
Pod 垂直自动伸缩的使用

VPA(Pod 垂直自动伸缩)是 Kubernetes 中非常棒的一个功能,但是平时使用却并不多。这是因为在最初 Kubernetes 就是为水平扩展而构建的,垂直扩展一个 Pod 貌似不是一个好的方式,如果你想处理更多的负载,新增一个 Pod 副本可能更好。
但是这需要大量的资源优化,如果你没有适当地调整你的 Pod,通过提供适当的资源请求和限制配置,可能最终会很频繁地驱逐你的 Pod,或者浪费很多有用的资源。开发人员和系统管理员通过对资源的各种监控,以及通过基准测试或通过对资源利用率和流量的监控,来调整这些 Pod 的资源请求和限制的最佳值。
当流量不稳定、资源利用率不理想的时候,可能就相对复杂一些了,随着容器在微服务架构中的不断发展,系统管理员更注重稳定性,这样就导致最后使用的资源请求往往会远远超过实际的需求。
Kubernetes 提供了一个解决方案来解决这个问题,那就是 VPA(Vertical Pod Autoscaler),接下来我们来了解下 VPA 的作用,以及什么时候应该使用它。
VPA 如何工作
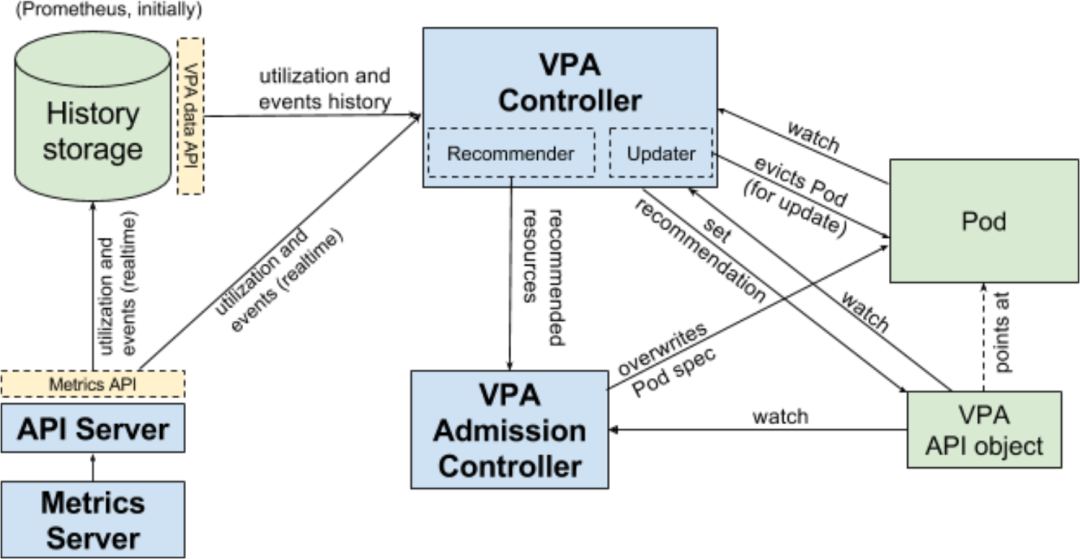
VPA 主要使用两个组件来实现自动伸缩,实现原理如下所示:
VPA 推荐器检查历史资源利用率和当前使用的模式,并推荐一个理想的资源请求值 如果你将更新模式定义为自动,VPA 自动调整器将驱逐正在运行的 Pod,并根据新的资源请求值创建一个新的 Pod VPA 自动调整器还将按照最初定义的限制值的比例来调整限制值。
实际上资源限制并没有什么意义,因为调整器会不断调整它,不过,如果你想要避免内存泄露,可以在 VPA 中设置最大的资源值。
VPA 资源清单
我们先来看一个 VPA 的资源清单文件长什么样子,如下所示:
# vpa-example.yaml
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx
updatePolicy:
updateMode: "On"
resourcePolicy:
containerPolicies:
- containerName: "nginx"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
- containerName: "istio-proxy"
mode: "Off"
和其他资源清单文件一样,VPA 一样有 apiVersion、kind、metadata、spec 这些属性,在 spec 规范部分,我们看到有一个 targetRef 的属性,它指定这个 VPA 对象所应用的资源对象,updatePolicy 定义了这个 VPA 是否会根据 updateMode 属性进行推荐或自动缩放。如果 updateMode 属性设置为 Auto,则 Pod 会自动垂直缩放,如果设置为 Off,则只是推荐理想的资源请求值。resourcePolicy 属性运行我们为每个容器指定容器策略,并给出 minAllowed 和 maxAllowed 资源值,这一点极为重要,可以避免自动的内存泄露。你还可以在一个 Pod 中的指定容器上关闭资源推荐和自动缩放,通常在 Istio sidecar 或 initContainer 中设置。
局限性
VPA 是有限制的。
不能和 HPA 一起使用
由于 VPA 会自动修改请求和限制值,所以不能将其与 HPA 一起使用,因为 HPA 依靠 CPU 和内存利用率来进行水平伸缩。有一个例外的情况是,当你 HPA 依靠自定义和外部指标来进行伸缩的时候。
需要至少两个健康的 Pod 才能工作
这种违背了它的初衷,也是没有被广泛使用的原因之一。由于 VPA 会破坏一个 Pod,并重新创建一个 Pod 来进行垂直自动伸缩,因此它需要至少两个监控的 Pod 副本来确保不会出现服务中断。这在单实例有状态应用上造成了不必要的复杂,你不得不考虑副本的设计。对于无状态应用来说,你又可以更好地使用 HPA 而不是 VPA 了,所以是不是很尴尬??
