
嵌入式C语言源代码优化方案(非编译器优化),收藏了!

转自:嵌入式云IOT技术圈
选择一种合适的数据结构很重要,如果在一堆随机存放的数中使用了大量的插入和删除指令,那使用链表要快得多。数组与指针语句具有十分密切的关系,一般来说,指针比较灵活简洁,而数组则比较直观,容易理解。对于大部分的编译器,使用指针比使用数组生成的代码更短,执行效率更高。
for(i=0;i<100;i++){
A=array[i++];
...
}指针运算:
p=array
while(!p){
a=*(p++);
...
}指针方法的优点是,array的地址每次装入地址p后,在每次循环中只需对p增量操作。在数组索引方法中,每次循环中都必须根据i值求数组下标的复杂运算。
2、使用尽量小的数据类型
能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。当然,在定义变量后不要超过变量的作用范围,如果超过变量的范围赋值,C编译器并不报错,但程序运行结果却错了,而且这样的错误很难发现。
3、减少运算的强度
(1)查表 (游戏程序员必修课)
旧代码:
long factorial(int i)
{
if (i == 0)
return 1;
else
return i * factorial(i - 1);
}新代码:
static long factorial_table[] = {1, 1, 2, 6, 24, 120, 720 /* etc */ };
long factorial(int i)
{
return factorial_table[i];
}如果表很大,不好写,就写一个init函数,在循环外临时生成表格。
(2)求余运算
a=a%8; 可以改为:a=a&7;
说明:位操作只需一个指令周期即可完成,而大部分的C编译器的“%”运算均是调用子程序来完成,代码长、执行速度慢。通常,只要求是求2n方的余数,均可使用位操作的方法来代替。
(3)平方运算
a=pow(a, 2.0); 可以改为:a=a*a;
a=pow(a,3.0); 更改为:a=a*a*a;
则效率的改善更明显。
(4)用移位实现乘除法运算
a=a*4;
b=b/4;
可以改为:
a=a<<2;
b=b>>2;
采用运算量更小的表达式替换原来的表达式,下面是一个经典例子:
旧代码:
x = w % 8;
y = pow(x, 2.0);
z = y * 33;
for (i = 0;i < MAX;i++)
{
h = 14 * i;
printf("%d", h);
}新代码:
x = w & 7; /* 位操作比求余运算快*/
y = x * x; /* 乘法比平方运算快*/
z = (y << 5) + y; /* 位移乘法比乘法快 */
for (i = h = 0; i < MAX; i++)
{
h += 14; /* 加法比乘法快 */
printf("%d",h);
}(5)避免不必要的整数除法
不好的代码:
int i, j, k, m;
m = i / j / k;
推荐的代码:
int i, j, k, m;
m = i / (j * k);
(6)使用增量和减量操作符
在使用到加一和减一操作时尽量使用增量和减量操作符,因为增量符语句比赋值语句更快,原因在于对大多数CPU来说,对内存字的增、减量操作不必明显地使用取内存和写内存的指令,比如下面这条语句:
x=x+1;
模仿大多数微机汇编语言为例,产生的代码类似于:
move A,x ;把x从内存取出存入累加器A
add A,1 ;累加器A加1
store x ;把新值存回x如果使用增量操作符,生成的代码如下:
incr x ; x加1
显然,不用取指令和存指令,增、减量操作执行的速度加快,同时长度也缩短了。
(7)使用复合赋值表达式
(8)提取公共的子表达式
float a, b, c, d, e, f;
...
e = b * c / d;
f = b / d * a;推荐的代码:
float a, b, c, d, e, f;
...
