
nginx、zuul都有哪些服务代理,基于zuul我们可以灰度发布
通过路由代理角度、解读集中常见的路由代理方式
常见方式
nginx+lua
nginx是一种高性能HTTP反向代理服务器。在我们之前的项目中我们使用nginx主要有两种用途:方向代理+静态资源服务器管理
点我下载哦
下载完成之后nginx的启动也很是方便,笔者这里演示的是windows版本的。你可以直接点击应用程序也可以直接通过命令行模式启动
./nginx或者nginx。看具体系统
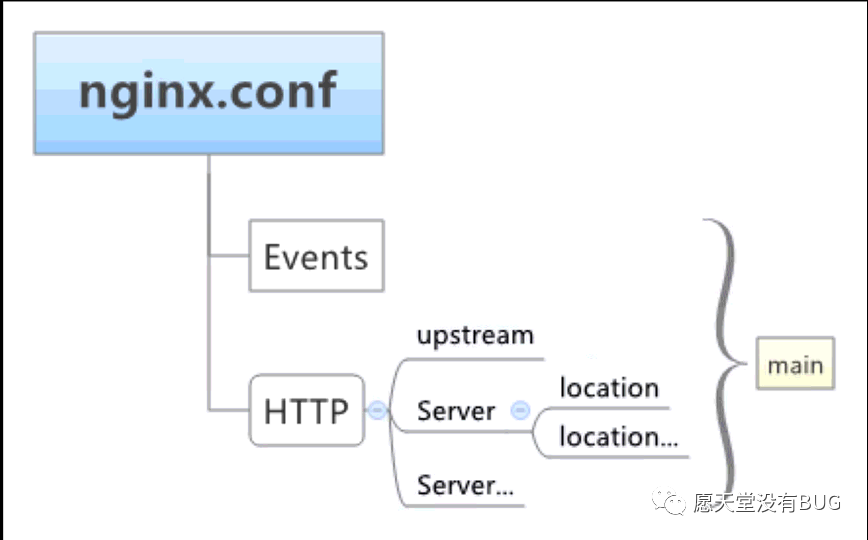
服务代理
正常情况下的代理是使用发哦HTTP下的Server来配置的。比如我们下面需要简单代理下我们某个服务
http://192.168.44.131:9200.。我们想要的效果就是通过本地localhost就可以访问到这个服务提供的接口了。
server {
listen 9200;
server_name localhost;
location / {
proxy_pass http://192.168.44.131:9200;
#root html;
#index index.html index.htm;
}
}
复制代码当然配置结束后我们需要进行
nginx -s reload进行重启nginx才能重新加载配置。这个时候我们访问localhost:9200/zxhtom/start实际上就是被代理到http://192.168.44.131:9200/zxhtom/start这个接口上。
静态资源代理
上面我们说了除了服务代理之外。nginx还可以作为静态资源服务器使用。
server{
listen 90;
server_name localhost;
location / {
root D:\study\PageOffice_4.6.0.3_Java;
index index.html;
}
}
复制代码同样是使用了HTTP下的SERVER 。这段代码表示将本地