默认最小内存分配为250MiB
无论指定了什么配置,VPA 都会分配250MiB的最小内存,虽然这个默认值可以在全局层面进行修改,但对于消耗较少内存的应用程序来说,是比较浪费资源的。
不能用于单个 Pod
VPA 只适用于 Deployments、StatefulSets、DaemonSets、ReplicaSets 等控制器,你不能将它直接用于独立的 Pod,当然这个也还好,因为我们基本上也不使用独立的 Pod,而是会使用上层的控制器来管理 Pod。
在推荐模式下使用 VPA
目前 VPA 在生产中的最佳方式是在推荐模式下使用,这有助于我们了解最佳的资源请求值是多少,以及随着时间推移它们是如何变化的。
一旦配置了,我们就可以通过获取这些 metrics 指标,并将其发送到监控工具中去,比如 Prometheus 和 Grafana 或者 ELK 技术栈。然后可以利用这些数据来调整 Pods 的大小。
当然现在并不建议在生产中用自动模式来运行 VPA,因为该特性还比较新。我们可以在开发环境中进行实验,看看在负载不断增加的情况下是如何表现的,我们可以很容易地通过运行负载测试找到 Pod 可以消耗的最大资源量,这也是我们获取 Pod 资源限制值的一种很好的方式。
测试
首先请确保已经在 Kubernetes 集群中启用了 VPA。首先,创建一个NGINX Deployment,默认请求为250MiB 内存和100m 的 CPU。
$ cat < | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 100m
memory: 250Mi
EOF
现在我们将该应用通过 LoadBalancer 服务(如果不支持可以使用 NodePort)来对外进行暴露:
$ kubectl expose deployment nginx --type=LoadBalancer --port 80
暴露后云服务商会提供一个负载均衡器,然后可以获得这个负载均衡器的 IP。
$ kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.4.1.4 34.121.204.234 80:30750/TCP 46s
现在,让我们创建一个 VPA 资源对象,其中 updateMode 模式设置为 "Off",这并不会进行垂直扩展,只是提供一些建议。
# vpa-off.ayml
$ cat < | kubectl apply -f -
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: "nginx"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
EOF
接下来我们使用 hey 这个工具来进行一些负载测试,看看会得到什么样的结果。
$ hey -z 300s -c 1000 http://34.121.204.234
该命令使用1000个线程发出300秒的请求。我们可以运行下面的命令来获取 VPA 的相关信息:
$ kubectl describe vpa nginx-vpa
如果观察一段时间,我们会发现 VPA 会逐渐增加推荐的资源请求。
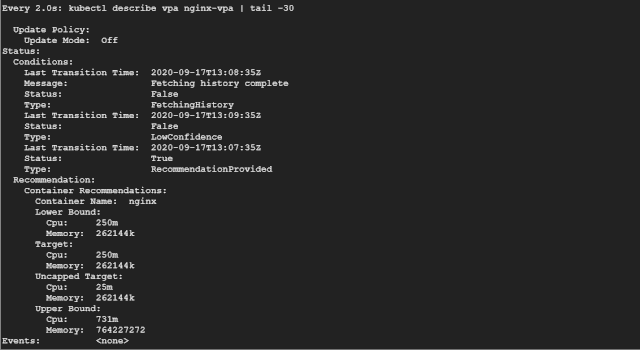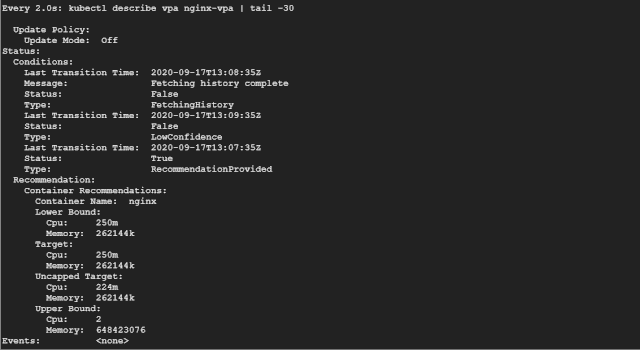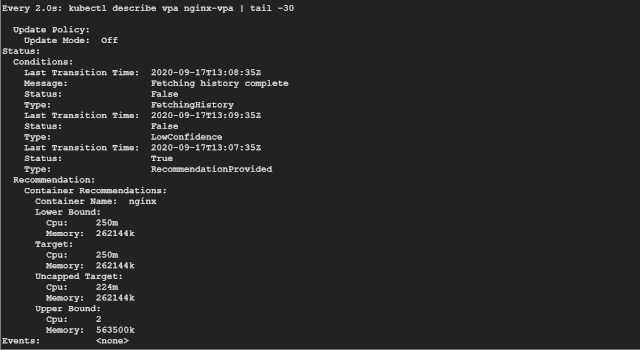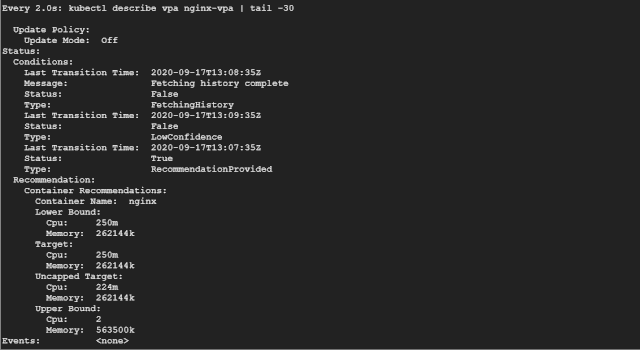
如果你看 Recommendation 推荐部分,可以看到如下所示的一些信息:
Target:这是 VPA 在驱逐当前 Pod 并创建另一个 Pod 时将使用的真实值。 Lower Bound:这反映了触发调整大小的下限,如果你的 Pod 利用率低于这些值,则 VPA 会将其逐出并缩小其规模。 Upper Bound:这表示下一次要触发调整大小的上限。如果你的 Pod 利用率高于这些值,则 VPA 会将其驱逐并扩大其规模。 Uncapped target:如果你没有为 VPA 提供最小或最大边界值,则表示目标利用率。
现在我们如果把 updateMode 设置成 Auto 会发生什么呢?执行下面的程序来测试下。
# vpa-auto.yaml
$ cat < | kubectl apply -f -
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: "nginx"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
EOF
然后让我们重新运行负载测试,在另一个终端中,我们将持续观察 Pod,看它们被驱逐和重新创建的过程。
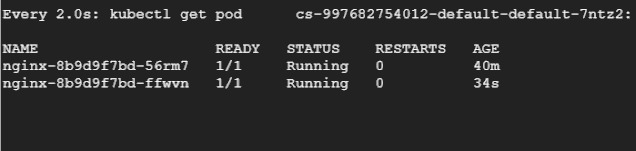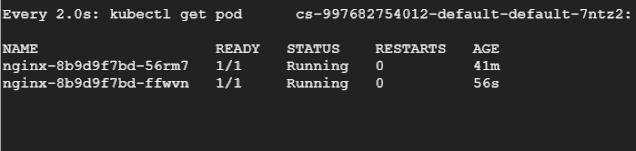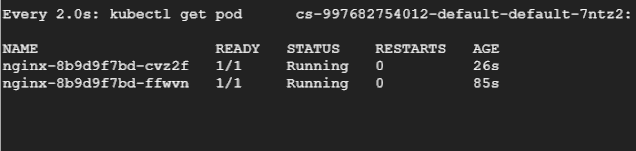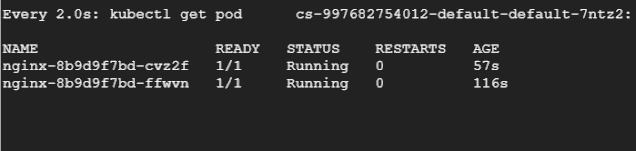
总结
VPA 是 Kubernetes 一个比较新的自动更新概念,比较适用于有状态应用,或者了解资源利用情况的应用。但是在目前的情况下,不建议在生产中使用它的自动更新模式,但它的推荐模式有利于我们观察资源的使用情况。
原文链接:https://medium.com/better-programming/understanding-vertical-pod-autoscaling-in-kubernetes-6d53e6d96ef3
K8S进阶训练营,点击下方图片了解详情