const float t(b / d);
e = c * t;
f = a * t;4、结构体成员的布局
很多编译器有“使结构体字,双字或四字对齐”的选项。但是,还是需要改善结构体成员的对齐,有些编译器可能分配给结构体成员空间的顺序与他们声明的不同。但是,有些编译器并不提供这些功能,或者效果不好。所以,要在付出最少代价的情况下实现最好的结构体和结构体成员对齐,建议采取下列方法:
(1)按数据类型的长度排序
(2)把结构体填充成最长类型长度的整倍数
struct
{
char a[5];
long k;
double x;
} baz;推荐的代码,新的顺序并手动填充了几个字节:
struct
{
double x;
long k;
char a[5];
char pad[7];
} baz;这个规则同样适用于类的成员的布局。
(3)按数据类型的长度排序本地变量
当编译器分配给本地变量空间时,它们的顺序和它们在源代码中声明的顺序一样,和上一条规则一样,应该把长的变量放在短的变量前面。如果第一个变量对齐了,其它变量就会连续的存放,而且不用填充字节自然就会对齐。有些编译器在分配变量时不会自动改变变量顺序,有些编译器不能产生4字节对齐的栈,所以4字节可能不对齐。下面这个例子演示了本地变量声明的重新排序:
不好的代码,普通顺序
short ga, gu, gi;
long foo, bar;
double x, y, z[3];
char a, b;
float baz;推荐的代码,改进的顺序
double z[3];
double x, y;
long foo, bar;
float baz;
short ga, gu, gi;(4)把频繁使用的指针型参数拷贝到本地变量
避免在函数中频繁使用指针型参数指向的值。因为编译器不知道指针之间是否存在冲突,所以指针型参数往往不能被编译器优化。这样数据不能被存放在寄存器中,而且明显地占用了内存带宽。注意,很多编译器有“假设不冲突”优化开关(在VC里必须手动添加编译器命令行/Oa或/Ow),这允许编译器假设两个不同的指针总是有不同的内容,这样就不用把指针型参数保存到本地变量。否则,请在函数一开始把指针指向的数据保存到本地变量。如果需要的话,在函数结束前拷贝回去。
不好的代码:
// 假设 q != r
void isqrt(unsigned long a, unsigned long* q, unsigned long* r)
{
*q = a;
if (a > 0)
{
while (*q > (*r = a / *q))
{
*q = (*q + *r) >> 1;
}
}
*r = a - *q * *q;
}// 假设 q != r
void isqrt(unsigned long a, unsigned long* q, unsigned long* r)
{
unsigned long qq, rr;
qq = a;
if (a > 0)
{
while (qq > (rr = a / qq))
{
qq = (qq + rr) >> 1;
}
}
rr = a - qq * qq;
*q = qq;
*r = rr;
}5、循环优化
(1)充分分解小的循环
不好的代码:
// 3D转化:把矢量 V 和 4x4 矩阵 M 相乘
for (i = 0;i < 4;i ++)
{
r[i] = 0;
for (j = 0;j < 4;j ++)
{
r[i] += M[j][i]*V[j];
}
}推荐的代码:
r[0] = M[0][0]*V[0] + M[1][0]*V[1] + M[2][0]*V[2] + M[3][0]*V[3];
r[1] = M[0][1]*V[0] + M[1][1]*V[1] + M[2][1]*V[2] + M[3][1]*V[3];
r[2] = M[0][2]*V[0] + M[1][2]*V[1] + M[2][2]*V[2] + M[3][2]*V[3];
r[3] = M[0][3]*V[0] + M[1][3]*V[1] + M[2][3]*V[2] + M[3][3]*v[3];(2)提取公共部分
对于一些不需要循环变量参加运算的任务可以把它们放到循环外面,这里的任务包括表达式、函数的调用、指针运算、数组访问等,应该将没有必要执行多次的操作全部集合在一起,放到一个init的初始化程序中进行。
(3)延时函数
void delay (void)
{
unsigned int i;
