
Redis缓存问题—缓存和数据库数据不一致
在实际应用 Redis 缓存时,我们经常会遇到一些异常问题,概括来说有 4 个方面:缓存中的数据和数据库中的不一致、缓存雪崩、缓存击穿和缓存穿透。在这篇文章中,我们首先来讲一下数据不一致问题。
一、数据不一致会带来什么问题?
在实际开发中,我们会在数据库前面加上一层缓存,利用内存读写效率高于磁盘的特性,来提高程序性能。但是这样的话,就必然面对数据库和缓存中数据不一致的问题。
那么数据不一致会产生什么问题呢?
举个例子,电商系统更新某商品的库存。当前商品库存是100,此时卖出一件,需要将库存更新为99。先将数据库更新成99,然后更新缓存,但是缓存更新失败了,那么此时数据库存的是99,缓存存的是100,假设现在有一个顾客要买100件该商品,查询缓存发现库存有100件,但是实际商品库存只有99件,这就会导致发不出货的情况,会给公司造成很不好的影响。
二、数据不一致的情况?
缓存和数据库数据一致包含以下两种情况:
缓存中有数据,那么,缓存的数据值需要和数据库中的值相同; 缓存中本身没有数据,那么,数据库中的值必须是最新值。
不符合这两种情况的,就属于缓存和数据库的数据不一致问题了。
三、Redis做缓存的两种模式?
按照 Redis 缓存是否接受写请求,有两种使用模式:只读缓存和读写缓存。
1、只读缓存
当 Redis 用作只读缓存时,应用要读取数据的话,首先会去 Redis 中查询数据,如果 Redis 中不存在,则去查询数据库。
所有的写请求,会直接发往数据库,在数据库中执行增删改。
对于增加的数据,直接写入数据库。
举个例子来说明:
电商系统,增加一条库存数据,stock:100,操作步骤如下图所示: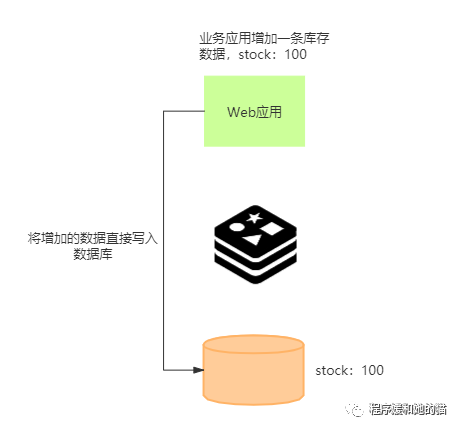
对于删改的数据,如果数据在 Redis 中缓存了,应用会先修改数据库里的数据,并把 Redis 中的数据删除。当应用再次读取这些数据时,会发生缓存缺失,此时应用从数据库中读取数据,并写入 Redis,以便后续请求从缓存中直接读取,起到加速访问的效果。
举个例子来说明:
电商更新库存场景,数据库中一条数据,列名:stock,列值:100。Redis中的数据,key:stock,value:100。现在业务应用要将库存修改为99,操作步骤如下图所示: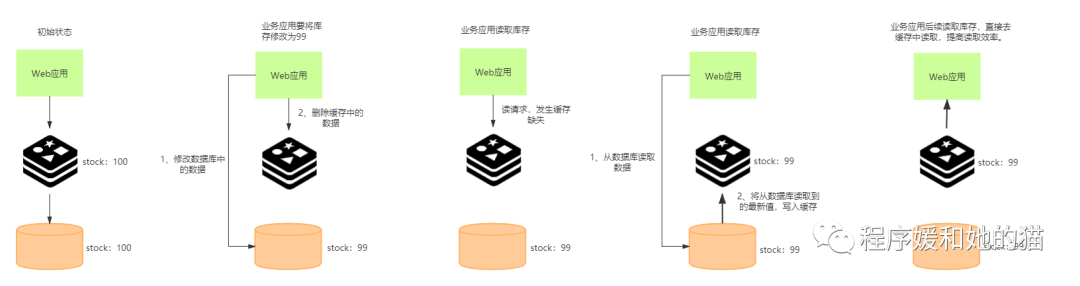
只读缓存直接在数据库中更新数据的好处是,所有最新的数据都在数据库中,而数据库是提供数据可靠性保障的,这些数据不会有丢失的风险。当我们需要缓存图片、短视频这些用户只读的数据时,就可以使用只读缓存这个类型了。
