
测试环境问题排查的那些事儿
作者|刘宝成
笔者在转转主要负责环境治理相关的工作,本篇主要和大家分享,测试环境问题排查的一些经验。
相对于线上环境,测试环境的问题往往更为复杂,主要有以下几个方面的原因:
环境组成的复杂性。转转的测试环境,是由一套基础的稳定环境,和若干套动态环境组成的。动态环境部署需求涉及变更的服务,而稳定环境提供给所有动态环境共同调用。如下:
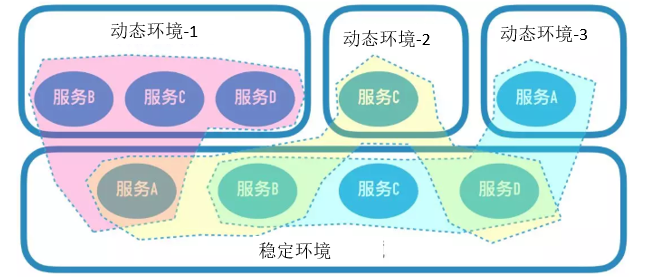
在多个项目并行的情况下,同一个服务,会在测试环境同时部署多个不同的版本;稳定环境的同一个服务,会根据上游环境的不同,调用不同的下游服务节点。
由上可见,测试环境链路拓扑的复杂性,远远高于线上环境。
服务器性能差。转转的测试环境组成,是基于运维同学自研KVM的虚拟化系统。测试环境服务器本身相对于线上服务器性能更差,再加上长时间高负荷运转,出现故障的概率也更大。
服务稳定性差。部署在测试环境的服务,大多仍处在开发、联调、测试的流程中,服务可能会存在更多的Bug,稳定性较差。
笔者将常见的问题原因,分为了以下几类:
机器问题:比如测试环境虚拟机的负载过高、内存不足、磁盘空间不足、宿主机IO过高等等,经常会造成服务启动失败、响应超时等。在大的项目,部署服务较多时,这类问题经常出现。像Linux内核的OOM Killer机制,就经常造成服务的意外终止,不了解的话往往会令人非常困惑。
外部依赖问题:
比如数据库连接是否正常、是否有对应数据库的权限、连接池大小设置是否合理等。
比如外部服务异常,包括调用的业务方服务、缓存、公共服务等。微服务架构下,服务调用关系错综复杂,一个关键服务的异常,往往会引发一串连锁反应。
再比如node版本不正确。前端服务,不同的node版本间,差异还是比较大的,需要提前确认清楚。
服务自身问题:测试环境部署的代码,很可能是未经测试,甚至是没有经过调试和自测的。因此,服务本身出现问题的概率也非常大。常见的比如代码逻辑问题、配置不正确、pom文件依赖冲突等等。
细心的读者可能已经发现,上述的很多问题,其实是会反复出现的。对于这类问题,我们首先想到的,应该是:这个问题为什么会重复出现?有没有什么办法能够彻底解决?比如是不是系统有Bug?是不是流程不合理?是不是缺乏规范?如果能够彻底解决,就应该采取相应的措施,彻底解决问题,避免再次出现,而不是等问题出现了再去查找之前的文档。
比如前面提到的机器问题,我们可以对机器的资源进行监控、对部署的服务进行限制等,避免出现负载、使用率过高的问题;
比如依赖问题,我们可以通过对服务可用性的监控,及时发现并处理,避免在调用时才发现问题,影响项目进度;
而一些配置、规范类的问题,则可以制定并推动规范的落地,在编译或者部署阶段,增加相应的校验,将问题尽早暴露出来。问题发现的越早,解决的成本越低;
解决了这些重复性的问题,剩下的就是一些个性化的问题了,只能挨个排查。接下来就说说问题排查的一些思路和方法。
1、分析思路
历史问题回归
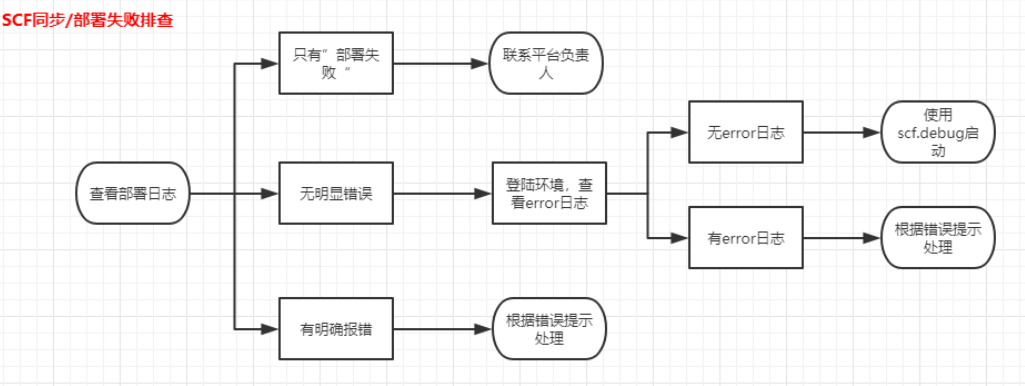