for (i=0;i<1000;i++) ;
}将其改为自减延时函数:
void delay (void)
{
unsigned int i;
for (i=1000;i>0;i--) ;
}(4)while循环和do…while循环
unsigned int i;
i=0;
while (i<1000)
{
i++;
//用户程序
}或
unsigned int i;
i=1000;
do
{
i--;
//用户程序
}
while (i>0);在这两种循环中,使用do…while循环编译后生成的代码的长度短于while循环。
(5)循环展开
这是经典的速度优化,但许多编译程序(如gcc -funroll-loops)能自动完成这个事,所以现在你自己来优化这个显得效果不明显。
for (i = 0; i < 100; i++)
{
do_stuff(i);
}新代码:
for (i = 0; i < 100; )
{
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
do_stuff(i); i++;
}(6)循环嵌套
把相关循环放到一个循环里,也会加快速度。
旧代码:
for (i = 0; i < MAX; i++) /* initialize 2d array to 0's */
for (j = 0; j < MAX; j++)
a[i][j] = 0.0;
for (i = 0; i < MAX; i++) /* put 1's along the diagonal */
a[i][i] = 1.0;新代码:
for (i = 0; i < MAX; i++) /* initialize 2d array to 0's */
{
for (j = 0; j < MAX; j++)
a[i][j] = 0.0;
a[i][i] = 1.0; /* put 1's along the diagonal */
}(7)Switch语句中根据发生频率来进行case排序
Switch 可能转化成多种不同算法的代码。其中最常见的是跳转表和比较链/树。当switch用比较链的方式转化时,编译器会产生if-else-if的嵌套代码,并按照顺序进行比较,匹配时就跳转到满足条件的语句执行。所以可以对case的值依照发生的可能性进行排序,把最有可能的放在第一位,这样可以提高性能。此外,在case中推荐使用小的连续的整数,因为在这种情况下,所有的编译器都可以把switch 转化成跳转表。
不好的代码:
int days_in_month, short_months, normal_months, long_months;
...
switch (days_in_month)
{
case 28:
case 29:
short_months ++;
break;
case 30:
normal_months ++;
break;
case 31:
long_months ++;
break;
default:
cout << "month has fewer than 28 or more than 31 days" << endl;
break;
}推荐的代码:
int days_in_month, short_months, normal_months, long_months;
...
switch (days_in_month)
{
case 31:
long_months ++;
break;
case 30:
normal_months ++;
break;
case 28:
case 29:
short_months ++;
break;
default:
cout << "month has fewer than 28 or more than 31 days" << endl;
break;
}(8)将大的switch语句转为嵌套switch语句
当switch语句中的case标号很多时,为了减少比较的次数,明智的做法是把大switch语句转为嵌套switch语句。把发生频率高的case 标号放在一个switch语句中,并且是嵌套switch语句的最外层,发生相对频率相对低的case标号放在另一个switch语句中。比如,下面的程序段把相对发生频率低的情况放在缺省的case标号内。
pMsg=ReceiveMessage();
switch (pMsg->type)
{
case FREQUENT_MSG1:
handleFrequentMsg();