2、读写缓存
对于读写缓存来说,除了读请求会发送到缓存进行处理(直接在缓存中查询数据是否存在),所有的写请求也会发送到缓存(在缓存中直接对数据进行增删改操作)。
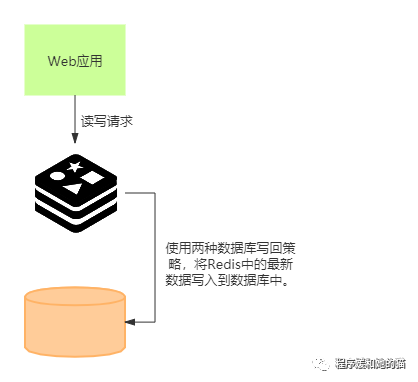
和只读缓存不一样的是,在使用读写缓存时,最新的数据是在 Redis 中,而 Redis 是内存数据库,一旦出现掉电或宕机,内存中的数据就会丢失。这也就是说,应用的最新数据可能会丢失,给应用业务带来风险。
因为读写缓存可能产生数据丢失的可能,所以根据业务应用对数据可靠性和缓存性能的不同要求,读写缓存会有同步直写和异步写回两种数据库写回策略,及时将最新数据写入到数据库。其中,同步直写策略优先保证数据可靠性,而异步写回策略优先提供快速响应。
3、只读缓存和读写缓存如何选择?
只读缓存:读请求,优先Redis,写请求优先数据库,数据可靠性有保证。
读写缓存:无论是读请求还是写请求,都是优先在Redis中操作,数据可靠性无保证。
关于是选择只读缓存,还是读写缓存,主要看我们对写请求是否有加速的需求。
如果需要对写请求进行加速,我们选择读写缓存; 如果写请求很少,或者是只需要提升读请求的响应速度的话,我们选择只读缓存。
举个例子:
在商品大促的场景中,商品的库存信息会一直被修改。如果每次修改都需到数据库中处理,就会拖慢整个应用,此时,我们通常会选择读写缓存的模式。
在短视频 App 的场景中,虽然视频的属性有很多,但是,一般确定后,修改并不频繁,此时,在数据库中进行修改对缓存影响不大,而且短视频场景,浏览量会非常非常大,所以只读缓存模式是一个合适的选择。
四、数据库写回策略?
读写缓存有两种数据库写回策略,分别是同步直写和异步写回,下面我们就详细介绍以下这两种策略。
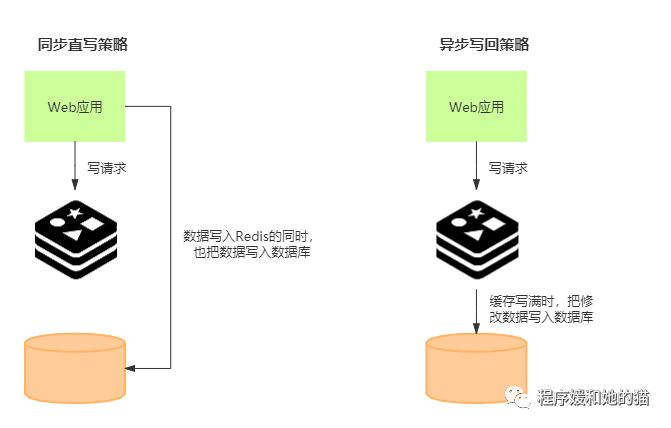
同步直写
写请求发给缓存的同时,也会发给后端数据库进行处理,等到缓存和数据库都写完数据,才给客户端返回。
优点:写完缓存马上将最新的数据写入数据库,这样即使缓存宕机或发生故障,最新的数据仍然保存在数据库中,这就提供了数据可靠性保证。
缺点:因为缓存中处理写请求的速度是很快的,而数据库处理写请求的速度很慢。即使缓存很快地处理了写请求,也需要等待数据库处理完所有的写请求,才能给应用返回结果,这就增加了缓存的响应延迟。
异步写回
所有写请求都先在缓存中处理,等到这些增改的数据要被从缓存中淘汰出来时,再将它们写入数据库。
优点:不需要等待写入数据库的时间,提高写入速度。
缺点:如果发生了掉电,而数据还没有来得及被写回数据库,就会有丢失数据的风险。
五、什么时候会出现数据不一致?
