
Hudi 原理 | Apache Hudi 中自定义序列化和数据写入逻辑

1. 介绍
在Apache Hudi中,Hudi的一条数据使用HoodieRecord这个类表示,其中包含了hoodie的主键,record的分区文件位置,还有今天本文的关键,payload。payload是一个条数据的内容的抽象,决定了同一个主键的数据的增删改查逻辑也决定了其序列化的方式。通过对payload的自定义,可以实现数据的灵活合并,数据的自定义编码序列化等,丰富Hudi现有的语义,提升性能。
2. 场景
包括但不限于如下场景中,我们可以通过自定义payload来实现灵活的需求。
•实现同一个主键的数据非row level replace语义的合并,如mvcc语义等•实现同一个主键下多时间戳数据灵活排序的语义•实现输出redo/undo log的效果•实现自定义序列化逻辑
3. 作用方式
首先我们回顾一下一条HoodieRecord在Spark环境中使用RDD API upsert写入MOR表的生命周期。
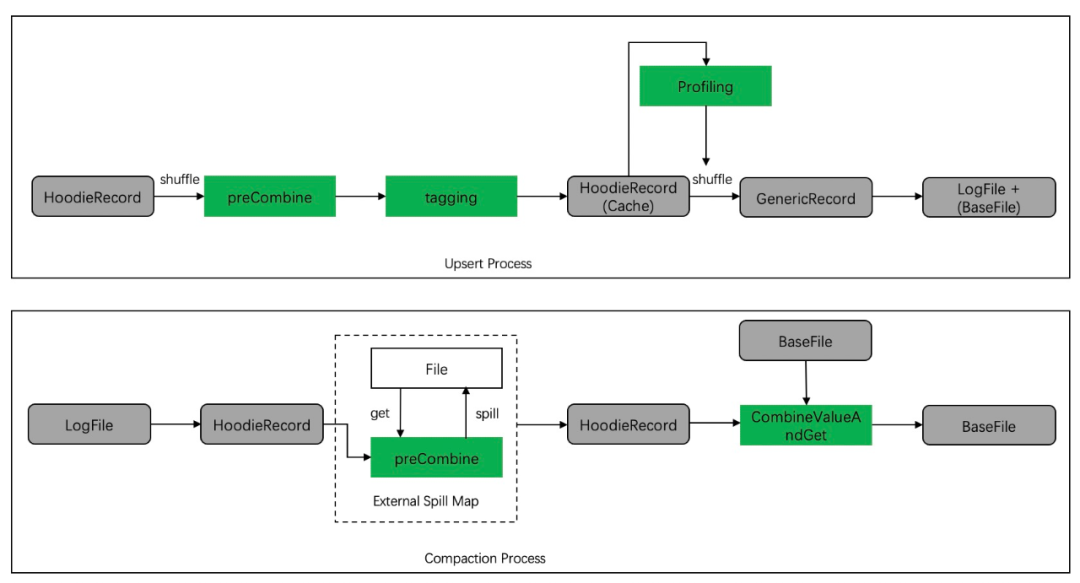
注意:在这个过程中,shuffle/写入文件/磁盘spill的时候,都需要保证数据是已经被序列化过的格式。
4. 实现方式
在Hudi中,默认的payload实现是DefaultHoodieRecordPayload,它是OverwriteWithLatestAvroPayload子类。而OverwriteWithLatestAvroPayload这个类继承了BaseAvroPayload并implements HoodieRecordPayload这个接口。
其中BaseAvroPayload决定了数据的序列化方式,而HoodieRecordPayload决定了数据的合并方式。后者是必须使用的,但是前者不是。下面来分别分析他们的实现。
BaseAvroPayload
/*** Base class for all AVRO record based payloads, that can be ordered based on a field.*/public abstract class BaseAvroPayload implements Serializable {/*** Avro data extracted from the source converted to bytes.*/public final byte[] recordBytes;/*** For purposes of preCombining.*/public final Comparable orderingVal;/*** Instantiate {@link BaseAvroPayload}.** @param record Generic record for the payload.* @param orderingVal {@link Comparable} to be used in pre combine.*/public BaseAvroPayload(GenericRecord record, Comparable orderingVal) {this.recordBytes = record != null ? HoodieAvroUtils.avroToBytes(record) : new byte[0];this.orderingVal = orderingVal;if (orderingVal == null) {throw new HoodieException("Ordering value is null for record: " + record);}}}
首先BaseAvroPayload implements了Serializable接口,标志着这个类和它的子类都是为了序列化而设计的,大家在继承的时候需要注意子类相关attribute的可序列化问题。
构造器传入了GenericRecord和一个Comparable的变量。由于Hudi使用avro作为内部的行存序列化格式,所以输入的数据需要以GenericRecord的形式传递给payload。BaseAvroPayload会将数据直接序列化成binary待IO使用。这里的假设是我们只需要做row level操作,直接操作整行的二进制数据毫无疑问是非常高效的,这里的orderingVal是因为基于行级别的record比较在RDBMS的CDC中是非常常见的,所以增加了这个字段。这样处理之后,只需保证comparable的变量也是可序列化的,这个类的所有attribute都已经是可序列化的格式了,使用任意序列化框架直接传输即可。
HoodieRecordPayload
/*** Every Hoodie table has an implementation of theHoodieRecordPayloadcode> This abstracts out callbacks which depend on record specific logic.*/@PublicAPIClass(maturity = ApiMaturityLevel.STABLE)public interface HoodieRecordPayload<T extends HoodieRecordPayload> extends Serializable {/*** This method is deprecated. Please use this {@link #preCombine(HoodieRecordPayload, Properties)} method.*/@Deprecated@PublicAPIMethod(maturity = ApiMaturityLevel.DEPRECATED)T preCombine(T oldValue);/*** When more than one HoodieRecord have the same HoodieKey, this function combines them before attempting to insert/upsert by taking in a property map.