break;
case FREQUENT_MSG2:
handleFrequentMsg2();
break;
。。。。。。
case FREQUENT_MSGn:
handleFrequentMsgn();
break;
default: //嵌套部分用来处理不经常发生的消息
switch (pMsg->type)
{
case INFREQUENT_MSG1:
handleInfrequentMsg1();
break;
case INFREQUENT_MSG2:
handleInfrequentMsg2();
break;
。。。。。。
case INFREQUENT_MSGm:
handleInfrequentMsgm();
break;
}
}enum MsgType{Msg1, Msg2, Msg3}
switch (ReceiveMessage()
{
case Msg1;
。。。。。。
case Msg2;
。。。。。
case Msg3;
。。。。。
}为了提高执行速度,用下面这段代码来替换这个上面的switch语句。
/*准备工作*/
int handleMsg1(void);
int handleMsg2(void);
int handleMsg3(void);
/*创建一个函数指针数组*/
int (*MsgFunction [])()={handleMsg1, handleMsg2, handleMsg3};
/*用下面这行更有效的代码来替换switch语句*/
status=MsgFunction[ReceiveMessage()]();(9)循环转置
有些机器对JNZ(为0转移)有特别的指令处理,速度非常快,如果你的循环对方向不敏感,可以由大向小循环。
旧代码:
for (i = 1; i <= MAX; i++)
{
。。。
}新代码:
i = MAX+1;
while (--i)
{
。。。
}不过千万注意,如果指针操作使用了i值,这种方法可能引起指针越界的严重错误(i = MAX+1;)。当然你可以通过对i做加减运算来纠正,但是这样就起不到加速的作用,除非类似于以下情况:
旧代码:
char a[MAX+5];
for (i = 1; i <= MAX; i++)
{
*(a+i+4)=0;
}i = MAX+1;
while (--i)
{
*(a+i+4)=0;
}(10)公用代码块
一些公用处理模块,为了满足各种不同的调用需要,往往在内部采用了大量的if-then-else结构,这样很不好,判断语句如果太复杂,会消耗大量的时间的,应该尽量减少公用代码块的使用。(任何情况下,空间优化和时间优化都是对立的–东楼)。当然,如果仅仅是一个(3==x)之类的简单判断,适当使用一下,也还是允许的。记住,优化永远是追求一种平衡,而不是走极端。
(11)提升循环的性能
要提升循环的性能,减少多余的常量计算非常有用(比如,不随循环变化的计算)。
for( i 。。。)
{
if( CONSTANT0 )
{
DoWork0( i );// 假设这里不改变CONSTANT0的值
}
else
{
DoWork1( i );// 假设这里不改变CONSTANT0的值
}
}if( CONSTANT0 )
{
for( i 。。。)
{
DoWork0( i );
}
}
else
{
for( i 。。。)
{
DoWork1( i );
}
}(12)选择好的无限循环
在编程中,我们常常需要用到无限循环,常用的两种方法是while (1)和for (;;)。这两种方法效果完全一样,但那一种更好呢?然我们看看它们编译后的代码:
编译前:while (1);
编译后:
mov eax,1
test eax,eax
je foo+23h
jmp foo+18h编译前:for (;;);
编译后:jmp foo+23h
显然,for (;;)指令少,不占用寄存器,而且没有判断、跳转,比while (1)好。
6、提高CPU的并行性
(1)使用并行代码
double a[100], sum;
int i;
sum = 0.0f;
for (i=0;i<100;i++)
sum += a[i];double a[100], sum1, sum2, sum3, sum4, sum;
int i;
sum1 = sum2 = sum3 = sum4 = 0.0;
for (i = 0;i < 100;i += 4)
{
sum1 += a[i];
sum2 += a[i+1];
