
5分钟!彻底搞懂缓冲池不为人知的秘密

Mysql 中数据是要落盘的,这点大家都知道。读写磁盘速度是很慢的,尤其和内存比起来更是没的说。但是,我们平时在执行 SQL 时,无论写操作还是读操作都能很快得到结果,并没有预想中的那么慢。
可能你会说我有索引啊,有索引当然快了。但是铁子,索引文件也是存储在磁盘上的,查找过程会产生磁盘 I/O。如果同时对某行数据进行多次操作,那岂不是要重复产生很多次磁盘 IO 吗?
可能你想到了,那我把数据存在内存里不就可以了吗?内存速度比磁盘快,这准没毛病。没错,那该怎么存呢? 这就是我们今天所要讲的主题——缓冲池(buffer pool)。
各位看官,请跟我来~
- 思维导图 -
上边我们提到过了,执行 SQL 对某一行进行操作时,总不能每次都直接进行磁盘操作吧。好歹有个缓冲地带,不然每次都深入老巢这谁受得了。
这不缓冲池就应运而生了,简单来说就是一块内存区域。它存在的原因之一是为了避免每次都去访问磁盘,把最常访问的数据放在缓存里,提高数据的访问速度。
了解了它的作用,接下来让我们先来看下缓冲池在整个 Mysql 架构里处于什么样的地方,有一个宏观的认识。

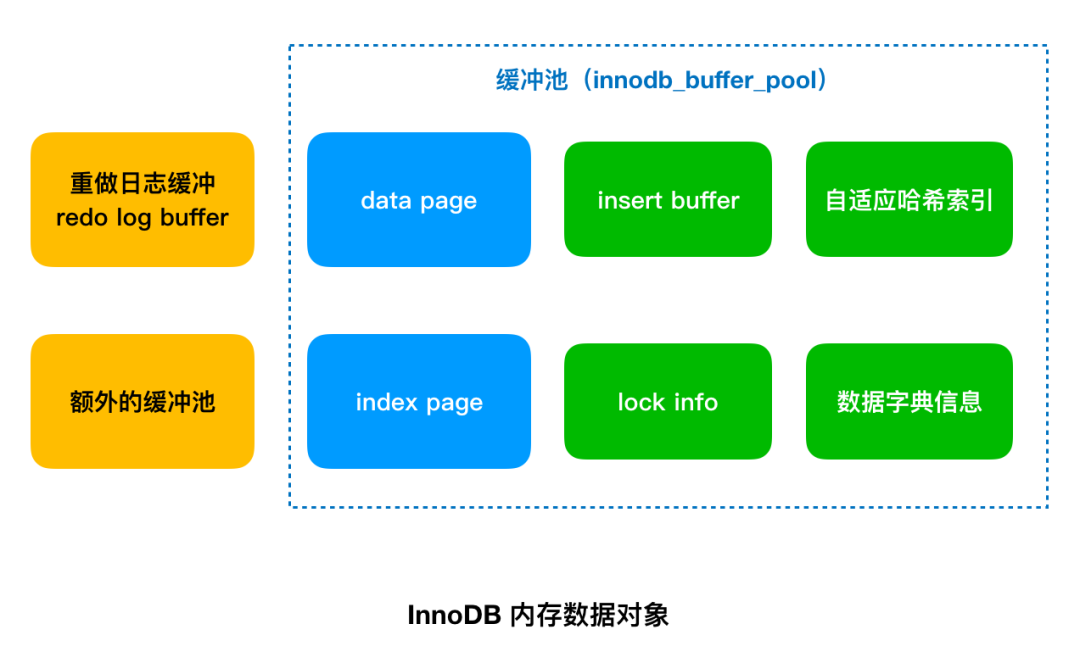
我们再来看看它的内部组成部分。在缓冲池中,除数据页和索引页外还有多种类型:
缓冲池你也了解了,可能此时你最关注的是它在 SQL 执行时起了一个什么样的作用。上篇文章中我们简单的提到过一条 SQL 语句的执行过程,但并未涉及到缓冲池相关的问题。这期我们仍是以一条 SQL 来作为切入点。
当一条 SQL 执行的时候,如果是读操作,要查找的数据所在的数据页在内存中时,则将结果返回。否则会把对应的数据页加载到内存中,然后再返回结果。
同样对于写操作来说。如果要修改的行所在的数据页在内存中,则修改后返回对应的结果(当然还有后续操作)。如果不在的话,则会从磁盘里将该行所对应的数据页读到内存中再进行修改。
好了,现在让我们回到开始时候的问题。为什么操作磁盘慢,但是 SQL 执行却不慢呢。到这里相信你也差不多知道了吧。
缓冲池的存在,很大程度减少了磁盘 I/O 带来的开销。要操作的数据行所在的数据页如果存在于缓存中的话,就不需要从磁盘中进行读取。这样在执行后就可以很快拿到结果。
我们可以看出来,只要不存在或减少磁盘 I/O,执行速度自然就会变快。那么对于加载数据页这种无法避免的磁盘 I/O 来说是否有更好的方式呢?既然避免不了,那减少磁盘 I/O 的次数总可以吧?
这就是我们要讲的 Mysql 中「预读」的新特性,它是 Innodb 通过在缓冲池中提前读取多个数据页来优化 I/O 的一种方式。因为磁盘读写的时候,是按照页的方式来读取的(你可以理解为固定大小的数据,例如一页数据为 16K),每次至少读入一页的数据,如果下次读取的数据就在页中,就不用再去磁盘上读取了,从而减少了磁盘 I/O。
可以在命令行通过如下命令查看对应的页大小:

你可能会有疑问,缓冲池这么洋气的东西,为什么不把所有的数据都放到缓冲池里呢?这样速度岂不是美滋滋,放到磁盘里慢的跟老牛拉车一样。
哎,哥,醒醒,抛开内存的易失性不谈,缓冲池也是有大小限制的。那你可能又有疑惑了,既然缓冲池有大小限制,那我每次都读入的数据页怎么来管理呢。别的数据页都占了地儿了,哪有我的位置?
这里我们来聊聊缓冲池的空间管理,其实对缓冲池进行管理的关键部分是如何安排进池的数据并且按照一定的策略淘汰池中的数据,保证池中的数据不“溢出”,同时还能保证常用数据留在池子中。
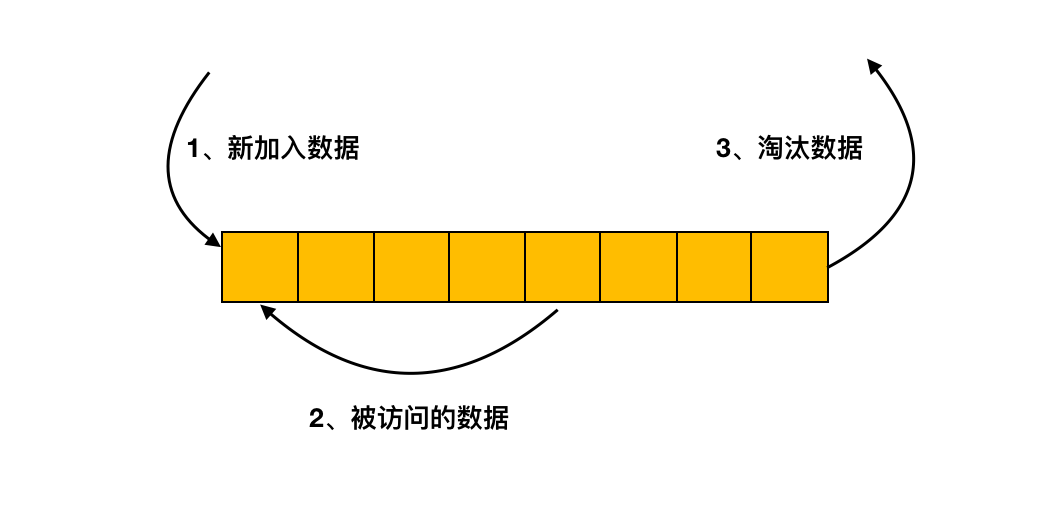
传统 LRU 淘汰法
缓冲池是基于传统的 LRU 方法来进行缓存页管理的,我们先来看下如果使用 LRU 是如何管理的。
LRU,全称是 Least Recently Used,中文名字叫作「最近最少使用」。从名字上就很容易理解了。
这里分两种情况:
(1)缓存页已在缓冲池中
这种情况下会将对应的缓存页放到 LRU 链表的头部,无需从磁盘再进行读取,也无需淘汰其它缓存页。
如下图所示,如果要访问的数据在 6 号页中,则将 6 号页放到链表头部即可,这种情况下没有缓存页被淘汰。
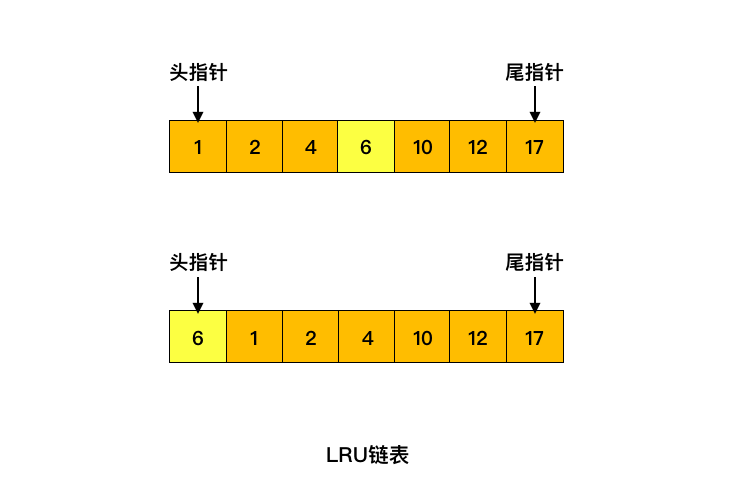
(2)缓存页不在缓冲池中
缓存页不在缓冲中,这时候就需要从磁盘中读入对应的数据页,将其放置在链表头部,同时淘汰掉末尾的缓存页
