方向对了?MIT新研究:GPT-3和人类大脑处理语言的方式惊人相似

来源:机器之心 本文约2700字,建议阅读6分钟
人和机器都是这样组织语言的。
计算机擅长理解结构化数据,让计算机去理解主要以文化习惯沉淀下来的人类语言是一件困难的事。不过在 AI 的重要方向,自然语言处理(NLP)领域中,人们经过多年的实践找到了一些方法。
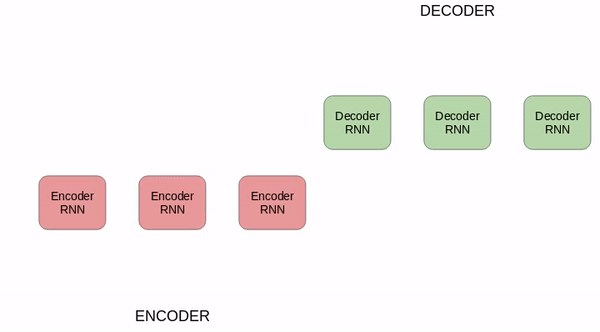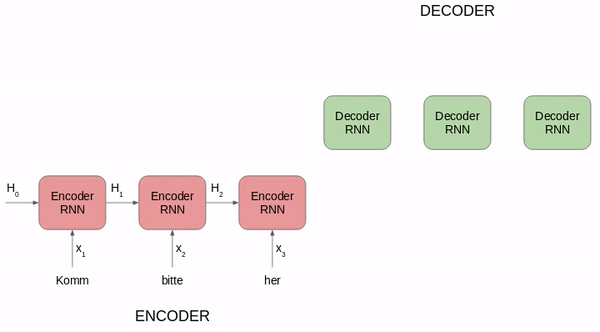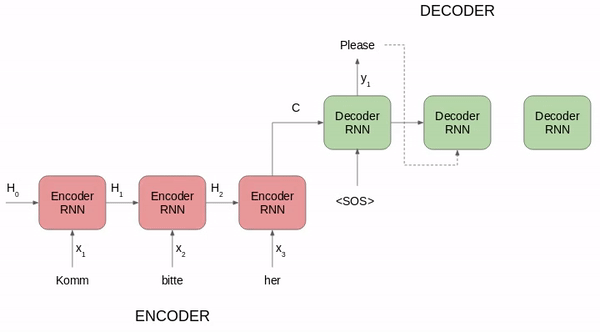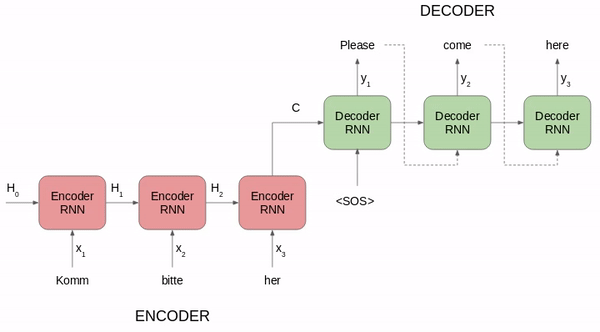
在目前流行的 NLP 方法中,其中一种语言模型就是根据上下文去预测下一个词是什么。通过这种方法,语言模型能够从无限制的大规模单语语料中学习到丰富的语义知识。而预训练的思想让模型的参数不再是随机初始化,而是先有一个任务进行训练得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
论文:
https://www.pnas.org/content/118/45/e2105646118
论文预印版(Biorxiv):
https://www.biorxiv.org/content/biorxiv/early/2020/10/09/2020.06.26.174482.full.pdf
GitHub:
https://github.com/mschrimpf/neural-nlp

论文第一作者,MIT 在读博士 Martin Schrimpf。
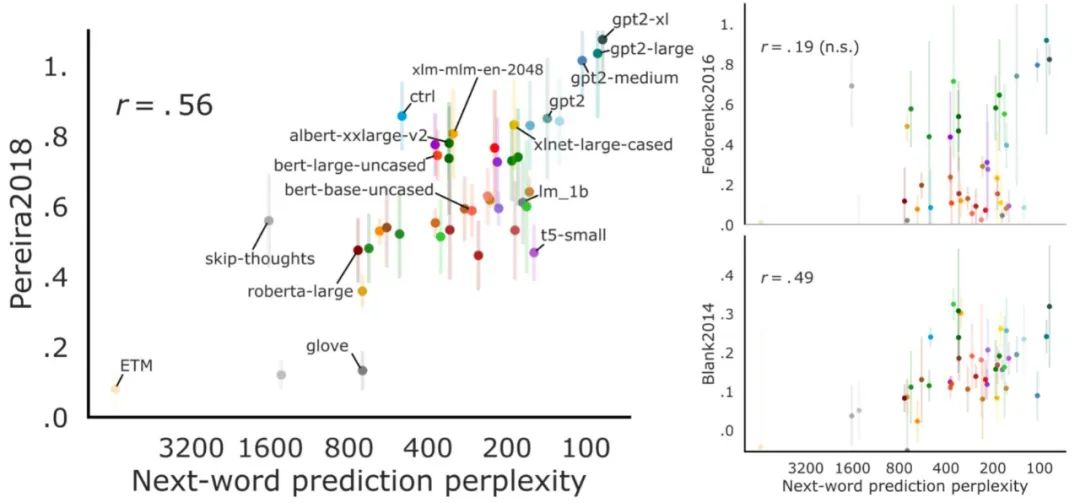
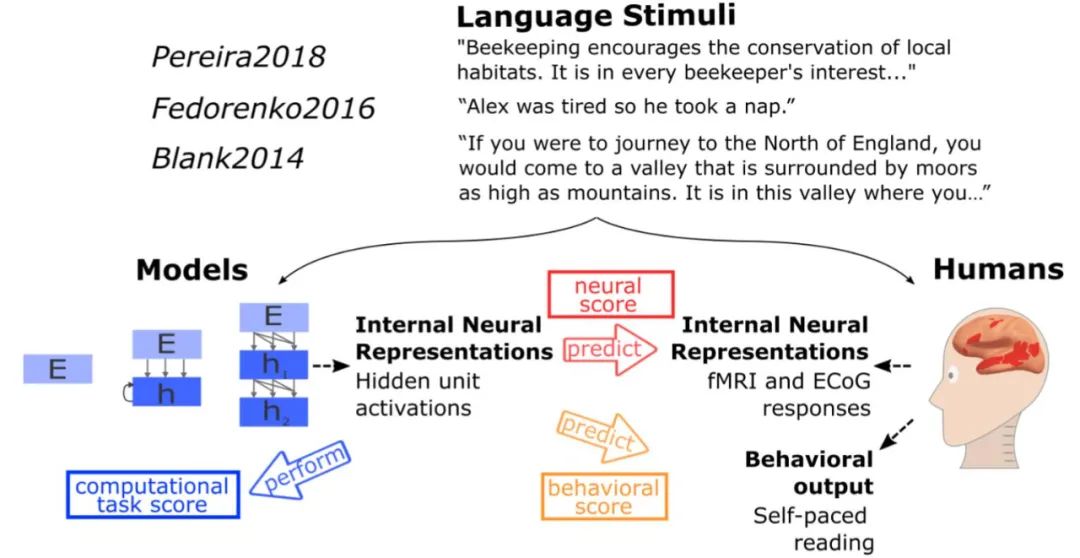
负责语言处理的人工神经网络模型与人类语言处理系统的比较。MIT 的研究者测试了不同模型对语言理解过程中的人类神经活动(fMRI and ECoG)和行为数据进行预测的效果。候选模型包括简单的嵌入模型、更复杂的循环模型和 transformer 网络。测试内容从句子到段落再到故事,这些内容要经历两个步骤:1)输入模型,2)呈现给人类参与者(视觉或听觉)。模型的内部表征主要在三个维度上进行评估:预测人类神经表征的能力;以阅读次数的形式预测人类行为的能力;执行计算任务的能力(例如下一个词预测)。研究者在许多个不同的模型中归纳分析了测试结果,得到的结论比从单个模型中得到的更具说服力。