有一类业务场景:
(1)超高吞吐量,每秒要处理海量请求;
(2)写多读少,大部分请求是对数据进行修改,少部分请求对数据进行读取;
这类业务,有什么实现技巧么?
接下来,一起听我从案例入手,娓娓道来。
(1)司机地理位置信息会随时变化,可能每几秒钟地理位置要修改一次;(2)用户打车的时候查看某个司机的地理位置,查询地理位置的频率相对较低;void SetDriverInfo(long driver_id, DriverInfo info);DriverInfo GetDriverInfo(long driver_id); (2)返回value也定长,例如:司机实体序列化后的二进制串;这个kv内存缓存是一个临界资源,对它的并发访问,有什么注意事项么?void SetDriverInfo(long driver_id, DriverInfo info){
WriteLock (m_lock);
Map= info;
UnWriteLock(m_lock);
}
DriverInfo GetDriverInfo(long driver_id){
DriverInfo t;
ReadLock(m_lock);
t= Map;
UnReadLock(m_lock);
return t;
}
假设快狗打车有100w司机同时在线,每个司机每5秒更新一次经纬度状态,那么每秒就有20w次写并发操作。假设快狗打车日订单1000w个,平均每秒大概也有300个下单,对应到查询并发量,大概每秒1000级别的并发读操作。在这样的吞吐量下(每秒20w写,1k读),锁m_lock会成为潜在瓶颈,导致Map访问效率极低。有什么潜在的优化方法么?
锁冲突之所以严重,是因为整个Map共用一把锁,锁的粒度太粗。
画外音:可以认为是一个数据库的“库级别锁”。
是否可能进行水平拆分,来降低锁冲突呢?
答案是肯定的。
画外音:类似于数据库里的分库,把一个库锁变成多个库锁,来提高并发,降低锁冲突。
我们可以把1个Map水平切分成N个Map:
void SetDriverInfo(long driver_id, DriverInfo info){
i = driver_id % N; // 水平拆分成N份,N个Map,N个锁
WriteLock (m_lock[i]); //锁第i把锁
Map[i]= info; // 操作第i个Map
UnWriteLock (m_lock[i]); // 解锁第i把锁
}
(1)一个Map变成了N个Map,每个Map的并发量,变成了1/N;有没有可能,进一步细化锁粒度,一个元素一把锁呢?
答案也是肯定的。
画外音:可以认为是一个数据库的“库级别锁”,优化为“行级别锁”。
不妨设driver_id是递增生成的,并且假设内存比较大,此时可以把Map优化成Array,并把锁的粒度细化到最细的,每个司机信息一个锁:void SetDriverInfo(long driver_id, DriverInfo info){
index = driver_id;
WriteLock (m_lock[index]); //超级大内存,一条记录一个锁,锁行锁
Array[index]= info; //driver_id就是Array下标
UnWriteLock (m_lock[index]); // 解锁行锁
}
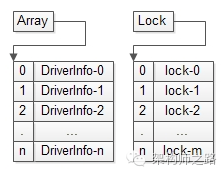
这个方案使得锁冲突降到了最低,但锁资源大增,在数据量非常大的情况下,内存往往是装不下的。画外音:数据量比较小的时候,可以一个元素一把锁,典型的是连接池,每个连接用一把锁表示连接是否可用。写多读少的业务,有一种优化方案:无锁缓存,将锁冲突降低到。
如果缓存不加锁,读写吞吐量可以达到极限,但是多线程对缓存中同一块定长数据进行写操作时,有可能出现不一致的脏数据。画外音:作为缓存,允许cache miss,却不允许读脏数据。
(1)线程1对缓存进行操作,对key想要写入value1;(2)线程2对缓存进行操作,对key想要写入value2;(3)不加锁,线程1和线程2对同一个定长区域进行一个并发的写操作,可能每个线程写成功一半,导致出现脏数据产生,最终的结果即不是value1也不是value2,而是一个乱七八糟的不符合预期的值value-unexpected;并发写入的数据分别是value1和value2,读出的数据是value-unexpected,数据被篡改,这本质上是一个数据完整性的问题。例如:运维如何保证,从中控机分发到上线机上的二进制没有被篡改?又例如:即时通讯系统中,如何保证接受方收到的消息,就是发送方发送的消息?发送方除了发送消息本身,还要发送消息的签名,接收方收到消息后要校验签名,以确保消息是完整的,未被篡改。加入“签名”保证数据的完整性之后,读写流程需要如何升级?加上签名之后,不但缓存要写入定长value本身,还要写入定长签名(例如16bitCRC校验):(1)线程1对缓存进行操作,对key想要写入value1,写入签名v1-sign;(2)线程2对缓存进行操作,对key想要写入value2,写入签名v2-sign;(3)如果不加锁,线程1和线程2对同一个定长区域进行一个并发的写操作,可能每个线程写成功一半,导致出现脏数据产生,最终的结果即不是value1也不是value2,而是一个乱七八糟的不符合预期的值value-unexpected,但签名,一定是v1-sign或者v2-sign中的任意一个;画外音:16bit/32bit的写可以保证原子性。(4)数据读取的时候,不但要取出value,还要像消息接收方收到消息一样,校验一下签名,如果发现签名不一致,缓存则返回NULL,即cache miss;当然,对应到司机地理位置,除了内存缓存之前,肯定需要timer对缓存中的数据定期落盘,写入数据库,如果cache miss,可以从数据库中读取数据。总结
(2)Map转Array的方式来最小化锁冲突,一条记录一个锁;(4)通过签名的方式保证数据的完整性,实现无锁缓存;如果你喜欢本文,大概率会喜欢这个架构训练营,欢迎一起来玩。