如下图所示,如果要访问的数据在 60 号页中,60 号页不在缓冲池中,此时加载进来放到链表的头部,同时淘汰掉末尾的 17 号缓存页。
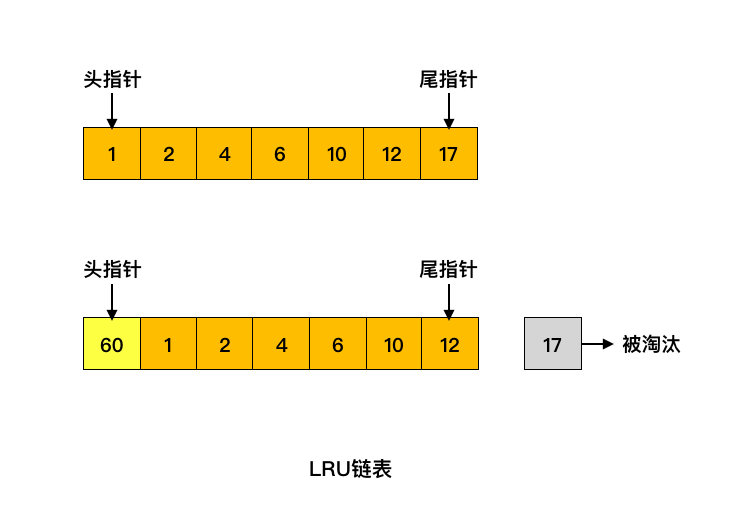
是不是看上去很简单,同时也能满足缓冲池淘汰缓存页的方法?但是我们来思考几个问题:
预读失效
上面我们提到了缓冲池的预读机制可能会预先加载相邻的数据页。假如加载了 20、21 相邻的两个数据页,如果只有页号为 20 的缓存页被访问了,而另一个缓存页却没有被访问。此时两个缓存页都在链表的头部,但是为了加载这两个缓存页却淘汰了末尾的缓存页,而被淘汰的缓存页却是经常被访问的。这种情况就是预读失效,被预先加载进缓冲池的页,并没有被访问到,这种情况是不是很不合理。
缓冲池污染
还有一种情况是当执行一条 SQL 语句时,如果扫描了大量数据或是进行了全表扫描,此时缓冲池中就会加载大量的数据页,从而将缓冲池中已存在的所有页替换出去,这种情况同样是不合理的。这就是缓冲池污染,并且还会导致 MySQL 性能急剧下降。
冷热数据分离
这样看来,传统的 LRU 方法并不能满足缓冲池的空间管理。因此,Msyql 基于 LRU 设计了冷热数据分离的处理方案。
也就是将 LRU 链表分为两部分,一部分为热数据区域,一部分为冷数据区域。
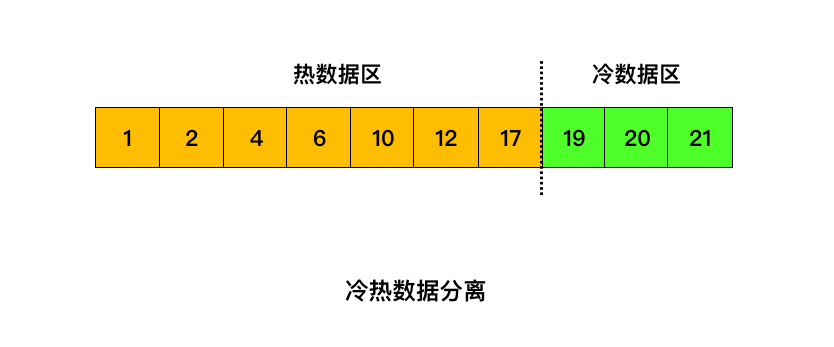
当数据页第一次被加载到缓冲池中的时候,先将其放到冷数据区域的链表头部,1s(由 innodb_old_blocks_time 参数控制) 后该缓存页被访问了再将其移至热数据区域的链表头部。
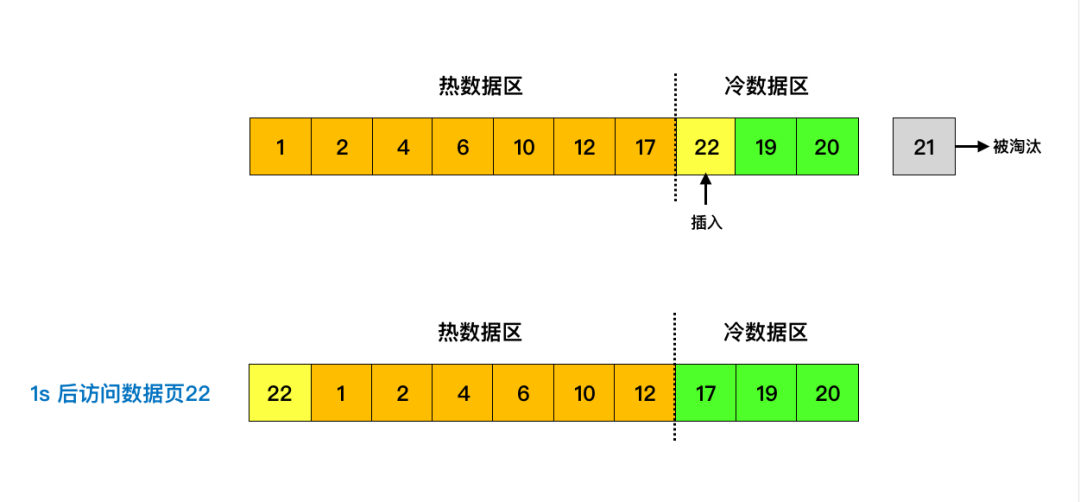
