
一个目标检测的 Hello World项目(手把手带你搭建yolov3)

极市导读
本文主要介绍的是使用Pytorch搭建YOLOv3目标检测网络,并从头开始训练自定义数据集。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
YOLOv3的Github地址:
https://github.com/CVHuber/Detection-getting-started
模型测试(Linux环境下)
一、环境安装与模型下载
(1)首先将github代码克隆到本地
git clone https://github.com/CVHuber/Detection-getting-started
(2)进入到项目文件夹并安装项目运行环境
cd Detection-getting-started/ # 进入项目文件夹
pip install -r requirements.txt # 安装运行环境
(3)模型权重下载
cd weights/ # 进入weights文件夹
bash download_weights.sh # 下载模型权重
模型权重下载之后,在./weights文件夹下会有三个模型权重文件:

二、模型测试
在Detection-getting-started项目文件夹下,运行脚本:
python detect.py --image_folder data/samples/
模型测试结果将会存放在./output文件夹下:

训练Pascal Voc2007数据集
一、数据集下载
(1)目标检测常用的公共数据集有:Pascal Voc,MSCOCO,Google Open Image,ImageNet和DOTA数据集等。在本文中,我们将采用Pascal Voc2007数据集,因为其数据集比较小(训练和验证集总共才439M,测试集共431M),所以可以很快的跑通检测模型并验证模型!
Pascal Voc2007数据集下载链接:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/

(2)将训练集 / 测试集下载完成之后并解压:
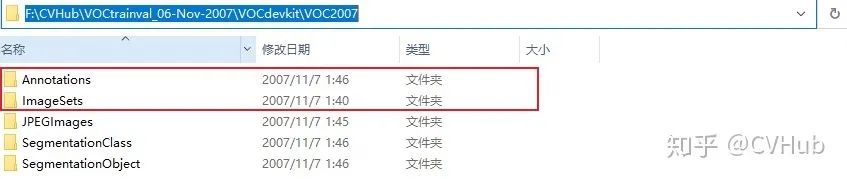
其中,JPEGImages是图片,Annotations是目标检测的Label,SegmentationClass和SegmentationObject分别是分类与分割的Label;所以我们只需要取JPEGImages和Annotations即可。
二、数据准备
(1)在./data文件夹下新建一个文件夹voc2007,并在voc2007文件夹下新建train和test文件夹分别存放训练集和测试集,将训练集 / 测试集分别存放到相应的文件夹:

(2)运行./utils文件夹下的gen_classes.py脚本,并可以统计数据集中存在的待检测目标,并将目标名称写入到classes.names,生成的classes.names文件被保存与./data/voc2007/train文件夹下:
cd utils/ # 进入到utils文件夹
python gen_classes.py # 运行脚本
(3)运行./utils文件夹下的voc.py脚本
python voc.py
./data文件夹下则会产生一个新的名为custom文件夹,custom文件夹包含了YOLOv3模型所需要的数据:

注释:其中images是训练集和验证集的图片(从JPEGImages复制而来);annotation是训练集和验证集的原始标注文件(从Annotations复制而来);train.txt存放训练图片的绝对路径;valid.txt存放验证图片的绝对路径;labels文件夹下存放了每张图片的检测框信息,检测框信息由
(classes_id, x_center_norm, y_center_norm, width_norm, height_norm)组成:
x_center_norm = [(xmin + xmax) / 2.0] / img_width y_center_norm = [(ymin + ymax) / 2.0] / img_height width_norm = [(xmax - xmin) / 2.0] / img_width height_norm = [(ymax - ymin) / 2.0] / img_height
三、配置文件
(1)在./config文件夹下运行如下脚本:
bash create_custom_model.sh 20
其中20是数据集中存在的待检测目标数目(因为Pascal Voc2007数据集共20个类别,所以填20),运行上脚本之后之后,在./config文件夹下会生成模型配置文件yolov3-custom.cfg:

注释:yolov3-custom.cfg模型配置文件里存放了模型的超参数,可以自己调节这些超参数,比如图片的输入尺寸,初始学习率,ignore_thresh阈值,还有一些卷积参数等等。
(2)修改./config文件夹下的custom.data,修改后的数据如下:

四、模型训练
在项目文件夹下运行如下脚本:
python train.py --data_config config/custom.data --model_def config/yolov3-custom.cfg --device_id 0
如果要加载预训练模型进行训练,则添加--pretrained_weights weights/darknet53.conv.74即可
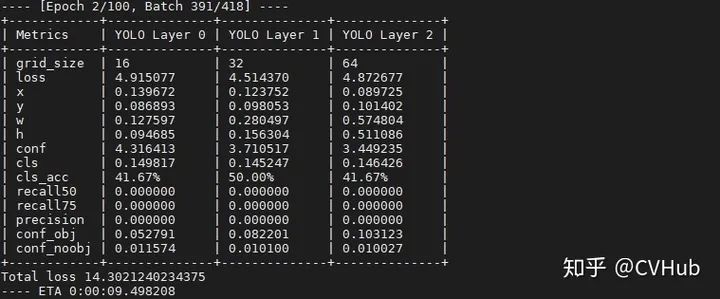
模型训练情况:
五、模型评估
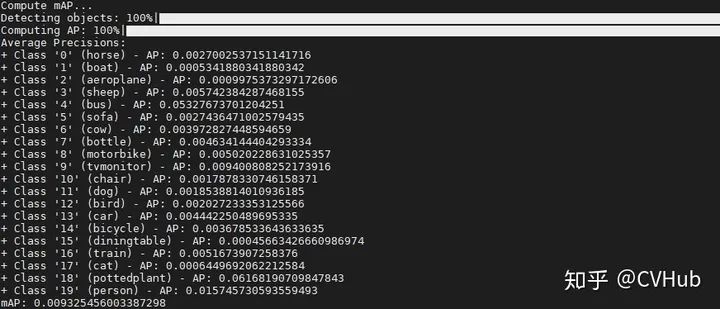
在项目文件夹下运行如下脚本对刚刚训练得到的模型进行性能评估:
python test.py --weights_path /checkpoints/yolov3_ckpt_10.pth --model_def config/yolov3-custom.cfg --data_config config/custom.data --class_path data/custom/classes.names
如若运行成功,会出现如下信息:
六、模型预测
如果要使用训练好的模型进行图片预测,并将预测结果保存,则运行如下脚本,预测结果保存在./output文件夹下:
python detect.py --image_folder data/voc2007/test/JPEGImages --model_def config/yolov3-custom.cfg --weights_path /checkpoints/yolov3_ckpt_10.pth --class_path data/classes.names

训练自己的数据集
一、自定义数据集
比如公司要你实现一个检测算法:在某特定业务场景下,检测出印刷电路板上的缺陷具体位置并将缺陷进行归类。
比如,下面这几块电路板分别存在short,missing_hole和mouse_bit这三种类别的缺陷,图片引自于[1]

当采集了大量的数据之后,需要对数据集进行label制作,常用的目标检测label制作工具有:
(1)LabelImg:https://github.com/tzutalin/labelImg(最常用)
(2)BBox-Label-Tool:https://github.com/puzzledqs/BBox-Label-Tool
(3)Labelme:https://github.com/wkentaro/labelme
(4)CasiaLabeler:https://github.com/msnh2012/CasiaLabeler
我们一般选择LabelImg进行目标检测框的标注,通过LabelImg,我们可以制作Pascal Voc格式的标注文件。
二、模型训练
接下来,将数据集图片存入./data/voc2007/train/JPEGImages文件夹下,将制作好的Label存入./data/voc2007/train/Annotations文件夹下,之后的训练过程就和训练Pascal Voc2007数据集的一样了!
注意:如果使用另一个标注工具进行Label制作,则只需要自己写好脚本将Label转换为Pascal Voc格式的标注文件即可,后续训练流程同上!
模型改进思路
如果任务比较简单,可以将特征提取网络Darknet53替换成更加轻量级的特征提取网络 首先观察数据集,如果待检测目标物体尺度变化较大,则三个预测分支是比较合适的,甚至还可以多加一个检测分支,形成四个检测分支去检测目标;如果待检测目标尺度单一,则可以去掉另外两个检测分支,只考虑一个检测分支,这对精度影响是很小的 对于待检测目标尺度变化较大问题,可以考虑加入多尺度上下文信息提取模块ASPP或者PSP,并结合通道注意力SE block,有时候会有奇效;同时也可以将FPN架构加入到特征提取器的头部用来解决多尺度目标问题 可以将边框回归损失MSE替换为IOU-->GIOU-->DIOU-->CIOU(这几种边框回归损失函数需要好好掌握理解,面试常问) 将通道/空间注意力应用到网络中不同位置,尝试效果
Reference:
[1] [https://github.com/Ixiaohuihuihui/Tiny-Defect-Detection-for-PCB]
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