sum3 += a[i+2];
sum4 += a[i+3];
}
sum = (sum4+sum3)+(sum1+sum2);要注意的是:使用4路分解是因为这样使用了4段流水线浮点加法,浮点加法的每一个段占用一个时钟周期,保证了最大的资源利用率。
(2)避免没有必要的读写依赖
float x[VECLEN], y[VECLEN], z[VECLEN];
。。。。。。
for (unsigned int k = 1;k < VECLEN;k ++)
{
x[k] = x[k-1] + y[k];
}
for (k = 1;k <VECLEN;k++)
{
x[k] = z[k] * (y[k] - x[k-1]);
}float x[VECLEN], y[VECLEN], z[VECLEN];
。。。。。。
float t(x[0]);
for (unsigned int k = 1;k < VECLEN;k ++)
{
t = t + y[k];
x[k] = t;
}
t = x[0];
for (k = 1;k <;VECLEN;k ++)
{
t = z[k] * (y[k] - t);
x[k] = t;
}7、循环不变计算
total = a->b->c[4]->aardvark + a->b->c[4]->baboon + a->b->c[4]->cheetah + a->b->c[4]->dog;新代码:
struct animals * temp = a->b->c[4];
total = temp->aardvark + temp->baboon + temp->cheetah + temp->dog;float a, b, c, d, f, g;
。。。
a = b / c * d;
f = b * g / c;这种写法当然要得,但是没有优化
float a, b, c, d, f, g;
。。。
a = b / c * d;
f = b / c * g;如果这么写的话,一个符合ANSI规范的新的编译器可以只计算b/c一次,然后将结果代入第二个式子,节约了一次除法运算。
8、函数优化
(1)Inline函数
(2)不定义不使用的返回值
(3)减少函数调用参数
(4)所有函数都应该有原型定义
一般来说,所有函数都应该有原型定义。原型定义可以传达给编译器更多的可能用于优化的信息。
(5)尽可能使用常量(const)
尽可能使用常量(const)。C++ 标准规定,如果一个const声明的对象的地址不被获取,允许编译器不对它分配储存空间。这样可以使代码更有效率,而且可以生成更好的代码。
(6)把本地函数声明为静态的(static)
如果一个函数只在实现它的文件中被使用,把它声明为静态的(static)以强制使用内部连接。否则,默认的情况下会把函数定义为外部连接。这样可能会影响某些编译器的优化——比如,自动内联。
9、采用递归
10、变量
在最内层循环避免使用全局变量和静态变量,除非你能确定它在循环周期中不会动态变化,大多数编译器优化变量都只有一个办法,就是将他们置成寄存器变量,而对于动态变量,它们干脆放弃对整个表达式的优化。尽量避免把一个变量地址传递给另一个函数,虽然这个还很常用。C语言的编译器们总是先假定每一个函数的变量都是内部变量,这是由它的机制决定的,在这种情况下,它们的优化完成得最好。但是,一旦一个变量有可能被别的函数改变,这帮兄弟就再也不敢把变量放到寄存器里了,严重影响速度。看例子:
a = b();
c(&d);
因为d的地址被c函数使用,有可能被改变,编译器不敢把它长时间的放在寄存器里,一旦运行到c(&d),编译器就把它放回内存,如果在循环里,会造成N次频繁的在内存和寄存器之间读写d的动作,众所周知,CPU在系统总线上的读写速度慢得很。比如你的赛杨300,CPU主频300,总线速度最多66M,为了一个总线读,CPU可能要等4-5个周期,得。。得。。得。。想起来都打颤。
11、使用嵌套的if结构
说明:上面的优化方案由王全明收集整理。
很多资料来源于网上,出处不祥,在此对所有作者一并致谢!
注意:优化是有侧重点的,优化是一门平衡的艺术,它往往要以牺牲程序的可读性或者增加代码长度为代价。
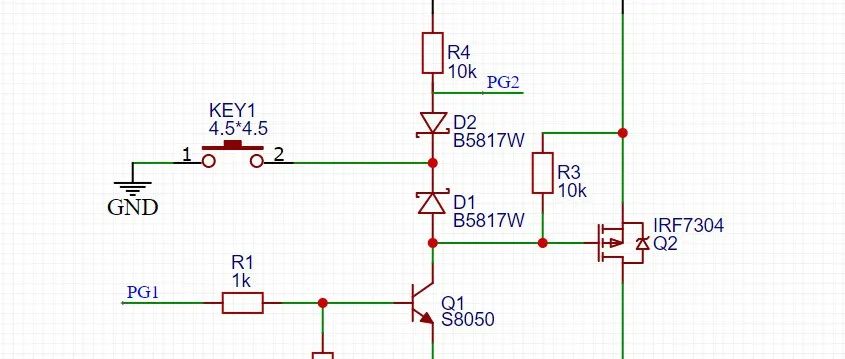
灰常实用的一键开关机电路,各位大佬进来mark一下?
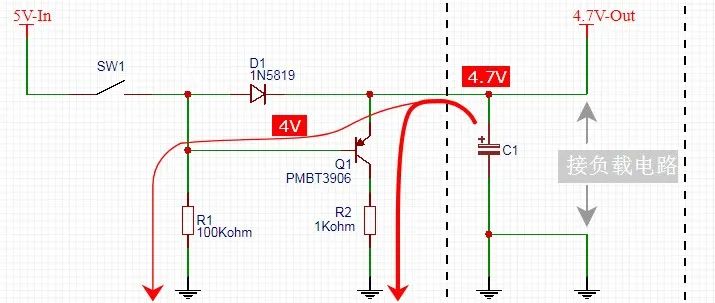
非常经典的余电快速泄放电路,你学会了吗?
