
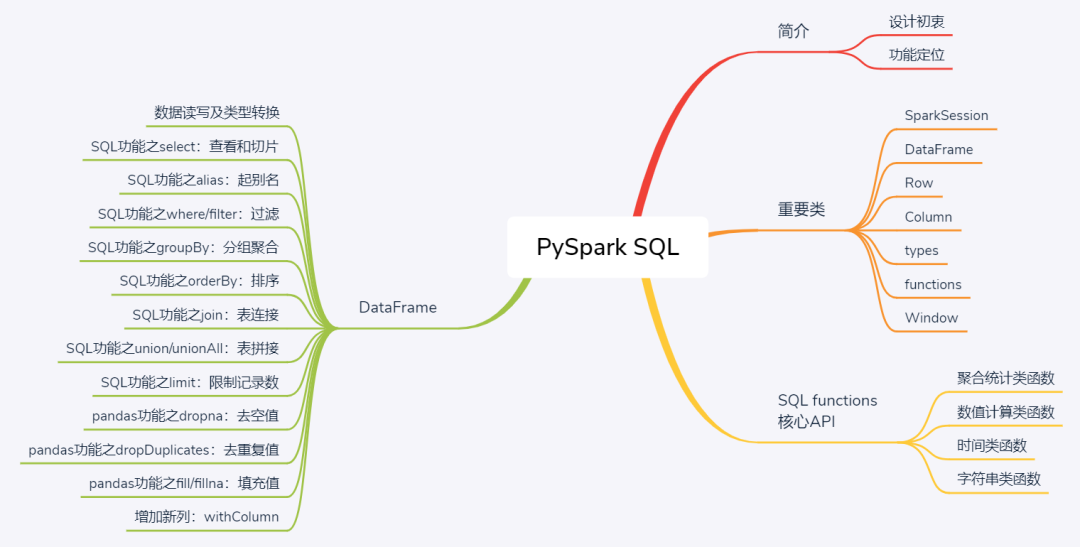
PySpark SQL——SQL和pd.DataFrame的结合体
导读
昨日推文PySpark环境搭建和简介,今天开始介绍PySpark中的第一个重要组件SQL/DataFrame,实际上从名字便可看出这是关系型数据库SQL和pandas.DataFrame的结合体,功能也几乎恰是这样,所以如果具有良好的SQL基本功和熟练的pandas运用技巧,学习PySpark SQL会感到非常熟悉和舒适。
惯例开局一张图
前文提到,Spark是大数据生态圈中的一个快速分布式计算引擎,支持多种应用场景。例如Spark core中的RDD是最为核心的数据抽象,定位是替代传统的MapReduce计算框架;SQL是基于RDD的一个新的组件,集成了关系型数据库和数仓的主要功能,基本数据抽象是DataFrame,与pandas.DataFrame极为相近,适用于体量中等的数据查询和处理。

核心有两层意思,一是为了解决用户从多种数据源(包括结构化、半结构化和非结构化数据)执行数据ETL的需要;二是满足更为高级的数据分析需求,例如机器学习、图处理等。而为了实现这一目的,Spark团队推出SQL组件,一方面满足了多种数据源的处理问题,另一方面也为机器学习提供了全新的数据结构DataFrame(对应ml子模块)。
了解了Spark SQL的起源,那么其功能定位自然也十分清晰:基于DataFrame这一核心数据结构,提供类似数据库和数仓的核心功能,贯穿大部分数据处理流程:从ETL到数据处理到数据挖掘(机器学习)。
注:由于Spark是基于scala语言实现,所以PySpark在变量和函数命名中也普遍采用驼峰命名法(首单词小写,后面单次首字母大写,例如someFunction),而非Python中的蛇形命名(各单词均小写,由下划线连接,例如some_funciton)
SparkSession:从名字可以推断出这应该是为后续spark各种操作提供了一个session会话环境,具体来说接收一个SparkContext对象作为输入,建立Spark SQL的主入口。SparkSession之于SQL的地位恰如SparkContext之于Spark的地位一样,都是提供了核心入口点。这里,直白的理解就是SparkContext相当于是Spark软件和集群硬件之间的"驱动",SparkContext就是用来管理和调度这些资源的;而SparkSession则是在SQL端对集群资源的进一步调度和分发。按照惯例,建立SparkSession流程和命名规范如下:
from pyspark import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext()
spark = SparkSession(sc)
DataFrame:是PySpark SQL中最为核心的数据结构,实质即为一个二维关系表,定位和功能与pandas.DataFrame以及R语言中的data.frame几乎一致。最大的不同在于pd.DataFrame行和列对象均为pd.Series对象,而这里的DataFrame每一行为一个Row对象,每一列为一个Column对象
Row:是DataFrame中每一行的数据抽象
Column:DataFrame中每一列的数据抽象
types:定义了DataFrame中各列的数据类型,基本与SQL中的数据类型同步,一般用于DataFrame数据创建时指定表结构schema
functions:这是PySpark SQL之所以能够实现SQL中的大部分功能的重要原因之一,functions子类提供了几乎SQL中所有的函数,包括数值计算、聚合统计、字符串以及时间函数等4大类,后续将专门予以介绍
Window:用于实现窗口函数功能,无论是传统关系型数据库SQL还是数仓Hive中,窗口函数都是一个大杀器,PySpark SQL自然也支持,重点是支持partition、orderby和rowsBetween三类操作,进而完成特定窗口内的聚合统计
注:这里的Window为单独的类,用于建立窗口函数over中的对象;functions子模块中还有window函数,其主要用于对时间类型数据完成重采样操作。
DataFrame是PySpark中核心的数据抽象和定义,理解DataFrame的最佳方式是从以下2个方面:
是面向二维关系表而设计的数据结构,所以SQL中的功能在这里均有所体现
无论是功能定位还是方法接口均与pd.DataFrame极为相似,所以部分功能又是仿照后者设计
换言之,记忆PySpark中的DataFrame只需对比SQL+pd.DataFrame即可。下面对DataFrame对象的主要功能进行介绍:
数据读写及类型转换。
1)创建DataFrame的方式主要有两大类:
从其他数据类型转换,包括RDD、嵌套list、pd.DataFrame等,主要是通过spark.createDataFrame()接口创建
从文件、数据库中读取创建,文件包括Json、csv等,数据库包括主流关系型数据库MySQL,以及数仓Hive,主要是通过sprak.read属性+相应数据源类型进行读写,例如spark.read.csv()用于读取csv文件,spark.read.jdbc()则可用于读取数据库
2)数据写入。与spark.read属性类似,.write则可用于将DataFrame对象写入相应文件,包括写入csv文件、写入数据库等
3)数据类型转换。DataFrame既然可以通过其他类型数据结构创建,那么自然也可转换为相应类型,常用的转换其实主要还是DataFrame=>rdd和DataFrame=>pd.DataFrame,前者通过属性可直接访问,后者则需相应接口:
df.rdd # PySpark SQL DataFrame => RDD
df.toPandas() # PySpark SQL DataFrame => pd.DataFrameselect:查看和切片
这是DataFrame中最为常用的功能之一,用法与SQL中的select关键字类似,可用于提取其中一列或多列,也可经过简单变换后提取。同时,仿照pd.DataFrame中提取单列的做法,SQL中的DataFrame也支持"[]"或"."两种提取方式,但与select查看的最大区别在于select提取后得到的是仍然是一个DataFrame,而[]和.获得则是一个Column对象。例如:
df = spark.createDataFrame([("John", 17), ("Tom", 18)], schema=["name", "age"])
df.select('name') # DataFrame[name: string]
df['name'] # Column
df.name # Column除了提取单列外,select还支持类似SQL中"*"提取所有列,以及对单列进行简单的运算和变换,具体应用场景可参考pd.DataFrame中赋值新列的用法,例如下述例子中首先通过"*"关键字提取现有的所有列,而后通过df.age+1构造了名字为(age+1)的新列。
df = spark.createDataFrame([("John", 17), ("Tom", 18)], schema=["name", "age"])
df.select('*', df.age+1).show()
"""
+----+---+---------+
|name|age|(age + 1)|
+----+---+---------+
|John| 17| 18|
| Tom| 18| 19|
+----+---+---------+
"""alias:起别名
熟悉SQL语法的都知道as的用法,实际上as即为alias的简写,这里的alias的功能与as也完全一致,即对一个对象起别名,除了对单列起别名外也支持对整个DataFrame对象起别名
df.select('*', (df.age+1).alias('age1')).show()
"""
+----+---+----+
|name|age|age1|
+----+---+----+
|John| 17| 18|
| Tom| 18| 19|
+----+---+----+
"""where/filter:条件过滤
SQL中实现条件过滤的关键字是where,在聚合后的条件中则是having,而这在sql DataFrame中也有类似用法,其中filter和where二者功能是一致的:均可实现指定条件过滤。以下4种写法均可实现特定功能:
df.where(df.age==18).show()
df.filter(df.age==18).show()
df.where('age=18').show()
df.filter('age=18').show()
"""
+----+---+
|name|age|
+----+---+
| Tom| 18|
+----+---+
"""值得指出的是在pandas.DataFrame中类似的用法是query函数,不同的是query()中表达相等的条件符号是"==",而这里filter或where的相等条件判断则是更符合SQL语法中的单等号"="。
groupby/groupBy:分组聚合
分组聚合是数据分析中最为常用的基础操作,其基本用法也与SQL中的group by关键字完全类似,既可直接根据某一字段执行聚合统计,也可根据某一列的简单运算结果进行统计。groupby和groupBy是互为别名的关系,二者功能完全一致。之后所接的聚合函数方式也有两种:直接+聚合函数或者agg()+字典形式聚合函数,这与pandas中的用法几乎完全一致,所以不再赘述,具体可参考Pandas中groupby的这些用法你都知道吗?一文。这里补充groupby的两个特殊用法:
groupby+window时间开窗函数时间重采样,对标pandas中的resample
groupby+pivot实现数据透视表操作,对标pandas中的pivot_table
# 原始DataFrame
df.show()
"""
+----+---+-------------------+
|name|age| time|
+----+---+-------------------+
|John| 17|2020-09-06 15:11:00|
| Tom| 17|2020-09-06 15:12:00|
| Joy| 17|2020-09-06 15:13:00|
| Tim| 18|2020-09-06 15:16:00|
+----+---+-------------------+
"""
# gorupby+pivot实现数据透视表
df.groupby(fn.substring('name', 1, 1).alias('firstName')).pivot('age').count().show()
"""
+---------+---+----+
|firstName| 17| 18|
+---------+---+----+
| T| 1| 1|
| J| 2|null|
+---------+---+----+
"""
# window函数实现时间重采样
df.groupby(fn.window('time', '5 minutes')).count().show()
"""
+--------------------+-----+
| window|count|
+--------------------+-----+
|[2020-09-06 15:10...| 3|
|[2020-09-06 15:15...| 1|
+--------------------+-----+
"""orderBy/sort:排序
orderby的用法与SQL中的用法也是完全一致的,都是根据指定字段或字段的简单运算执行排序,sort实现功能与orderby功能一致。接受参数可以是一列或多列(列表形式),并可接受是否升序排序作为参数。常规用法如下:
# 多列排序,默认升序
df.sort('name', 'age').show()
"""
+----+---+-------------------+
|name|age| time|
+----+---+-------------------+
|John| 17|2020-09-06 15:11:00|
| Joy| 17|2020-09-06 15:13:00|
| Tim| 18|2020-09-06 15:16:00|
| Tom| 17|2020-09-06 15:12:00|
+----+---+-------------------+
"""
# 多列排序,并制定不同排序规则
df.sort(['age', 'name'], ascending=[True, False]).show()
"""
+----+---+-------------------+
|name|age| time|
+----+---+-------------------+
| Tom| 17|2020-09-06 15:12:00|
| Joy| 17|2020-09-06 15:13:00|
|John| 17|2020-09-06 15:11:00|
| Tim| 18|2020-09-06 15:16:00|
+----+---+-------------------+
"""join:表连接
这也是一个完全等同于SQL中相应关键字的操作,并支持不同关联条件和不同连接方式,除了常规的SQL中的内连接、左右连接、和全连接外,还支持Hive中的半连接,可以说是兼容了数据库的数仓的表连接操作
union/unionAll:表拼接
功能分别等同于SQL中union和union all,其中前者是去重后拼接,而后者则直接拼接,所以速度更快
limit:限制返回记录数
与SQL中limit关键字功能一致
另外,类似于SQL中count和distinct关键字,DataFrame中也有相同的用法。
以上主要是类比SQL中的关键字用法介绍了DataFrame部分主要操作,而学习DataFrame的另一个主要参照物就是pandas.DataFrame,例如以下操作:
dropna:删除空值行
实际上也可以接收指定列名或阈值,当接收列名时则仅当相应列为空时才删除;当接收阈值参数时,则根据各行空值个数是否达到指定阈值进行删除与否
dropDuplicates/drop_duplicates:删除重复行
二者为同名函数,与pandas中的drop_duplicates函数功能完全一致
fillna:空值填充
与pandas中fillna功能一致,根据特定规则对空值进行填充,也可接收字典参数对各列指定不同填充