可能你会有疑惑了,为什么要等 1s 后才将其移至热数据区域呢?你想想,如果数据页刚被加载到冷数据区就被访问了,之后再也不访问它了呢?这不就造成热数据区的浪费了吗?要是 1s 后不访问了,说明之后可能也不会去频繁访问它,也就没有移至热缓冲区的必要了。当缓存页不够的时候,从冷数据区淘汰它们就行了。
另一种情况,当我的数据页已经在热缓冲区了,是不是缓存页只要被访问了就将其插到链表头部呢?不用我说你肯定也觉得不合理。热数据区域里的缓存页是会被经常访问的,如果每访问一个缓存页就插入一次链表头,那整个热缓冲区里就异常骚动了,你想想那个画面。
那咋整呢?Mysql 中优化为热数据区的后 3/4 部分被访问后才将其移动到链表头部去,对于前 1/4 部分的缓存页被访问了不会进行移动。
好了,到这里关于 buffer pool 的知识就讲完了。这期里我们讲了 buffer pool 能使 SQL 执行变快的原因,同时还讲了有关 buffer pool 空间的管理方式。欢迎在留言区里进行讨论。
缓冲池的应用
缓冲池很大程度减少了磁盘 I/O 带来的开销,通过将操作的数据行所在的数据页加载到缓冲池可以提高 SQL 的执行速度。
缓冲池的预读机制
为了减少磁盘 I/O,Innodb 通过在缓冲池中提前读取多个数据页来进行优化,这种方式叫作预读。
缓冲池的空间管理
传统的LRU方法对于缓冲池来说,会导致预读失效和缓冲池污染两种情况,因此这种传统的方式并不适用缓冲池的空间管理。
基于对 LRU 方法的优化,Msyql 设计了冷热数据分离的处理方案,将LRU链表分为热数据区和冷数据区两部分,这样就可以解决预读失效和缓冲池污染的情况。
题外话:推荐一个GitHub项目,这个 GitHub 整理了上百本常用技术PDF,绝大部分核心的技术书籍都可以在这里找到,GitHub地址:https://github.com/gsjqwyl/awesome-ebook(电脑打开体验更好),地址阅读原文直达。麻烦打个给个Star,持续更新中...
---END---
文末福利