D:\study\PageOffice_4.6.0.3_Java这个文件夹作为本地90端口的入口。我们通过localhost:90/index.html就能访问到本地的D:\study\PageOffice_4.6.0.3_Java\index.html文件了。
负载均衡
upstream redis {
hash $remote_addr consistent;
# $binary_remote_addr;
server 192.168.44.131:6379 weight=5 max_fails=3 fail_timeout=30s;
server 192.168.44.132:6379 weight=1 max_fails=3 fail_timeout=30s;
}
server {
listen 6379;#redis服务器监听端口
proxy_connect_timeout 10s;
proxy_timeout 300s;#设置客户端和代理服务之间的超时时间,如果5分钟内没操作将自动断开。
proxy_pass redis;
}
复制代码有的时候我们服务并不仅仅是单节点服务。如果是分布式的话我们需要对服务进行负载均衡策略。这个时候我们就无法仅仅代理服务了。需要我们添加负载策略。我们通过
upstream来定义服务,并对服务进行策略定义。最后我们在server中直接时候用upstream的服务名就可以了。其中的weight就是对集群中服务轮询的权重设置。
常用命令
重启:nginx.exe -s reload
关闭:nginx.exe -s stop
检测配置合法性:nginx.exe -t
zuul
zuul是netflix开源项目,关于zuul的深入浅出我在之前的文章中解析的应该算是很全面了。点我看zuul章节
通过zuul我们可以实现动态路由、认证授权、动态过滤器、最终要的是可以自定义还可以结合hystix进行服务熔断
zuul还可以实现灰度发布这个可以解决我们的停机发布问题。想想如果你的系统是24小时不能停机的那么zuul实现灰度发布
灰度扩展