某大公司非常经典的电压掉电监测电路,你学会了吗?
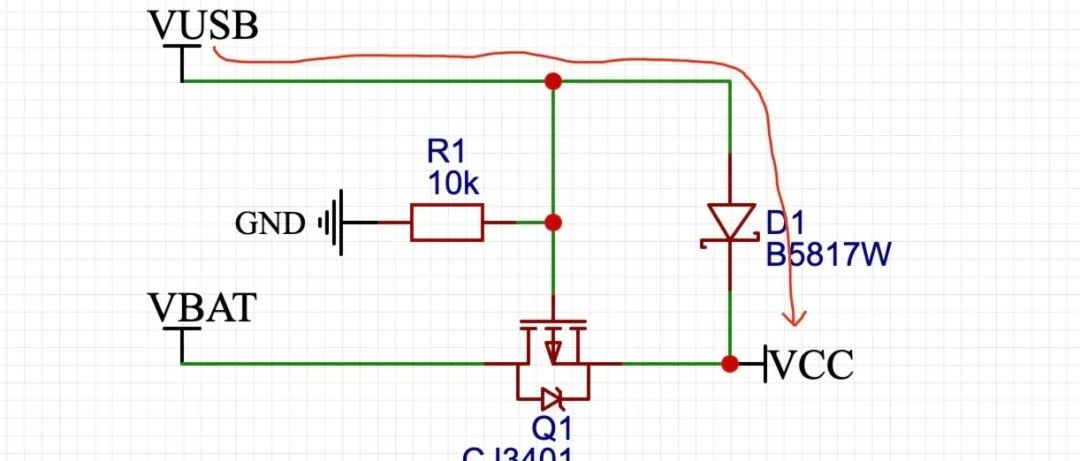
USB外接电源与锂电池自动切换电路设计,你GET到精髓了吗?
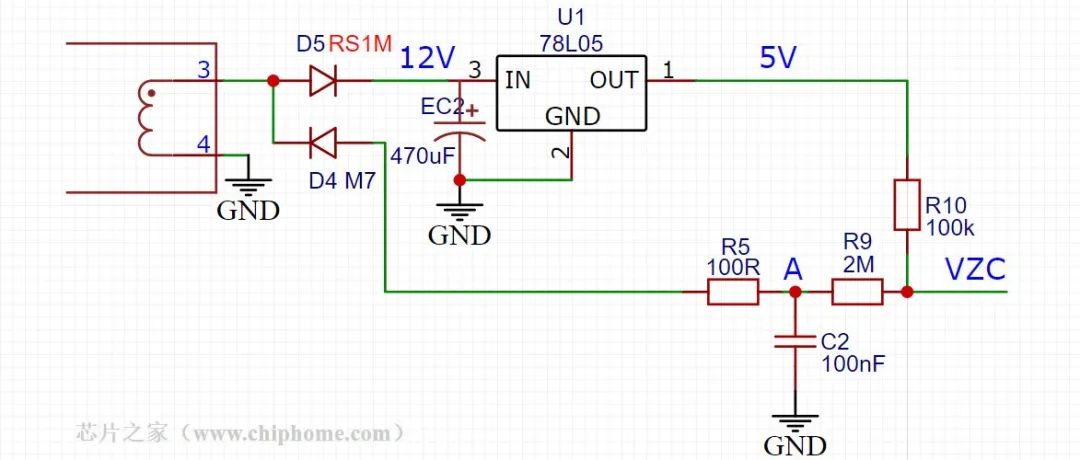
分享一个来自苏泊尔的超低成本隔离交流电压检测+掉电检测二合一电路
点击阅读👆