1、读写缓存
同步直写策略:写缓存时,也同步写数据库,缓存和数据库中的数据一致。
异步写回策略:写缓存时不同步写数据库,等到数据从缓存中淘汰时,再写回数据库。使用这种策略时,如果数据还没有写回数据库,缓存就发生了故障,那么,此时,数据库就没有最新的数据了。
所以,对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略。不过,需要注意的是,如果采用同步直写策略,就需要同时更新缓存和数据库,所以,我们要在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,我们就无法实现同步直写。
2、只读缓存
(1)、新增数据
只读缓存,对于增加的数据,直接写入数据库,不用对缓存做任何操作,此时,缓存中本身就没有新增数据,而数据库中是最新值,符合我们数据一致性的第 2 种情况,所以,此时,缓存和数据库的数据是一致的。
(2)、删改数据
只读缓存,对于删改的数据,应用既要更新数据库,也要在缓存中删除数据,这两个操作如果无法保证原子性,就会出现数据不一致问题。
第一种情况:应用先删除缓存,再更新数据库。
如果缓存删除成功,但是数据库更新失败,那么,缓存中没有数据,数据库中的值是旧值,这肯定是不一致的(和缓存一致性第 2 种情况正好相反)。
这个时候,如果有其他的请求来访问数据,缓存中没有数据,此时应用就会去访问数据库,但是数据库中的值为旧值,应用就访问到旧值了。
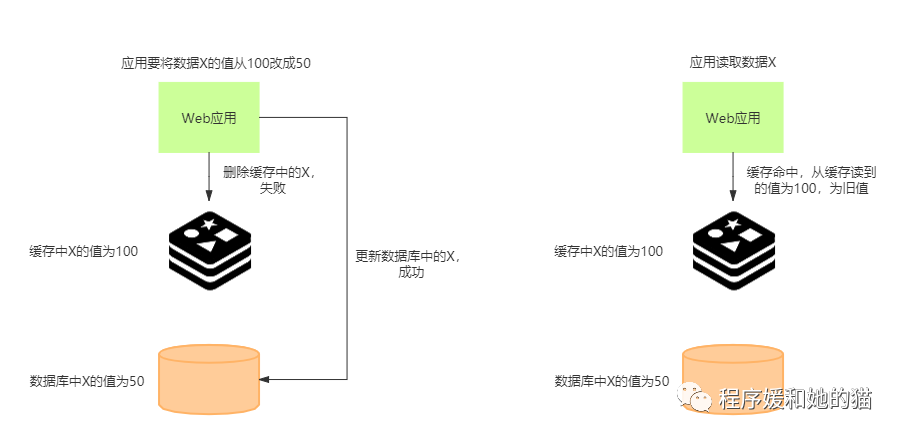
举例说明:
应用要把数据 X 的值从 100 更新为 50,先在 Redis 缓存中删除了 X 的缓存值,但是下一步更新数据库却失败了,这个时候,数据库中 X 的值为旧值 100,Redis 中的 X 的缓存值为空。如果此时有其他的请求访问 X,会发现 Redis 中缓存缺失,紧接着,请求就会访问数据库,读到的是旧值 100。

第二种情况:应用先更新数据库,再删除缓存。
如果应用先完成了数据库的更新,但是在删除缓存时失败了,那么数据库中的值是新值,而缓存中的是旧值,这肯定是不一致的(和缓存一致性第 1 种情况正好相反)。
这个时候,如果有其他的请求来访问数据,会先在缓存中查询,此时就会读到旧值了。
举例说明:
应用要把数据 X 的值从 100 更新为 50,先成功更新了数据库,但是下一步删除缓存却失败了,这个时候,数据库中 X 的值为新值 50,Redis 中的 X 的缓存值为 旧值 100。如果此时有其他的请求访问 X,会先在 Redis 中查询,读到的是旧值 100。
六、如何解决数据不一致问题?