上述我们通过请求中指定的参数实现了路由的转发实现原理是借助了eureka的metadata的参数属性路由的。
但是我们在平时应该遇到过有些软件对不同地区进行不同对待。
比如说支付宝蚂蚁森林不同城市有不同的策略
比如说某软件邀请你参与内侧版本使用
上述都统称为灰度发布,原理也很简单实际上就是有多个实例,zuul根据请求的特征转发到不同的实例上。不同城市就是根据地区来路由,邀请内侧就是通过个人用户信息来路由。他们的实现都离不开我们上面描述的
Ribbon.Predicate。想要对灰度发布进行扩展我们就离不开Predicate
Predicate
该类的作用就是进行断言,是google提出的思想。具体有关google轻轻点我
在ribbon专题中,我们简单的通过源码阅读的方式了解了ribbon是如何进行负载均衡以及内部负载均衡的策略的。有兴趣的可以点击主页查找。
今天我们来看看ribbon在负载均衡之前是如何在获取服务列表之后进行过滤的。
//根据输入返回断言 true or false
@GwtCompatible
public interface Predicate<T> {
//针对输入内容进行断言,该方法有且不仅有如下要求:1、不会造成任何数据污染 2、在T的equals中相等在apply中是相同效果
boolean apply(@Nullable T input);
//返回两个Predicate是否相同。一般情况Predicate实现是不需要重写equals的 。如果实现可以根据自己需求表明predicate是否相同。什么叫做相同就是两个predicate对象apply的结果相同即为对象相同
@Override
boolean equals(@Nullable Object object);
}
复制代码下面我们通过Predicate来实现下简单数据过滤。当然有的人会说为什么不用java8 stream过滤呢。这里只是为了为Ribbon中服务过滤铺路。至于ribbon为什么不使用流操作呢?个人角色google的Predicate在解耦上更加的方便吧。
@Test