古人云:“鉴以往而知未来”,遇到的很多问题,往往能从之前的经验中找到灵感。针对这类问题,如果能够有效检索历史问题,能够极大缩短问题排查的时间,提高解决效率。这就要求我们在日常的工作中,对于遇到的问题进行详尽的记录,便于日后查找。甚至可以基于这些常见问题,形成一套排查流程,类似下面这样:
变量对比
类似测试方法论中的“单一变量法”,遇到了问题,做一下变量的对比分析。
比如发生了“Class Not Found Exception”,可以看看最近有没有改动过pom,是否遗漏了jar包或者引发了jar包冲突;
比如某个分支的服务一直异常,那么可以同步下线上版本,确认下是否是该服务分支的问题,再做进一步分析;
比如某个方法或接口响应很慢,那么同一服务的其他接口也慢吗?是服务的问题还是接口逻辑的问题?等等
日志分析
在问题排查过程中,日志的价值是极其巨大的。应该养成好的习惯,出现问题,第一反应应该就是查看日志。这里的日志,不仅仅包括服务本身的日志输出,还包括环境管理平台的日志、JVM日志、GC日志等。以下日志分析中的一些小建议:
异常日志,要学会定位到异常发生的起点,确定根本原因;
不要放过任何一行日志,有些关键信息往往隐藏在不起眼的地方;
关注JVM日志,尤其是服务启动失败的情况,常常有意外的惊喜;
学会手动添加GC日志配置,对于分析GC相关问题非常有帮助;
远程Debug
对于个别问题,本地环境难以复现,又没有明显的线索,远程debug是排查的一个简单有效的手段。熟练运用IDE进行远程debug配置,是一个必备手段,这里就不赘述了。
2、排查工具
工欲善其事,必先利其器。借助于合适的工具,不仅能够极大的提升排查问题的效率,还能防患于未然,及时发现环境中的问题,避免一些异常的产生。在转转测试环境管理中,主要用的的工具和平台有以下几种:
环境管理平台Agent。在之前分享的文章《转转测试环境平台解决方案》中提到过,转转的测试环境管理平台,是一个典型的master-slave分布式结构,每个测试环境上都部署有平台的agent。Agent除了负责环境管理、服务部署等功能,还提供对环境的监控和报警功能,包括环境的内存使用、CPU负载、磁盘使用、服务状态等。前文提到的机器问题,大多可以通过监控及时发现并处理;
服务管理平台。架构部提供的服务治理平台,能够对微服务的服务方进行全方位的监控,包括服务状态、节点信息、函数的流量、耗时统计等等;
zzmonitor——立体化监控平台。提供对服务的个性化监控,包括服务端口的探活、JVM监控(GC/Thread/Mem)等。通过服务管理平台和zzmonitor强大的监控和报警能力,能够对服务的状态、性能等异常情况,实时发送报警,便于及时发现服务自身问题,也能避免前文提到的相关依赖服务的异常;
天网、zzapm。这两个平台可以提供强大的服务拓扑和链路追踪的功能,对于定位调用异常、接口性能等问题,有非常大的帮助;
通用工具。常见的JDK工具,比如jps、jstat、jmap、jstack等;Arthas 是Alibaba开源的Java诊断工具,功能非常强大;
