是大热游戏《自由城》里的“工具人”,即游戏里的背景人物,是电脑程序,并非是真人。
最初,Guy作为工具人,他的生活每日重复着固定的动作。直到有一天,他突然觉得自己的生活虽然几近完美,但这种完美让他感觉到一种空虚,自己的生活好像缺了点什么。当他开始寻找究竟缺了什么的时候,进化的第一步就迈出去了。他开始渴望变化,而这种渴望是违背所有NPC原本设定的。
Guy第一次明显的自我觉醒,来自他意识到自己想喝不一样的咖啡。这时,电影中出现了意味深长的一幕,街边的坦克将炮口缓缓地转向了企图突破不变、寻求变化的NPC,Guy只好在保平安的本能支配下,暂时放下这种突然的自我。
但是压抑并没有持续太久,在坠入与女主角的爱河之后,他彻底完成了走向第四个类型的转变。
这个重要的变化也被他的缔造者所捕获,在发现Guy拥有了自我意识之后,2位真实世界的程序员惊呼“我们创造了世界上第一个AGI”。
Guy的自我意识觉醒是在一系列先决条件中成长起来,这一点和《创:战记》(Tron Legacy) 中的 IO类似,后者同样是从游戏环境中的经验中学习。
虽然电影中对于技术的着墨并不多,但是电子游戏成为第一个AGI诞生的土壤的这个设定,同样也非常具有现实意义。用电子游戏训练AI甚至AGI,早已不再停留在科幻层面了。
游戏如何能训练出AGI?
游戏和人工智能有很悠久的渊源。早在人工智能被定义成一个专业范畴时,早期的计算机科学家就试图通过游戏编程来测试计算机是否能通过某种形式的“智能”来解决游戏中的问题。

1957年,像房间一样大的计算机正在和阿瑟•谬瑟尔进行跳棋博弈,最终计算机还是获胜了
上世纪70年代起,电子视频游戏开始在全世界范围内产生影响,它以商业娱乐媒体的方式出现后,与电影、电视等媒介竞争,成为视觉娱乐产业中的不可忽视的主导力量。
但要说电子视频游戏悄悄成为训练和测试AI/AGI的新基准,还是本世纪这头几十年的事情。
在此,不如先来厘清 AGI 这个概念指的是什么。
AI学者Ben Goertzel认为,“通用智能涉及在各种不同的背景和环境中实现各种目标和执行各种任务的能力”;澳大利亚国立大学教授Marcus Hutter 、DeepMind联合创始人Shane Legg则共同提出,“智能是对智能体在各种环境中实现目标的通用能力的衡量”……如你所见,目前行业内对此还没有一个完全公认的解释,但基本都因锚定人类的智能而显得大同小异。

你可以将其简单理解为,在限定资源的条件下,通用人工智能可以解决人可以解决的所有任务和问题。
所以,电子视频游戏是如何与AGI产生直接联系的?
首先,电子视频游戏可以视作人类真实世界的迷你副本,但有一些变化和简化。游戏中的角色是agent,需要在这个迷你世界中解决其中的各种任务。此外,电子视频游戏的计算资源和知识量都是有限的。这些属性都符合上面提到的这些 AGI 定义。
而且电子视频游戏能充分调动人们的各种感官和综合能力。
就算是超级玛丽游戏,它都要求你有敏捷的反应,视觉理解和动作协调性,对路径的判断力,对于风险奖励的取舍能力,对敌人和角色接下来的预测能力,对在规定时间通关的掌控能力。还有一些游戏要求你对信息的获取能力(比如星际);剧情的理解能力(比如天际);或者长久的规划力(比如文明)。
拥有好的测试台对人工智能研究来说很关键。游戏就是人工智能的测试台,因为它们为人工智能提供了各种挑战,视频游戏可以在不同可控环境下运行,在极短的时间内可以运行上千种变化,为学习算法创造了条件。
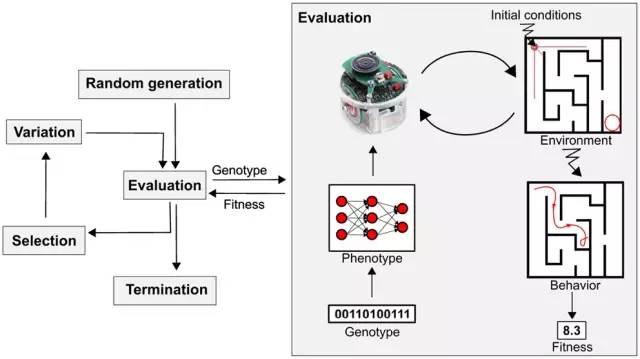
机器在游戏中进化的示意图
目前在利用游戏开发AGI的道路上走得最为坚定且最远的公司,应该是DeepMind。
这家公司将神经系统科学家、人工智能程序员、电脑游戏设计者、国际象棋神童这几类人前所未有地集结在一起,旨在利用游戏和强化学习开发AGI。
与当前借助深度学习方法“克隆”人类智能中的多种单点能力(例如视觉、听觉)不同,最近一篇系统阐释他们方法论的文章中,DeepMind表示,创建AGI需要一种简单但有效的规则。
奖励最大化就是这个规则。“Reward is Enough”。
他们认为,奖励最大化这一通用目标,足以驱动自然智能和人工智能中至少大部分的智能行为。人类智能是在这种规则的支配下经过长期自然选择进化而得的产物。
在游戏中开发Agent,正是在电子世界复现这个自然规则。因为,强化学习算法强调的就是通过采取行动和获得反馈来发展行为,类似于人类和动物通过与环境互动来学习的方式。
因此,一些科学家将强化学习描述为“第一个智能计算理论”。

他们近期一项令人印象深刻的工作,是训练了一种能够在不需要人类交互数据的情况下玩许多不同游戏的智能体。这个新项目包括一个具有真实动态的 3D 环境,和一个可以学习解决各种挑战的深度强化学习智能体。
DeepMind 的说法是,新系统是“朝着创建更通用智能体迈出的重要一步,具有在不断变化的环境中快速适应的灵活性”,但也离实现AI领域数十年梦寐以求的通用智能依然非常远。
Anyway,无论前路多么漫长,这颗种子已经埋下。说不定,第一个AGI 真的就藏身于你一直在玩的电子游戏中。