public void pt() {
List<User> userList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
userList.add(new User(Long.valueOf(i+1), "张三"+(i+1)));
}
Predicate<User> predicate = new Predicate<User>() {
@Override
public boolean apply(User user) {
return user.getId() % 2 == 0;
}
};
ArrayList<User> users = Lists.newArrayList(Iterables.filter(userList, predicate));
System.out.println(users);
}
复制代码AbstractServerPredicate
前提回要
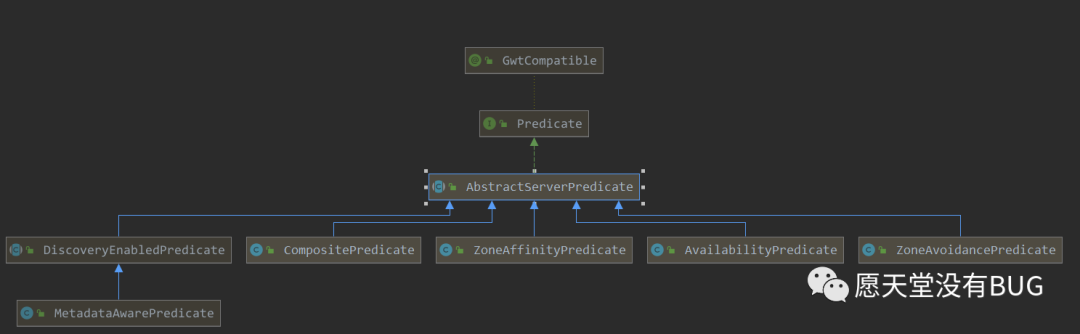
上面我们的类结构图中可以看出
AbstractServerPredicate是Predicate的实现类。这个类也是Ribbon在获取服务列表的关键角色。因为后面都是基于这个类进行功能扩展的。

jmnarloch初识
这是我在RIbbon中的内容。我们可以知道Ribbon最终是在
BaseLoadBalancer中进行负载均衡的。其内部的rule默认是new RoundRobinRule(),因为我们引入了io-jmnarloch。先看看内部的类结构
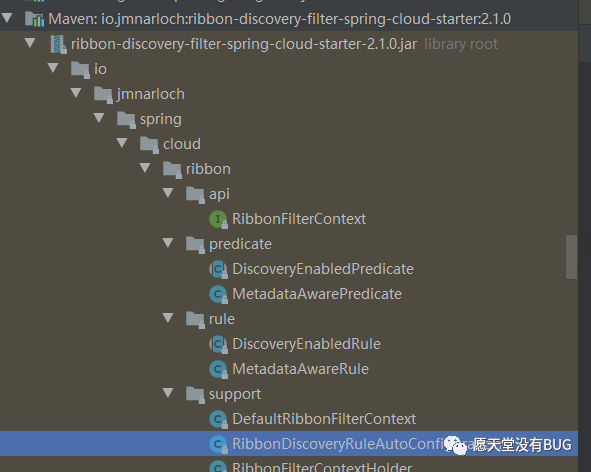
io-jmnarloch内部不是很复杂,至少Ribbon、feign这些比起来他真的是简单到家了。内部一个四个package
| package | 作用 |
|---|---|
| api | 提供上下文,供外部使用 |
| predicate | 提供获取服务列表过滤器 |
| rule | ribbon中的负载均衡策略实现 |
| support | 对上述的辅助包 |
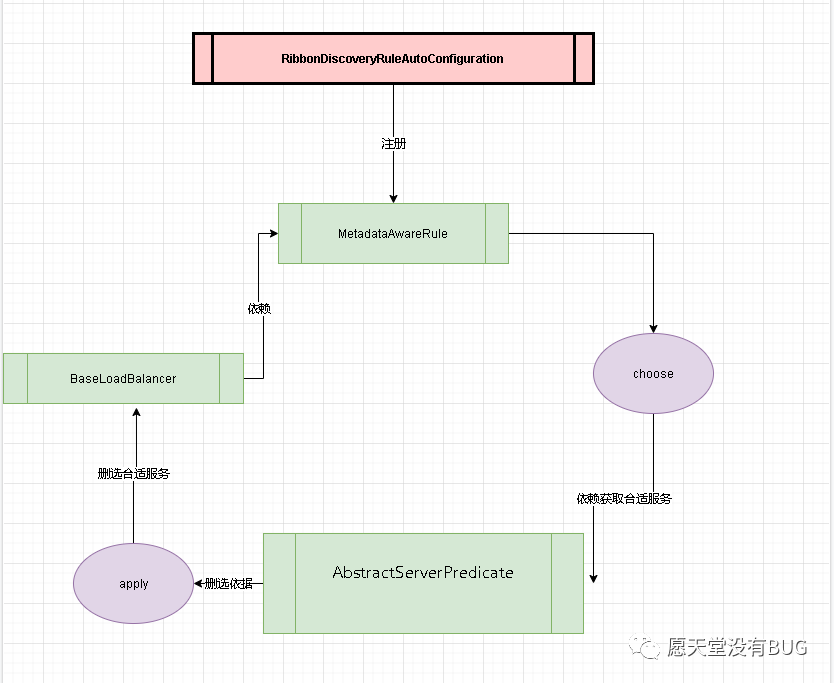
注册负载Rule
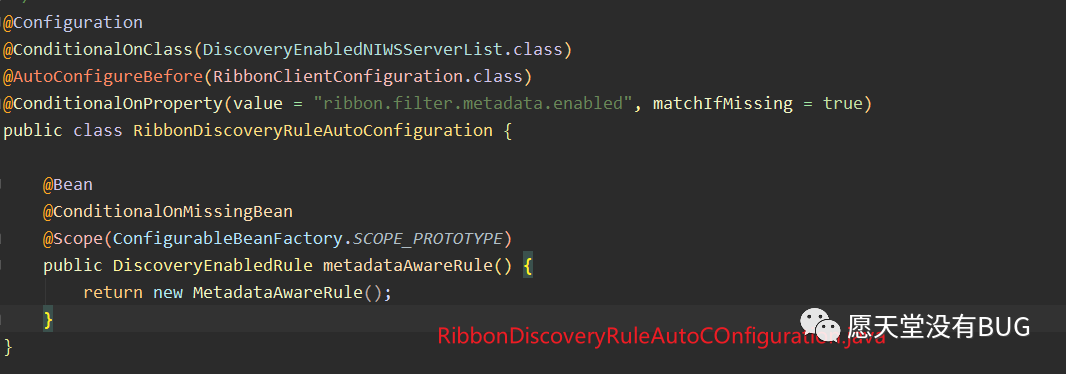
我们可以看到在support包中的
RibbonDiscoveryRuleAutoConfiguration中配置了rule包下定义好的Ribbon的负载均衡类Rule。
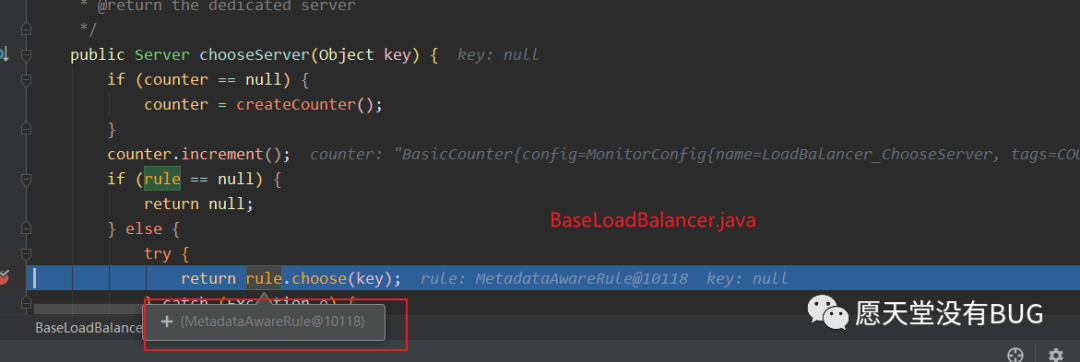
断电打到
BaseLoadBalancer中我们可以看到rule就是我们rule.MetadataAwareRule这个类。这里和ribbon章节说的好像有出入,我们在ribbon章节说需要自定义rule的时候需要在@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration = MySelfRule.class)这种方式。其实在配置
DiscoveryEnabledRule的时候在注册的时候有@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)表示作用域
MetadataAwareRule如何过滤服务
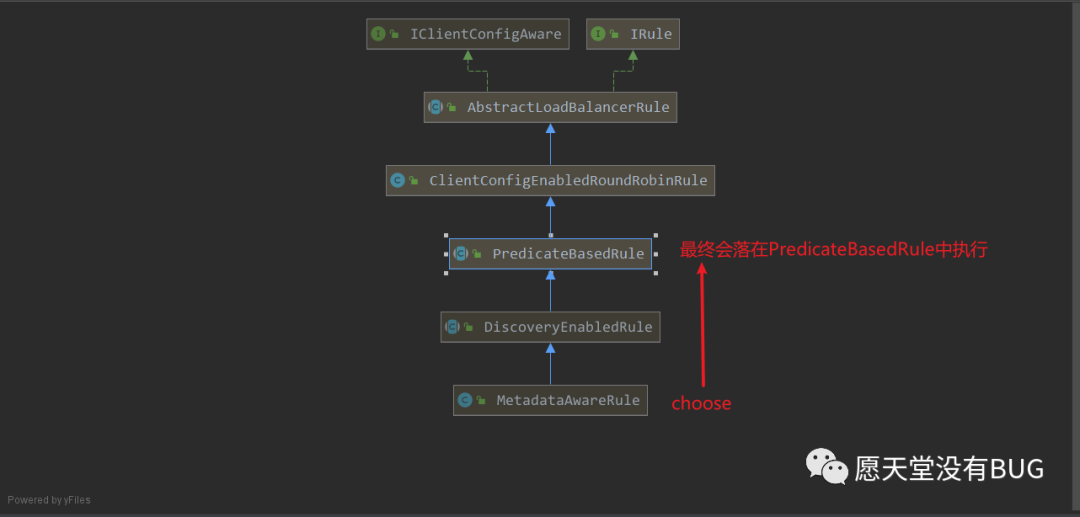
通过
MetadataAwareRule结合代码我们可以了解到最终是PredicateBaseRule#choose 在选择服务列表
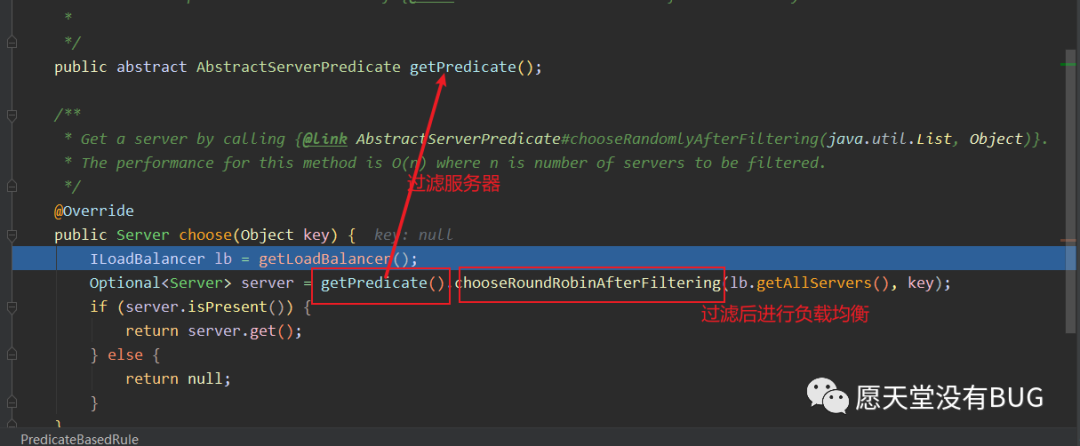
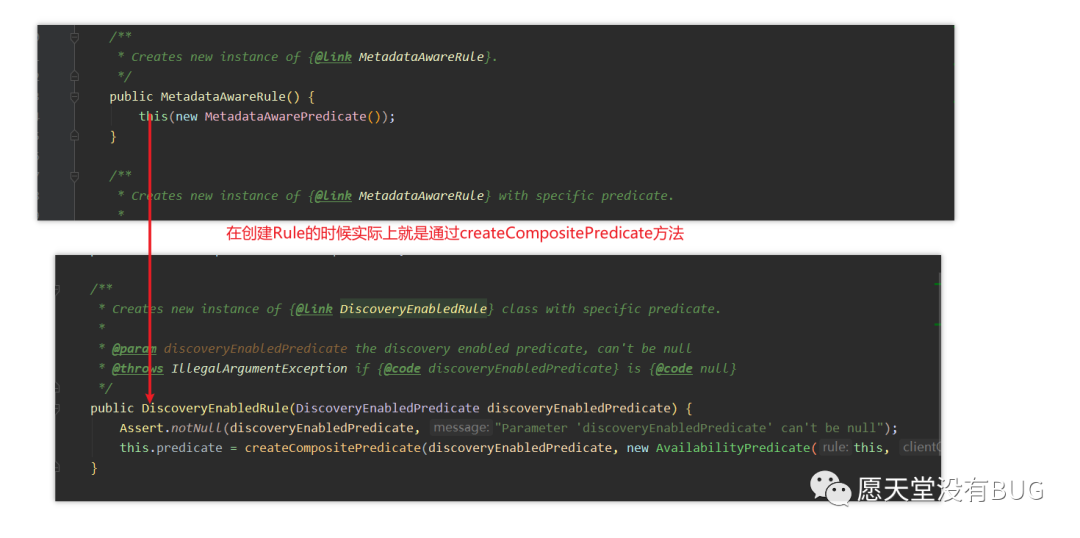
这个predicate 就是我们choose中getPredicate()方法获取的。所以在ribbon进行选择服务之前会通过
MetadataAwarePredicate进行过滤服务。获取到过滤器对象后,我们就会执行
chooseRoundRibbinAfterFiltering.