* Implementation can leverage the property to decide their business logic to do preCombine.** @param oldValue instance of the old {@link HoodieRecordPayload} to be combined with.* @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.** @return the combined value*/@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)default T preCombine(T oldValue, Properties properties) {return preCombine(oldValue);}/*** This methods is deprecated. Please refer to {@link #combineAndGetUpdateValue(IndexedRecord, Schema, Properties)} for java docs.*/@Deprecated@PublicAPIMethod(maturity = ApiMaturityLevel.DEPRECATED)Option<IndexedRecord> combineAndGetUpdateValue(IndexedRecord currentValue, Schema schema) throws IOException;/*** This methods lets you write custom merging/combining logic to produce new values as a function of current value on storage and whats contained* in this object. Implementations can leverage properties if required.** eg:* 1) You are updating counters, you may want to add counts to currentValue and write back updated counts* 2) You may be reading DB redo logs, and merge them with current image for a database row on storage* p>** @param currentValue Current value in storage, to merge/combine this payload with* @param schema Schema used for record* @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.* @return new combined/merged value to be written back to storage. EMPTY to skip writing this record.*/default Option<IndexedRecord> combineAndGetUpdateValue(IndexedRecord currentValue, Schema schema, Properties properties) throws IOException {return combineAndGetUpdateValue(currentValue, schema);}/*** This method is deprecated. Refer to {@link #getInsertValue(Schema, Properties)} for java docs.* @param schema Schema used for record* @return the {@link IndexedRecord} to be inserted.*/@Deprecated@PublicAPIMethod(maturity = ApiMaturityLevel.DEPRECATED)Option<IndexedRecord> getInsertValue(Schema schema) throws IOException;/*** Generates an avro record out of the given HoodieRecordPayload, to be written out to storage. Called when writing a new value for the given* HoodieKey, wherein there is no existing record in storage to be combined against. (i.e insert) Return EMPTY to skip writing this record.* Implementations can leverage properties if required.* @param schema Schema used for record* @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.* @return the {@link IndexedRecord} to be inserted.*/@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)default Option<IndexedRecord> getInsertValue(Schema schema, Properties properties) throws IOException {return getInsertValue(schema);}/*** This method can be used to extract some metadata from HoodieRecordPayload. The metadata is passed to {@code WriteStatus.markSuccess()} and* {@code WriteStatus.markFailure()} in order to compute some aggregate metrics using the metadata in the context of a write success or failure.* @return the metadata in the form of Map<String, String> if any.*/@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)default Option<Map<String, String>> getMetadata() {return Option.empty();}}