案例一 问题:测试环境一个查询商品列表的接口,响应非常慢,经常超时。
排查过程:
Step 1:查看服务管理平台。服务状态正常,接口耗时统计中,部分接口耗时正常,个别接口超时严重,如下:
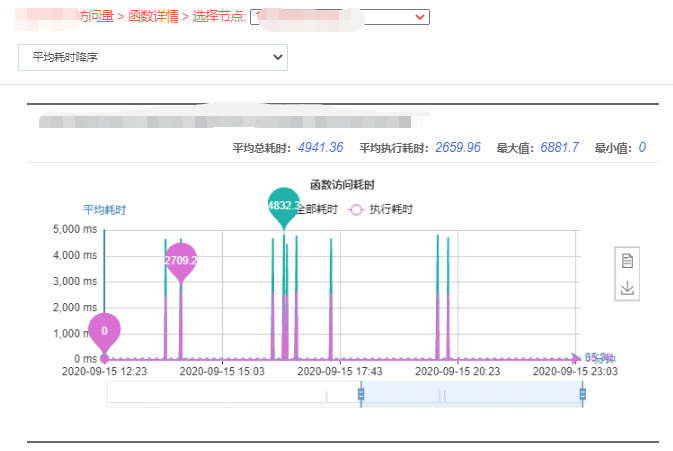
注:图片仅供参考,图中数据不一定与案例的数据对应,下同
Step 2:查看该服务的日志,有如下报错,初步定位为服务数据库连接池不足;

Step 3:通过zzapm,对超时的调用链路进行追踪,发现在“getConnection()”环节耗时非常严重;
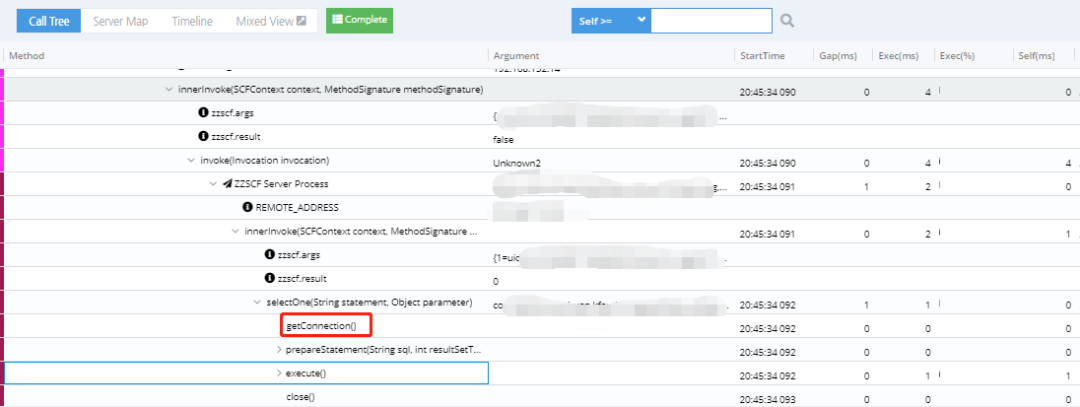
Step 4:确认服务的数据库配置,设置的连接池大小为5~10,而该服务是一个基础服务,调用量非常大,因此连接池长时间被占满,导致大量调用在等待连接池释放,而造成超时;
Step 5:修改服务的连接池配置,重启后恢复正常;
总结:这个案例充分展示了合理使用工具的重要性。通过服务管理平台,能够快速确认服务是正常的,问题在于部分接口;通过zzapm强大的调用链追踪能力,能准确定位到耗时的节点,确定问题原因。
案例二 问题:某RPC服务,部署后启动失败。
排查过程:
Step 1:查看服务进程,发现进程不存在;查看服务日志,发现没有生成日志;
Step 2:查看Java虚拟机日志,发现在日志中间有一条异常输出,表明服务的端口被占用了;
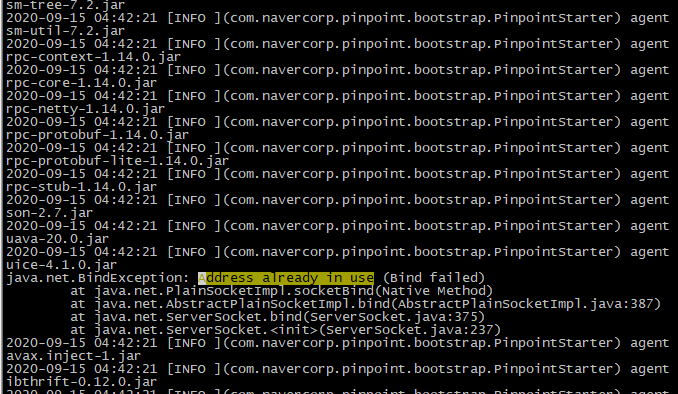
Step 3:查看服务端口配置,再通过ps、netstat等命令,确认该服务的监听端口被另一个服务的连接端口占用;
Step 4:重启占用方服务,待端口释放后,再重启问题服务,恢复正常;
总结:端口冲突的问题,曾经在测试环境频繁出现,给我们制造了很多麻烦。通过在排查过程中不断分析和总结,我们确定了问题的根本原因在于端口使用的不规范。进而制定并推广了服务端口的分配规范,只允许使用指定范围内的监听端口,并在测试环境中对这些端口进行了预留,从而彻底解决了这一问题。
整体来说,测试环境的问题繁琐而复杂,排查起来是一个劳心劳力的过程。这就需要我们在排查过程中多思考、多总结,形成一套完善的方法和流程,合理地使用各种工具,进而提高排查问题的效率。
在这个过程中,我们始终不应忘记自己的最终目的。一方面,作为测试人员,不能放过测试过程中的一丝异常,每一个问题都要排查出产生的根本原因。在线下它只是个bug,一旦漏到了线上,就可能造成一次事故。另一方面,作为测试环境的管理者,我们要经常去思考,能否通过功能的改进、流程的完善,避免同样的问题再次出现,将问题扼杀在摇篮之中。
此外,笔者一直有一个想法。既然我们能够根据经验,总结出一套问题排查的方法论和排查流程,那么,是否能将这个过程自动化、智能化,让平台来完成排查的过程,进一步节约成本,提高排查效率?这将是笔者未来努力探索的一个方向。
道阻且长,行则将至。与诸君共勉。