回到AbstractServerPredicate
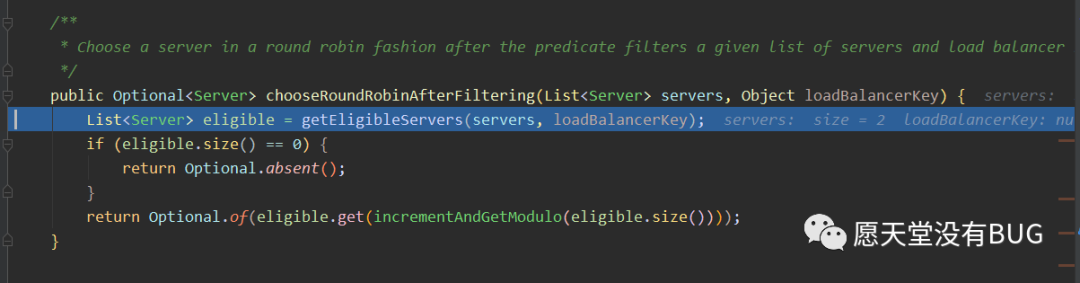
上文说到最终会通过Predicate去执行chooseRoundRobinAfterFiltering。还记得一开始predicate的结构图了吗。
MetadataAwarePredicate最终继承AbstractServerPredicate。而AbstractServerPredicate#chooseRoundRobinAfterFiltering是依赖getEligibleServers`来获取合适的服务列表的。在
AbstractServerPredicate实现了好多chooseXXX的方法。因为ribbon默认是轮询方式所以在BaseLoadBalance中是选择Round对应的方法。这些我们都可以自己去修改方式。这里不赘述Eligible译为合适的。getEligibleServers 翻译过来是获取合适的服务列表。

我们很明显的可以看到最终过滤的逻辑落在了apply方法上。
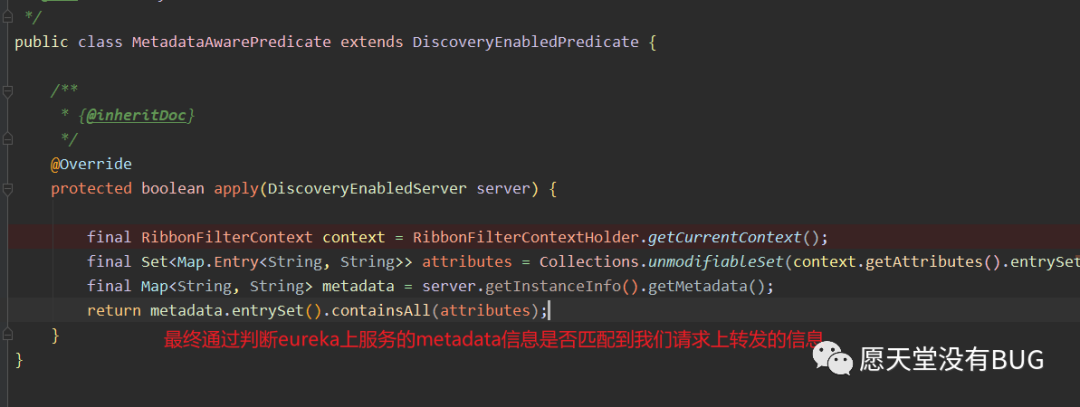
这就是我们上述通过
metadata-map:lancher配置我们的服务信息。下面是
AbstractServerPredicate精简后样子。主要就是getEligibleServers这个方法。
子类
在上面
AbstractServerPredicate结构图中我们可以看到除了DiscoveryEnabledPredicate这个子类外,还有四个子类。
| 子类 | 作用 |
|---|---|
| AvailabilityPredicate | 过滤不可用服务器 |
| CompositePredicate | 组合模式,保证服务数量一定数量。换句话说就是服务太少则会一个一个fallback知道服务数量达到要求 |
| ZoneAffinityPredicate | 选取指定zone区域内的Server |
| ZoneAvoidancePredicate | 避免使用符合条件的server . 和ZoneAffinityPredicate功能相反 |
文章分类
作者:zxhtom
链接:https://juejin.cn/post/6967947254162259975掘金