1、重试机制
(1)、什么情况下使用重试机制?
删除缓存或更新数据库失败而导致数据不一致,可以使用重试机制确保删除缓存或更新数据库操作成功。
(2)、如何做重试?
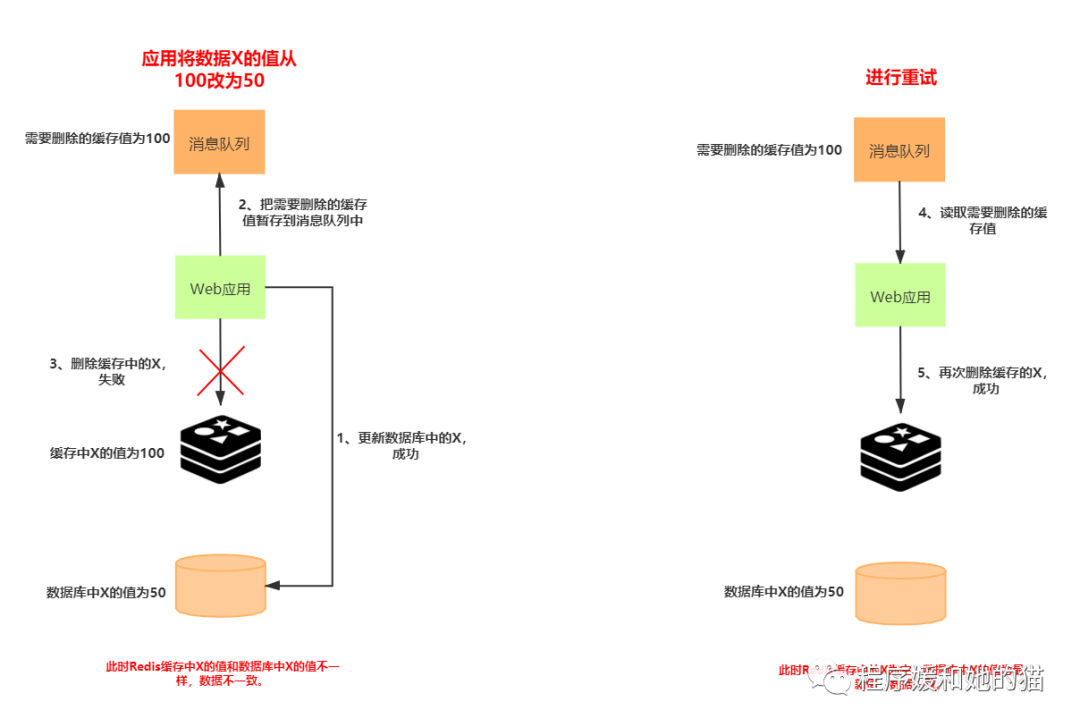
首先把要删除的缓存值或者要更新的数据库值暂存到消息队列中(例如使用 RocketMQ、Kafka 等消息队列),当应用删除缓存值或者是更新数据库值失败时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
如果删除或更新成功,我们就要把这些值从消息队列中去除,以免重复操作,否则的话,我们还需要再次进行重试,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
下图显示了先更新数据库,再删除缓存值时,如果缓存删除失败,再次重试后删除成功的情况。
2、延迟双删
(1)、延迟双删和重试机制?
在单线程环境,更新数据库和删除缓存值的过程中,其中一个操作失败,使用重试机制可以解决数据不一致的问题。
但是在多线程环境,即使这两个操作第一次执行时都成功了,当有大量并发请求时,应用还是有可能读到不一致的数据,此时我们需要使用延迟双删来解决这个问题。
(2)、情况一:先删除缓存,再更新数据库。
问题描述:如下表所示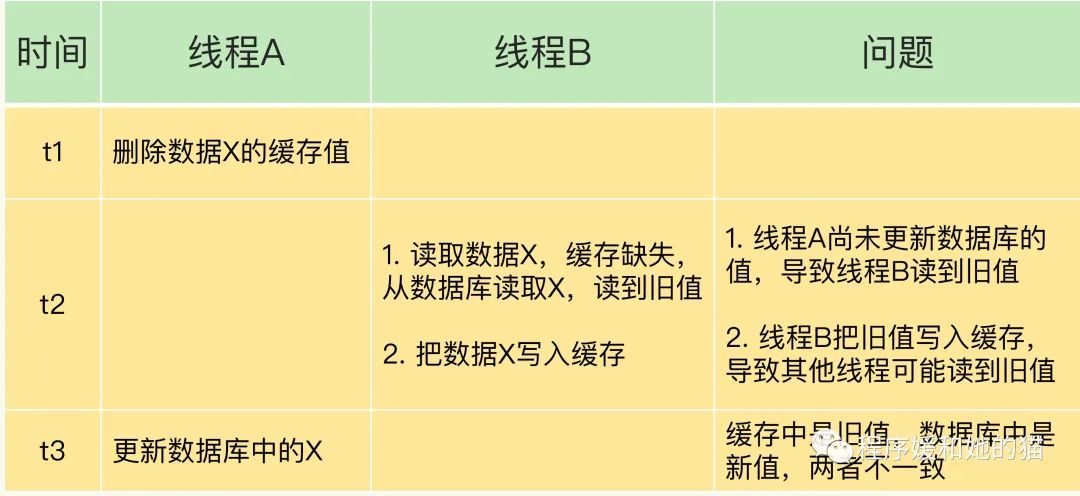
假设线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,那么这个时候,线程 B 会发现缓存缺失,就只能去数据库读取。这会带来两个问题:
线程 B 读取到了旧值; 线程 B 是在缓存缺失的情况下读取的数据库,所以,它还会把旧值写入缓存,这可能会导致其他线程从缓存中读到旧值。
等到线程 B 从数据库读取完数据、更新了缓存后,线程 A 才开始更新数据库,此时,缓存中的数据是旧值,而数据库中的是最新值,两者就不一致了。
解决方案:延迟双删
在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作,这样就保证数据一致性:数据库中是最新值,Redis缓存中没有数据。
延迟双删步骤如下,因为在第一次删除缓存值后,延迟一段时间再次进行删除,所以叫做“延迟双删”:
1)、先删除缓存
2)、再写数据库
3)、休眠一段时间
4)、再次删除缓存
为什么需要让线程 A 需要 slepp 一段时间呢?
这么做的目的是,确保线程B的读请求完全结束,这样线程A的写请求才可以删除线程B读请求造成的缓存脏数据。
所以,线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间,一般是在读数据业务逻辑的耗时基础上,加几百毫秒即可。
延迟双删伪代码如下:
redis.delKey(X);
db.update(X);
Thread.sleep(N);
redis.delKey(X);
(3)、情况二:先更新数据库值,再删除缓存值。
问题描述:如下表所示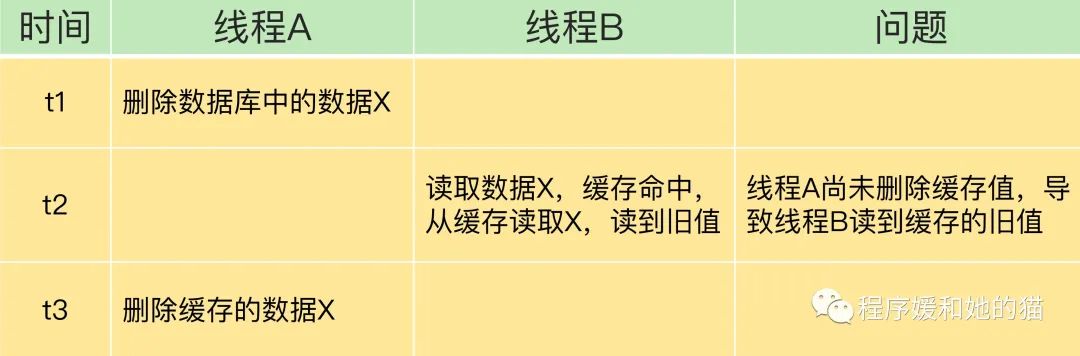
如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。
不过,在这种情况下,如果其他线程并发读缓存的请求不多,那么,就不会有很多请求读取到旧值。而且,线程 A 一般也会很快删除缓存值,这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。