
HBase 实践 | 单节点多 RegionServer 部署与性能测试
目录导读
1. 引言
2. 合理的Region数量
3. Region数量优化
3.1提高RegionServer的堆内存
3.2 单节点多Region Server的部署
4. 单RS、多RS、单RS大堆集群环境的YCSB压测数据对比
5. 总结
6. 参考链接
1. 引言
随着集群中总的Region数持续增长,每个节点平均管理的Region数已达550左右,某些大表的写入流量一上来,Region Server就会不堪重负,相继挂掉。
在HBase中,Region的一个列族对应一个MemStore,通常一个MemStore的默认大小为128MB(我们设置的为256MB),见参数hbase.hregion.memstore.flush.size。当可用内存足够时,每个MemStore可以分配128MB的空间。
当表的写入流量上升时,假设每个Region的写入压力相同,则理论上每个MemStore会平均分配可用的内存空间。
因此,节点中Region过多时,每个MemStore分到的内存空间就会变小。此时,写入很小的数据量,就会被强制flush到磁盘,进而导致频繁刷写,会对集群HBase与HDFS造成很大的压力。
同时,Region过多导致的频繁刷写,又会在磁盘上产生非常多的HFile小文件,当小文件过多的时候,HBase为了优化查询性能就会做Compaction操作,合并HFile,减少文件数量。当小文件一直很多的时候,就会出现 “压缩风暴”。Compaction非常消耗系统的IO资源,还会降低数据的写入速度,严重时会影响正常业务的进行。
2. 合理的Region数量
关于每个Region Server节点中,Region数量大致合理的范围,HBase官网上也给出了定义:

可见,通常情况下,每个节点拥有20-200个Region是比较正常的。
其实,每个Region Server的最大Region数量由总的MemStore内存大小决定。每个Region的每个列族会对应一个MemStore,假设HBase表都有一个列族,那么每个Region只包含一个MemStore。一个MemStore大小通常在128~256MB,见参数:hbase.hregion.memstore.flush.size。默认情况下,RegionServer会将自身堆内存的40%(我们线上60%)(见参数:hbase.regionserver.global.memstore.size)提供给节点上的所有MemStore使用,如果所有MemStore的总大小达到该配置大小,新的更新将会被阻塞并且会强制刷写磁盘。因此,每个节点最理想的Region数量应该由以下公式计算(假设HBase表都有统一的列族配置):
((RS memory) * (total memstore fraction)) / ((memstore size)*(column families))
其中:
RS memory:表示Region Server堆内存的大小,即HBASE_HEAPSIZE。 total memstore fraction:表示所有MemStore占HBASE_HEAPSIZE的比例,HBase0.98版本以后由hbase.regionserver.global.memstore.size参数控制,老版本由hbase.regionserver.global.memstore.upperLimit参数控制,默认值0.4。 memstore size:即每个MemStore的大小,HBase中默认128M。 column families:即表的列族数量,通常情况下只设置1个,最好不超过3个。
以我们线上集群的配置举例,我们每个RegionServer的堆内存是32GB,那么节点上最理想的Region数量应该是:32768*0.6/256 ≈ 76(32768*0.6/128 ≈ 153)
500个region反推每个节点需要的堆内存为:
500 * 256 / 0.6 / 1024 ≈ 208G(500 * 128 / 0.6 / 1024 ≈ 104G)
上述最理想的情况是假设每个Region上的填充率都一样,包括数据写入的频次、写入数据的大小,但实际上每个Region的负载各不相同,有的Region可能特别活跃、负载特别高,有的Region则比较空闲。所以,通常我们认为2~3倍的理想Region数量也是比较合理的,针对上面举例来说,大概200~300个Region左右算是合理的。
3. Region数量优化
针对上文所述的Region数过多的隐患,以下内容主要从两方面考虑来优化。
提高单个Region Server的堆内存,保证每个Region的MemStore被分配到比较充裕的内存空间,避免写入高峰期,引起频繁刷写。 单节点多Region Server配置,如果你的物理机资源充裕,可以考虑部署多个RS进程来削弱写入压力(这也许可以作为一个应急的方案)。
3.1提高RegionServer的堆内存
提高内存的目的是为了增加每个Region拥有的MemStore的空间,避免其写入压力上升时,MemStore频繁刷写,形成小的HFile过多,引起压缩风暴,占用大量IO。
但其实RS的堆内存并不是越大越好,我们开始使用HBase的时候,对CMS和G1相关的参数,进行了大量压测,测试指标数据表明,内存分配的越大,吞吐量和p99读写平均延时会有一定程度的变差(也有可能是我们的JVM相关参数,当时调配的不合理)。
在我们为集群集成jdk15,设置为ZGC之后,多次压测并分析JVM日志之后,得出结论,在牺牲一定吞吐量的基础上,集群的GC表现能力确实提升的较为明显,尤其是GC的平均停顿时间,99.9%能维持在10ms以下。
而且ZGC号称管理上T的大内存,停顿时间控制在10ms之内(JDK16把GC停顿时间控制在1ms内,期待JDK17 LTS),STW时间不会因为堆的变大而变长。
因此理论上,增加RS堆内存之后,GC一样不会成为瓶颈。
3.2 单节点多Region Server的部署
之所以考虑在单节点上部署多个Region Server的进程,是因为我们单个物理机的资源配置很高,内存充足(三百多G,RS堆内存只分了32G)、而HBase又是弱计算类型的服务,平时CPU的利用率低的可怜,网络方面亦未见瓶颈,唯一掉链子的也就属磁盘了,未上SSD,IO延迟较为严重。
当然,也曾考虑过虚拟机的方案,但之前YCSB压测的数据都不太理想;K8s的调研又是起步都不算,没有技术积累。因此,简单、直接、易操作的方案就是多RS部署了。
以下内容先叙述CDH中多RS进程部署的一些关键流程,后续将在多RS、单RS、单RS大堆环境中,对集群进行基准性能测试,并对比试验数据,分析上述两种优化方案的优劣。
我们使用的HBase版本是2.1.0-cdh6.3.2,非商业版,未上Kerberos,CDH中HBase相关的jar包已替换为用JDK15编译的jar。
多Region Server的部署比较简单,最关键的是修改hbase-site.xml中region server的相关端口,避免端口冲突即可。可操作流程如下。
修改所需配置文件
hbase-site.xml配置文件一定不要直接从/etc/hbase/conf中获取,这里的配置文件是给客户端用的。CDH管理的HBase,配置文件都是运行时加载的,所以,找到HBase最新启动时创建的进程相关的目录,即可获取到服务端最新的配置文件,如:/var/run/cloudera-scm-agent/process/5347-hbase-REGIONSERVER。需要准备的目录结构如下:
不需要HBase完整安装包中的内容(在自编译的完整安装包中运行RS进程时,依赖冲突或其他莫名其妙的报错会折磨的你抓狂),只需要bin、conf目录即可,pids文件夹是自定义的,RS进程对应pid文件的输出目录,start_rs.sh、stop_rs.sh是自定义的RS进程的启动和关闭脚本。
重点修改下图标注的配置文件,
hbase-site.xml

log4j
log.threshold=INFO
main.logger=RFA
hbase.root.logger=INFO,RFA
log4j.rootLogger=INFO,RFA
log.dir=/var/log/hbase
log.file=${hbase.log.file}
max.log.file.size=200MB
max.log.file.backup.index=10
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=/var/log/hbase/${hbase.log.file}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.RFA.MaxFileSize=200MB
log4j.appender.RFA.MaxBackupIndex=10
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.logger.org.apache.zookeeper=INFO
log4j.logger.org.apache.hadoop.hbase.zookeeper.ZKUtil=INFO
log4j.logger.org.apache.hadoop.hbase.zookeeper.ZooKeeperWatcher=INFO
# CM日志采集相关的配置去掉,否则启动报Log4j相关的异常
hbase-env.sh
# 自定义HBase 配置文件的路径
export CUSTOM_HBASE_HOME=`dirname "$(cd "$(dirname $0)"; pwd)"`
# 定义HBase Region Server的相关端口号
REGION_SERVER_PORT=16110
# 定义JMX配置,暴露JMX端口给普罗米修斯,采集相关Metric数据
JMX_REMOTE_PORT=11100
JMX_PROMETHEUS_AGENT_PORT=9320
# 定义本机名称
HOST_NAME="`hostname`"
export JAVA_HOME=/usr/java/openjdk-15.0.2
# RS运行时找的HBase home,非常重要
export HBASE_HOME=/opt/cloudera/parcels/CDH/lib/hbase/
# RS运行时找的HBase配置文件home,非常重要
export HBASE_CONF_DIR=$CUSTOM_HBASE_HOME/conf
# HBASE日志相关
export HBASE_LOG_DIR=/var/log/hbase
export HBASE_LOGFILE="hbase-regionserver-$HOST_NAME-$REGION_SERVER_PORT"
export HBASE_PID_DIR=$CUSTOM_HBASE_HOME/pids
export HBASE_OPTS=""
# Uncomment one of the below three options to enable java garbage collection logging for the server-side processes.
export HBASE_REGIONSERVER_OPTS="-XX:MaxDirectMemorySize=26843545600 -Xms34359738368 -Xmx34359738368 -XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m -XX:+UnlockExperimentalVMOptions -XX:+UseZGC -XX:ConcGCThreads=2 -XX:ParallelGCThreads=6 -XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5 -XX:+UnlockDiagnosticVMOptions -XX:-ZProactive -Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/var/log/hbase/region-server-$REGION_SERVER_PORT-zgc-%t.log:time,tid,tags:filecount=5,filesize=500m --illegal-access=warn --add-exports java.base/jdk.internal=ALL-UNNAMED --add-exports java.base/jdk.internal.access=ALL-UNNAMED --add-exports java.base/jdk.internal.misc=ALL-UNNAMED --add-exports java.base/java.lang=ALL-UNNAMED --add-exports java.base/java.lang.reflect=ALL-UNNAMED --add-exports java.base/java.nio=ALL-UNNAMED --add-exports java.base/sun.nio.ch=ALL-UNNAMED --add-exports java.base/sun.nio.cs=ALL-UNNAMED --add-exports java.base/java.security=ALL-UNNAMED --add-exports java.base/sun.security.pkcs=ALL-UNNAMED --add-exports java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-exports java.base/java.util=ALL-UNNAMED --add-exports java.base/java.util.regex=ALL-UNNAMED --add-exports java.base/java.util.zip=ALL-UNNAMED --add-exports java.base/java.net=ALL-UNNAMED --add-exports java.base/java.io=ALL-UNNAMED --add-exports java.base/javax.crypto=ALL-UNNAMED --add-opens java.base/jdk.internal=ALL-UNNAMED --add-opens java.base/jdk.internal.access=ALL-UNNAMED --add-opens java.base/jdk.internal.misc=ALL-UNNAMED --add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED --add-opens java.base/java.nio=ALL-UNNAMED --add-opens java.base/sun.nio.ch=ALL-UNNAMED --add-opens java.base/sun.nio.cs=ALL-UNNAMED --add-opens java.base/java.security=ALL-UNNAMED --add-opens java.base/sun.security.pkcs=ALL-UNNAMED --add-opens java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.util.regex=ALL-UNNAMED --add-opens java.base/java.util.zip=ALL-UNNAMED --add-opens java.base/java.net=ALL-UNNAMED --add-opens java.base/java.io=ALL-UNNAMED --add-opens java.base/javax.crypto=ALL-UNNAMED -Dorg.apache.hbase.thirdparty.io.netty.tryReflectionSetAccessible=true -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.port=$JMX_REMOTE_PORT -javaagent:/data/hbase/monitor/jmx_prometheus_javaagent-0.11.0.jar=$JMX_PROMETHEUS_AGENT_PORT:/data/hbase/monitor/hbase_regonserver.yml -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hbase_hbase-REGIONSERVER-$HOST_NAME-$REGION_SERVER_PORT.hprof -XX:OnOutOfMemoryError=/opt/cloudera/cm-agent/service/common/killparent.sh"
export HBASE_MANAGES_ZK=false
还有日志文件名的一些输出细节,可以按需在bin/hbase-daemon.sh中修改。
start_rs.sh 和stop_rs.sh
#!/usr/bin/env bash
current_hbase_home="$(cd "$(dirname $0)"; pwd)"
sh $current_hbase_home/bin/hbase-daemon.sh start regionserver
#!/usr/bin/env bash
current_hbase_home="$(cd "$(dirname $0)"; pwd)"
sh $current_hbase_home/bin/hbase-daemon.sh stop regionserver
运行或关闭RS进程
sudo -uhbase sh /data/hbase/hbase_16110/start_rs.sh
sudo -uhbase sh /data/hbase/hbase_16110/stop_rs.sh
中间有异常,请查看相关日志输出。
4. 单RS、多RS、单RS大堆集群环境的YCSB压测数据对比
集群Region数疯涨,当写入存在压力时,会导致RS节点异常退出。为了解决目前的这种窘境,本次优化主要从单节点多Region Server部署和提高单个Region Server节点的堆内存两方面着手。
那这两种优化方案对HBase的读写性能指标,又会产生什么样的影响呢?我们以YCSB基准测试的结果指标数据做为参考,大致评价下这两种应急方案的优劣。
用于此次测试的HBase集群的配置
**使用的集群:**5个节点集群(5个Region Server) 说明:Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz,377GB Ram,12-3TB磁盘 **安全性:**未配置(无Kerberos) CDH版本: hbase2.1.0-cdh6.3.2JDK使用 AdoptOpenJDK15HBase Region Server配置了32GB堆 HBase HMaster已配置有8GB堆
此次测试使用的数据集大小
1TB数据、10亿行
测试方法
压测时选择的读写负载尽量模拟线上的读写场景,分别为:读写3/7、读写7/3、读写5/5;
压测时唯一的变量条件是:多RS部署(32G堆,在每个节点上启动3个RS进程,相当于集群中一共有15个RS节点)、单RS部署(32G小堆)和单RS部署(100G大堆),并尽可能保证其他实验条件不变,每个YCSB的工作负载各自运行20分钟左右,并且重复完整地运行5次,两次运行之间没有重新启动,以测量YCSB的吞吐量等指标,收集的测试结果数据是5次运行中最后3次运行的平均值,为了避免第一轮和第二轮的偶然性,忽略了前两次的测试。
YCSB压测的命令是:
python ycsb-0.15.0/bin/ycsb run hbase20 -P ycsb-0.15.0/workloads/workloada_3_7 -p table=usertable -p columnfamily=cf -p operationcount=100000000 -threads 200 -jvm-args '-Xms2048m -Xmx4096m -Xmn1024m' -cp /etc/hbase/conf/hbase-site.xml -s > logs/run-workloada_3_7.log
收集实验数据后,大致得出不同读写负载场景下、各个实验条件下的指标数据,如下图。
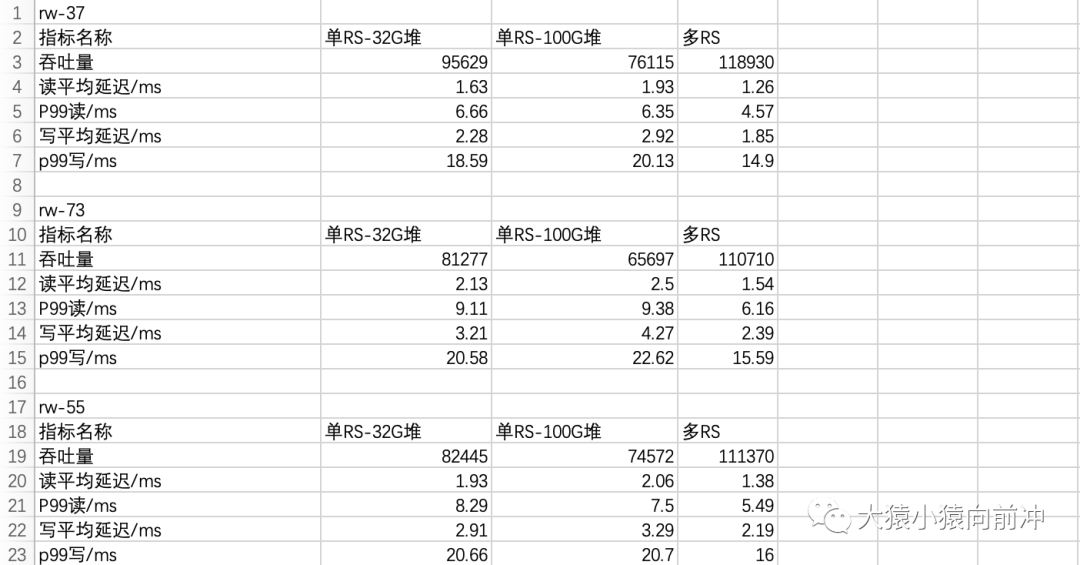
上述的测试数据比较粗糙,但大致也能得出些结论,提供一定程度上的参考。
集群Region数过多,横向增加节点,减少每个RS节点管理的Region数,在应对写入洪峰时能起到立竿见影的效果。 15个RS进程,在应对写入压力时,也会游刃有余,不会导致RS节点意外退出。观其吞吐量,与单纯5个RS节点相比,也并没有理论值几倍的提升(或许是单个客户端的压测能力有限,也许是多个RS进程受制于同一个IO环境),但其(平均、P99)读写延迟都有明显的改善。 盲目增加RS的堆内存,并不一定会得到性能上的提升(CDH官方所提供的建议值也是32G),内存的增加,GC的压力可能会随之增加,我们需要调试出一组合适的GC参数,或许才能得到最大化地提高集群性能。
5. 总结
多RS进程部署的模式,起到了一定程度上的进程间资源隔离的作用,分担了原先单台RS管理Region的压力,最大化利用了物理机的资源,但多出来的一些Region Server,需要单独的管理脚本和监控系统来维护,增加了维护成本。多个RS依赖同一台物理机,物理节点宕机便会影响多个RS进程,同时,某一个Region Server出现热点,压力过大,资源消耗过度,也许会引起同机其他进程的不良,在一定程度上,牺牲了稳定性和可靠性。
增加单个RS进程的堆内存,MemStore在一定程度上会被分配更充裕的内存空间,减小了flush的频次,势必会削弱写入的压力,但也可能会增加GC的负担,我们或许需要调整出合适的GC参数,甚至需要调优HBase本身的一些核心参数,才能兼顾稳定和性能。然而,这就又是一件漫长而繁琐的事情了,在此不过分探讨。
面对性能瓶颈的出现,我们不能盲目地扩充机器,在应急方案采取之后,我们需要做一些额外的、大量的优化工作,这或许才是上上之策。
6. 参考链接
http://hbase.apache.org/book.html https://zhuanlan.zhihu.com/p/60357239 https://blog.csdn.net/high2011/article/details/107296170