这个类的注释写得非常清楚,其中每个方法都有定义两个个不同接口,截止本文发出时候(0.9.0版本),部分内部逻辑还在使用deprecated的旧版本,所以在使用时需要注意,逻辑最好放在旧接口里。
简单来说,preCombine 这个方法定义了两个payload合并的逻辑,在两个场景下会被调用:
1.当deduplicated 开启时,写入的数据两两合并时用到2.在MOR表发生compaction时,两条从log中读取的payload合并时用到3.MOR表使用RT视图读取时
而combineAndGetUpdateValue 则定义了写入数据和baseFile中的数据(这里已经被转化成avro的行存格式)的合并方式。通常情况下,这合并逻辑应该和preCombine保持语义上的一致。
最后getInsertValue则定义了如何将数据从payload形式转化成GenericRecord。在Hoodie相关的WriteHandle中被大量使用。通常是被用在写入Log/BaseFile时调用的。
几点额外注意的是:
1.combineAndGetUpdateValue和getInsertValue返回的都是Option,在这里,如果返回Option.empty(),就是指数据删除的意思。EmptyHoodieRecordPayload 正是这一逻辑的payload表达,如果preCombine的返回结果是删除,则可以返回这个类的实例。而hoodie中,在insert和upsert中通过添加_hoodie_is_deleted字段来实现删除的原理,本质上也是在payload中判断到这个字段,就返回空来实现的。2.不论是否继承BaseAvroPayload这个类/是否需要Comparable类型的orderingVal, 最好保留(GenericRecord, Comparable)这个构造器,因为Hudi中存在反射调用创建对象,默认寻找的构造器就是这个。
5. 使用场景
5. 1 Column Level的数据合并
有时候我们希望能够实现两个数据合并时,能够按照每个列的实现不同的合并逻辑。这时候就可以在preCombine和combineAndGetUpdateValue方法中借助schema遍历所有列,然后做不同的处理。如果需要在preCombine中使用Schema,可以在构造器初始化的时候保留GenericRecord中schema的引用。如果发生序列化后的传输,同时又没有使用schema可以序列化的版本(avro 1.8.2中 schema是不可序列化的对象),那么可以从方法中传递的properties中传递的信息构建schema。
public HoodieRecordPayload preCombine(HoodieRecordPayload oldValue, Properties properties) {if (schema == null) {this.schema = new Schema.Parser().parse(properties.get(HoodieWriteConfig.AVRO_SCHEMA_STRING.key()));}initialSchema(properties);GenericRecord thisRecord = getInsertValue(schema).get();GenericRecord otherRecord = oldValue.getInsertValue(schema).get();List<Schema.Field> fields = schema.getFields();for (Schema.Field field : fields) {// logic for each column}return new HoodieRecordPayload(thisRecord, orderingVal);}
5.2 实现自定义的序列化方式
在默认的BaseAvroPayload中,一次upsert,一条数据通常最少要序列化/反序列化三次,第一次是创建payload的时候,第二次是在写入时反序列化,第三次是写入文件时序列化。如果数据非常复杂,序列化其实是非常耗时的。我们可以通过灵活定义payload来决定序列化的方式,减少触发正反序列化的次数。这个技巧在Compaction的时候也可以获得收益。如考虑如下场景:
对于一条kakfa的数据,我们可以把key和partition相关的内容存在kafka的key/timestamp中。然后使用binary的方式获取kafka的value。通过kafka的key来构建HoodieRecordKey,然后将value直接以二进制方式存在payload中的map/list中,这样不会触发任何关于数据的序列化,额外的开销很低。而后将合并的逻辑放在getInsertValue方法中,在从payload转换成GenericRecord时,才将binary进行同一个key的数据合并和数据,这样只需要一次avro的序列化操作就可以完成写入过程。
需要注意的是,这样的设计方式毫无疑问增加了复杂度,使业务逻辑抽象方式变难,同时因为avro的序列化压缩比例通常比较高,如果直接传输业务数据,可能会有更大的IO和内存占用,需要根据场景评估收益。
6. 总结
本篇文章中我们介绍了Apache Hudi的关键数据抽象payload逻辑,同时介绍了几种关键payload的实现,最后给出基于payload的几种典型应用场景。