fill:广义填充
drop:删除指定列
最后,再介绍DataFrame的几个通用的常规方法:
withColumn:在创建新列或修改已有列时较为常用,接收两个参数,其中第一个参数为函数执行后的列名(若当前已有则执行修改,否则创建新列),第二个参数则为该列取值,可以是常数也可以是根据已有列进行某种运算得到,返回值是一个调整了相应列后的新DataFrame
# 根据age列创建一个名为ageNew的新列
df.withColumn('ageNew', df.age+100).show()
"""
+----+---+-------------------+------+
|name|age| time|ageNew|
+----+---+-------------------+------+
|John| 17|2020-09-06 15:11:00| 117|
| Tom| 17|2020-09-06 15:12:00| 117|
| Joy| 17|2020-09-06 15:13:00| 117|
| Tim| 18|2020-09-06 15:16:00| 118|
+----+---+-------------------+------+
"""
注意到,withColumn实现的功能完全可以由select等价实现,二者的区别和联系是:withColumn是在现有DataFrame基础上增加或修改一列,并返回新的DataFrame(包括原有其他列),适用于仅创建或修改单列;而select准确的讲是筛选新列,仅仅是在筛选过程中可以通过添加运算或表达式实现创建多个新列,返回一个筛选新列的DataFrame,而且是筛选多少列就返回多少列,适用于同时创建多列的情况(官方文档建议出于性能考虑和防止内存溢出,在创建多列时首选select)
show:将DataFrame显示打印
实际上show是spark中的action算子,即会真正执行计算并返回结果;而前面的很多操作则属于transform,仅加入到DAG中完成逻辑添加,并不实际执行计算
take/head/tail/collect:均为提取特定行的操作,也属于action算子
另外,DataFrame还有一个重要操作:在session中注册为虚拟表,而后即可真正像执行SQL查询一样完成相应SQL操作。
df.createOrReplaceTempView('person') # 将df注册为表名叫person的临时表
spark.sql('select * from person').show() # 通过sql接口在person临时表中执行SQL操作
"""
+----+---+-------------------+
|name|age| time|
+----+---+-------------------+
|John| 17|2020-09-06 15:11:00|
| Tom| 17|2020-09-06 15:12:00|
| Joy| 17|2020-09-06 15:13:00|
| Tim| 18|2020-09-06 15:16:00|
+----+---+-------------------+
"""
基于DataFrame可以实现SQL中大部分功能,同时为了进一步实现SQL中的运算操作,spark.sql还提供了几乎所有的SQL中的函数,确实可以实现SQL中的全部功能。按照功能,functions子模块中的功能可以主要分为以下几类:
聚合统计类,也是最为常用的,除了常规的max、min、avg(mean)、count和sum外,还支持窗口函数中的row_number、rank、dense_rank、ntile,以及前文提到的可用于时间重采样的窗口函数window等
数值处理类,主要是一些数学函数,包括sqrt、abs、ceil、floor、sin、log等
字符串类,包括子字符串提取substring、字符串拼接concat、concat_ws、split、strim、lpad等
时间处理类,主要是对timestamp类型数据进行处理,包括year、month、hour提取相应数值,timestamp转换为时间戳、date_format格式化日期、datediff求日期差等
这些函数数量较多,且与SQL中相应函数用法和语法几乎一致,无需全部记忆,仅在需要时查找使用即可。
本文较为系统全面的介绍了PySpark中的SQL组件以及其核心数据抽象DataFrame,总体而言:该组件是PySpark中的一个重要且常用的子模块,功能丰富,既继承了Spark core中RDD的基本特点(算子和延迟执行特性),也是Spark.ml机器学习子模块的基础数据结构,其作用自然不言而喻。
与此同时,DataFrame学习成本并不高,大致相当于关系型数据库SQL+pandas.DataFrame的结合体,很多接口和功能都可以触类旁通。
相关阅读: