
基于 Webpack 的工程化应用治理方案

当前市面上大部分前端应用都是基于webpack进行构建,而随着应用日益庞大,webpack应用就会出现构建速度慢,构建结果体积大等一系列问题。
1.webpack应用治理应该从哪个方向入手?
随着应用的不断迭代,webpack应用最常见的两个问题就是:
构建速度慢 构建体积大
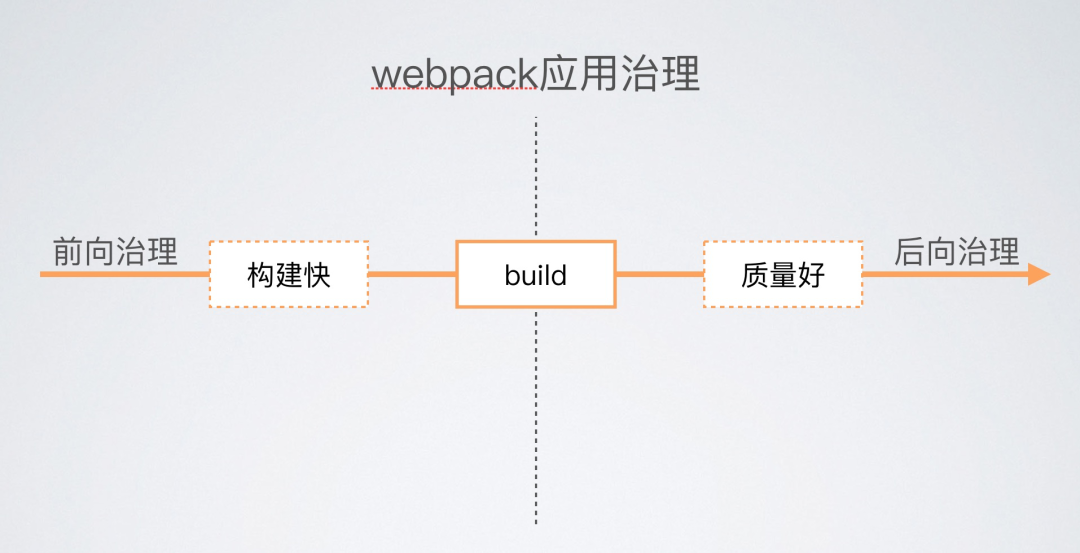
有一个很简单的划分方式,就是以构建(build)为分界线,分成前向治理和后向治理:
前向治理:提升构建速度 后向治理:保证构建结果质量
我们的治理方向,就是围绕前向治理和后向治理。
2.前向治理包含哪些内容?
前向治理的核心概念,就是一个字 快 ,目的就是提升构建速度,市面上大部分webpack优化文章都是这一类提升构建速度的文章,所以这里就简单介绍一些不错的实践
2.1 利用SMP采集webpack数据指标
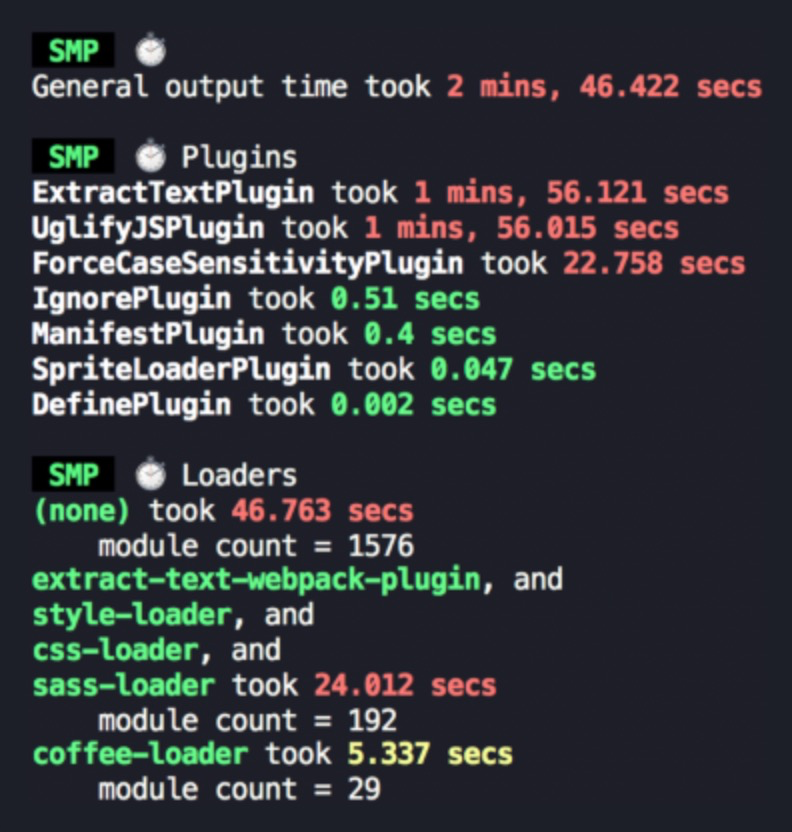
数据先行,通过speed-measure-webpack-plugin[1]采集性能指标,可以得到webpack在整个编译过程中在loader、plugin上花费的时间,基于该数据可以专项的进行优化和治理。
2.2 开启缓存
如果通过SMP分析得知在loader编译过程耗时较多,那么可以在核心loader,例如babel-loader中添加缓存。
{
loader: 'babel-loader',
options: {
cacheDirectory: true
}
}
复制代码
2.3 开启happyPack多线程编译
如果通过SMP分析得知在loader编译过程耗时较多,还可以通过使用happyPack[2],开启多线程编译,提升开发效率。
2.4 使用dll技术
dll可以简单理解成提前打包,例如lodash、echarts等大型npm包,可以通过dll将其提前打包好,这样在业务开发过程中就不用再重复去打包了,可以大幅缩减打包时间。
2.5 升级到webpack5
webpack5利用 持久缓存 来提高构建性能,或许升级webpack后,前述的各种优化,都将成为历史。
3. 后向治理包含哪些内容?
后向治理主要保证构建结果的质量
3.1可视化分析构建结果
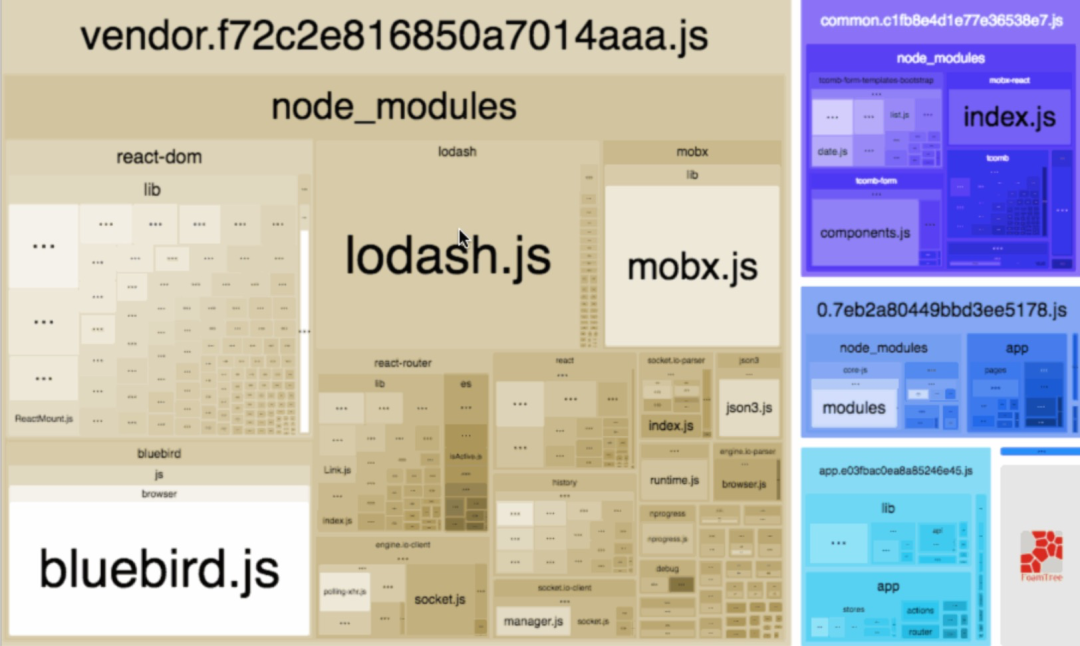
很常见的就是webpack-bundle-analyzeer[3],提供打包结果的可视化展示,如上图给予的决策帮助是:
是否需要按需加载 是否需要提取公共代码 是否需要制定cacheGroup的策略
3.2 清理deadcode
业务开发过程中,随着业务迭代,经常有些文件、模块及代码被废弃,这些废弃代码随着时间推移,将逐渐变为历史包袱,所以针对构建后结果,我们要做的就是清理其中的deadcode。
前面webpack-bundle-analyzeer虽然是最常用的插件,但依旧有一些缺陷:
3.2.1. 体积超小的deadcode模块引用,无法被准确识别
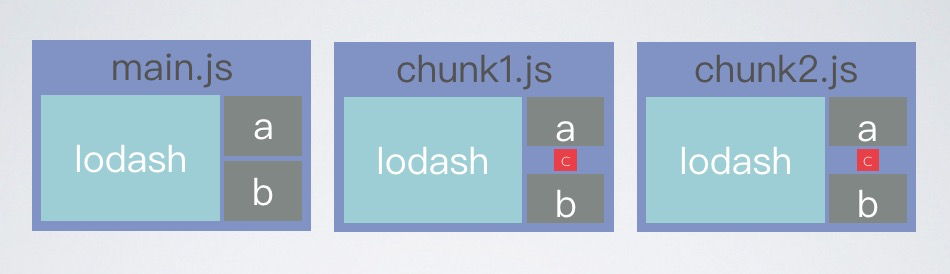
例如上图:
lodash体积大一下子就能被发现,就会意识到重复引用或者是未使用 但deadcode模块c体积很小,即便被chunk1、chunk2都引用了,也不一定能立刻发现,很容易被带到线上 而且这种deadcode也无法通过splitchunk来进行优化,因为splitchunk根据引用次数提取公共代码,无法分辨是否是废弃代码,所以对模块c.js这种的deadcode就无力了
3.2.2. tree-sharking只保留有用的代码,但deadcode还在那里
tree-sharking大家都了解,摇掉不需要的代码,做为最终的输出结果,但反过来说,这些废弃代码依旧在本地真实不虚的存在着。
所以如何能准确的清理掉deadcode呢?这就需要通过webpack的 统计信息(stats) 来进行更细节的分析
3.3 统计信息(stats)
stats[4]是通过 webpack 编译源文件时,生成的包含有关于模块的统计数据的 JSON 文件,这些统计数据不仅可以帮助开发者来分析应用的依赖图表,还可以优化编译的速度。
webpack --profile --json > compilation-stats.json
复制代码
通过上述全局命令即可输出统计信息,例如:
{
"version": "1.4.13", // Version of webpack used for the compilation
"hash": "11593e3b3ac85436984a", // Compilation specific hash
"time": 2469, // Compilation time in milliseconds
"filteredModules": 0, // A count of excluded modules when `exclude` is passed to the `toJson` method
"assetsByChunkName": {
// Chunk name to emitted asset(s) mapping
"main": "web.js?h=11593e3b3ac85436984a",
"named-chunk": "named-chunk.web.js",
"other-chunk": [
"other-chunk.js",
"other-chunk.css"
]
},
"assets": [
// A list of asset objects
],
"chunks": [
// A list of chunk objects
],
"modules": [
// A list of module objects
],
"errors": [
// A list of error strings
],
"warnings": [
// A list of warning strings
]
}
复制代码
modules:表示module的集合 module:webpack依赖树中的真实模块 chunks:表示chunk的集合 chunk:包含entry入口、异步加载模块、代码分割(code spliting)后的代码块
通过对modules和chunks加以分析,就可以得到webpack完整的依赖关系,从而梳理出废弃文件及废弃代码,同时也可以根据业务形态进行定制。
3.4 webpack-deadcode-plugin
前面提到分析stats.json,但因为是原始数据,数据量比较大,有一定处理和清洗成本,所以可以使用开源的webpack-deadcode-plugin[5]这个插件
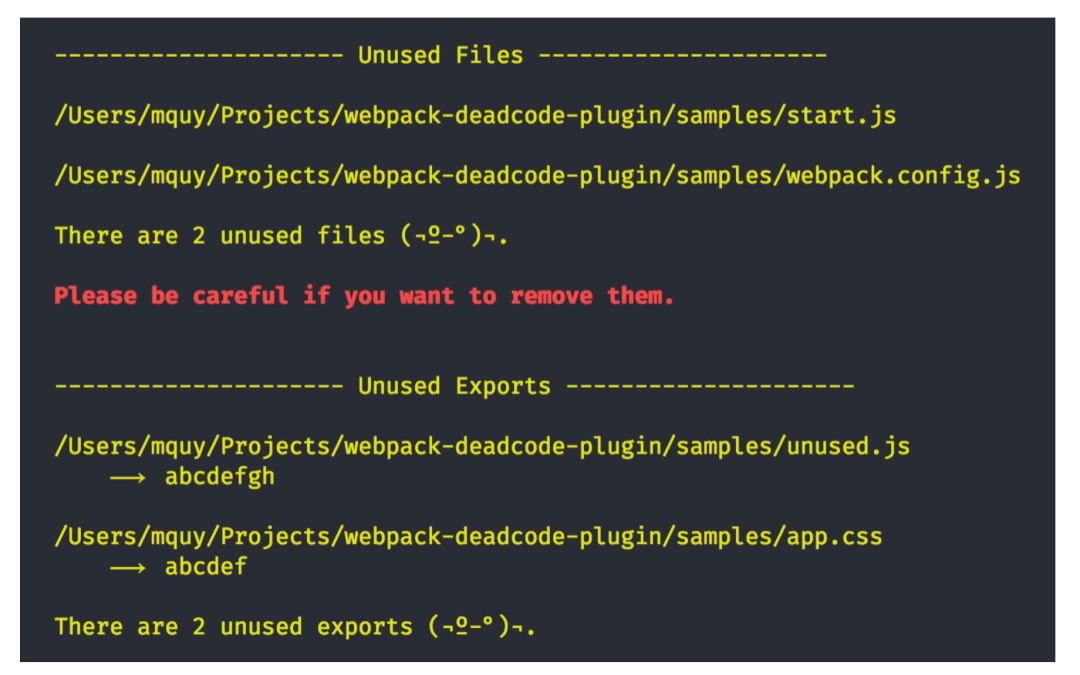
通过webpack-deadcode-plugin,可以快速筛选出:
未使用的文件 未使用的已暴露变量
3.5 结合eslint、tslint进行治理
lint可以快速的扫描出未使用的变量,这能够极大的提升我们的deadcode清理效率。
首先通过lint对未使用变量进行清理 再通过webpack-deadcode-plugin再扫描出未使用文件和未使用的导出变量
顿时整个应用干干净净,舒舒服服!
参考
1. speed-measure-webpack-plugin[6]
2. happyPack[7]
3. webpack-bundle-analyzeer[8]
4. stats[9]
5. webpack-deadcode-plugin[10]
关于本文
来源:百命
https://juejin.cn/post/6844904033434468359