GPT迭代成本「近乎荒谬」,Karpathy 300行代码带你玩转迷你版
共
2509字,需浏览
6分钟
·
2020-08-26 03:09

来源:reddit
编辑:小智
【新智元导读】最近,特斯拉AI总监Karpathy开源了一个名为minGPT的项目,用300行代码实现了GPT的训练。没有OpenAI的超级算力,该如何调整GPT这类语言模型的各种超参数?
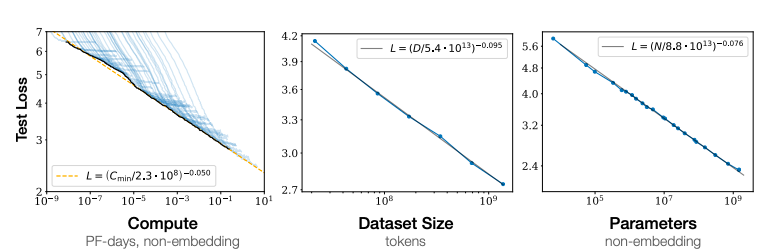
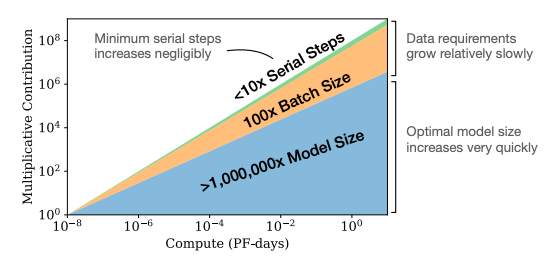
上周 Andrej Karpathy 发布了一个最小 GPT 实现的项目 ,短短一周就收获了4200星。从代码来看,他的minGPT实现确实精简到了极致,利用Karpathy的代码,你只需要实例化一个GPT模型,定好训练计划就可以开始了,整个实现只有300行PyTorch代码。但是最有趣的部分是300行代码背后的故事。特别是在说明文档末尾,他解构了GPT-3的各种参数:GPT-3:96层,96个头,d _ 模型12,288(175B 参数)。GPT-1-like: 12层,12个头,d _ 模型768(125M参数)GPT-3使用与 GPT-2相同的模型和架构,包括修改后的初始化方法等。在transformer层使用交替密集和局部稀疏注意力,类似于稀疏 Transformer。前馈层是瓶颈层的四倍,即 dff = 4 * dmodel。所有模型都使用 nctx = 2048 token的上下文窗口。Adam 的参数 β1 = 0.9, β2 = 0.95, eps = 10^−8。前3.75亿token用线性 LR 预热,剩下的2600亿token用余弦衰减法将学习率降至其值的10%。GPT-3的工程师们是如何确定学习速率的,以及其他的7个超参数 + 架构?GPT-3迭代成本相当高(一次训练可能需要几天到一周)。选择正确的超参数对于算法的成功至关重要,如果够幸运,模型的复杂度不高,可以使用超参数搜索方法。事实上,许多研究人员都注意到,其实可以将其他问题中「穷举搜索」到的许多参数保持在冻结状态,并将搜索的复杂性降低到一些关键参数,如学习速率。另一方面,考虑到 GPT-3的庞大规模和训练成本,显然 OpenAI 的研究人员不可能通过超参数搜索来获得结果,单次训练可能花费数百万美元。那么,在这种「近乎荒谬」的迭代成本范式中,研究人员如何确定最终确定这些参数呢?在训练过程中是否有干扰,比如在检查点重新设置并重新开始?是否会用过超参数搜索越来越大的模型,然后猜测超参数的大致范围?当真正的迭代不可能时,如何继续AI模型的训练?相信很多人工智能的研究者有类似的疑问,很多训练调参还是要靠「直觉」。但是GPT-3这种大规模模型的成功,是不是用了什么更科学的方法?OpenAI其实发表过一篇论文,探讨了如何更好地训练GPT这类语言模型。随着模型大小,数据集集大小和用于训练的计算资源增加,语言模型的性能总是平稳提高的,为了获得最佳性能,必须同时放大所有三个因素。当另外两个因素没有限制时,模型性能与每个因素都有幂律关系。GPT3的工程师们用非常小的模型做了大量的测试,找到了相关的缩放曲线来决定如何分配计算/数据/模型大小,以便在给定的预算下获得最佳性能,他们检查了以前在transformer上的超参数设置和架构选择 ,发现 GPT 对前者相对不敏感,应该扩大数据范围,以饱和 GPU 的吞吐量。模型性能依赖于规模,它由三个因素组成:模型参数N的数量(不包括嵌入),数据集D的大小以及训练所用计算资源C。结果显示,在合理的范围内,性能模型的体系结构参数依赖较小,例如模型的深度与宽度。只要同时扩大N和D的规模,性能就会显著地提高,但是如果N或D保持不变而另一个因素在变,则进入性能收益递减的状态。性能损失大致取决于N^0.74 / D的比率,这意味着每次我们将模型大小增加8倍时,我们只需将数据增加大约5倍即可避免损失。当固定计算资源C,但对模型大小N或可用数据D没有任何其他限制时,可以通过训练非常大的模型并及时停止来获得最佳性能。因此,最大程度地提高计算效率将比基于训练小型模型进行收敛所期望的收益高得多,训练数据的需求量和计算资源遵循D〜C^0.27,可以看到数据需求增长十分缓慢。如果有更多的计算资源可用,可以选择分配更多资源来训练更大的模型,使用更大的批次以及训练更多的步数。比如将来算力增长了十亿倍,为了获得最佳的结果,大部分精力应该用于增加模型大小。数据的增加可以通过增加批处理量来提高并行度,只需要很少的时间。我们没有过多讨论超参数的具体调整方法,在计算资源有限的情况下,确实需要一些技巧,来提升计算效率,或者说模型的性能,当未来算力足够时,我们就不会这么依赖超参数了。「如果你真的在做研究,那么通常情况下,你研究的问题越小越简单,研究贡献越大」。任何人都可以通过使问题更难,神经网络更大来显示改进,但是如果你可以用一个新的小而简单的设计来产生更好的性能,那么就会进一步提高理解能力。如果你能在一个简单的toy case上演示一些神经网络的bug或者其他有趣的特性,就会更加理解它是如何发生的,何时发生的,以及为什么会发生。https://arxiv.org/pdf/2001.08361.pdfhttps://www.reddit.com/r/MachineLearning/comments/ibrlvt/d_how_do_ml_researchers_make_progress_when/

点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报




 下载APP
下载APP