
后悔!我早该把这1W字详解的 InnoDB 原理给你!
点击上方蓝色“小哈学Java”,选择“设为星标”
回复“资源”获取独家整理的学习资料!


来源:r6d.cn/Q8tM
1、InnoDB 架构
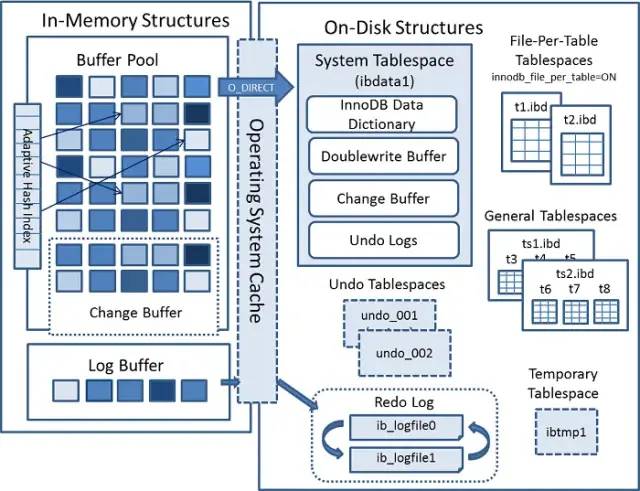
2、InnoDB 内存中的结构
Buffer Pool
show engine innodb status 命令查看。其中一些主要信息如下:----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992 # 分配给InnoDB缓存池的内存(字节)
Dictionary memory allocated 102398 # 分配给InnoDB数据字典的内存(字节)
Buffer pool size 8191 # 缓存池的页数目
Free buffers 7893 # 缓存池空闲链表的页数目
Database pages 298 # 缓存池LRU链表的页数目
Modified db pages 0 # 修改过的页数目
......
Change Buffer
innodb_change_buffering 配置是否缓存辅助索引页的修改,默认为 all,即缓存 insert/delete-mark/purge 操作(注:MySQL 删除数据通常分为两步,第一步是delete-mark,即只标记,而purge才是真正的删除数据)。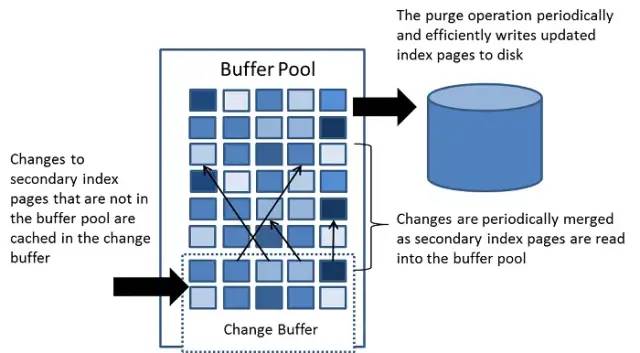
show engine innodb status 命令。更多信息见-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Adaptive Hash Index
innodb_adaptive_hash_index 开启,MySQL5.7 默认开启。innodb_adaptive_hash_index_parts配置分区数目,默认是8个,如前一节命令列出所示。Log Buffer
innodb_log_buffer_size 定义,默认是 16M。一个大的 Log Buffer可以让大事务在提交前不必将日志中途刷到磁盘,可以提高效率。如果你的系统有很多修改很多行记录的大事务,可以增大该值。innodb_flush_log_at_trx_commit 用于控制 Log Buffer 如何写入和刷到磁盘。注意,除了 MySQL 的缓冲区,操作系统本身也有内核缓冲区。默认为1,表示每次事务提交都会将 Log Buffer 写入操作系统缓存,并调用配置的 “flush” 方法将数据写到磁盘。 设置为 1 因为频繁刷磁盘效率会偏低,但是安全性高,最多丢失 1个 事务数据。 而设置为 0 和 2 则可能丢失 1秒以上 的事务数据。 为 0 则表示每秒才将 Log Buffer 写入内核缓冲区并调用 “flush” 方法将数据写到磁盘。 为 2 则是每次事务提交都将 Log Buffer写入内核缓冲区,但是每秒才调用 “flush” 将内核缓冲区的数据刷到磁盘。
innodb_flush_log_at_timeout 可以配置刷新日志缓存到磁盘的频率,默认是1秒。注意刷磁盘的频率并不保证就正好是这个时间,可能因为MySQL的一些操作导致推迟或提前。3、InnoDB 磁盘上的结构
表空间: 分为系统表空间(MySQL 目录的 ibdata1 文件),临时表空间,常规表空间,Undo 表空间以及 file-per-table 表空间(MySQL5.7默认打开file_per_table 配置)。 系统表空间又包括了InnoDB数据字典,双写缓冲区(Doublewrite Buffer),修改缓存(Change Buffer),Undo日志等。 Redo日志: 存储的就是 Log Buffer 刷到磁盘的数据。
mysql> create database test;
mysql> use test;
mysql> create table t (id int auto_increment primary key, ch varchar(5000));
mysql> insert into t (ch) values('abc');
mysql> insert into t (ch) values('defgh');
3.1 InnoDB 表结构
ROW_FORMAT 指定行记录格式,默认是 DYNAMIC。可以通过命令 SHOW TABLE STATUS 查看表信息,此外,也可使用 SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test/t' 查看。mysql> SHOW TABLE STATUS FROM test LIKE 't' \G
*************************** 1. row ***************************
Name: t
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 2
Avg_row_length: 8192
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 3
Create_time: 2019-01-13 02:24:52
Update_time: 2019-01-13 02:28:16
Check_time: NULL
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
3.2 InnoDB 表空间概述
系统表空间: 包含内容有数据字典,双写缓冲,修改缓冲以及undo日志,以及在系统表空间创建的表的数据和索引。 常规表空间: 类似系统表空间,也是一种共享的表空间,可以通过 CREATE TABLESPACE创建常规表空间,多个表可共享一个常规表空间,也可以修改表的表空间。
CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1;
CREATE TABLE t2 (c2 INT PRIMARY KEY) TABLESPACE ts1;
ALTER TABLE t2 TABLESPACE=innodb_file_per_table;
DROP TABLE t1;
DROP TABLESPACE ts1;
File-Per-Table表空间: MySQL InnoDB新版本提供了 innodb_file_per_table 选项,每个表可以有单独的表空间数据文件(.ibd),而不是全部放到系统表空间数据文件 ibdata1 中。 在 MySQL5.7 中该选项默认开启。 其他表空间: 其他表空间中Undo表空间存储的是Undo日志。 除了存储在系统表空间外,Undo日志也可以存储在单独的Undo表空间中。 临时表空间则是非压缩的临时表的存储空间,默认是数据目录的 ibtmp1 文件,所有临时表共享,压缩的临时表用的是 File-Per-Table 表空间。
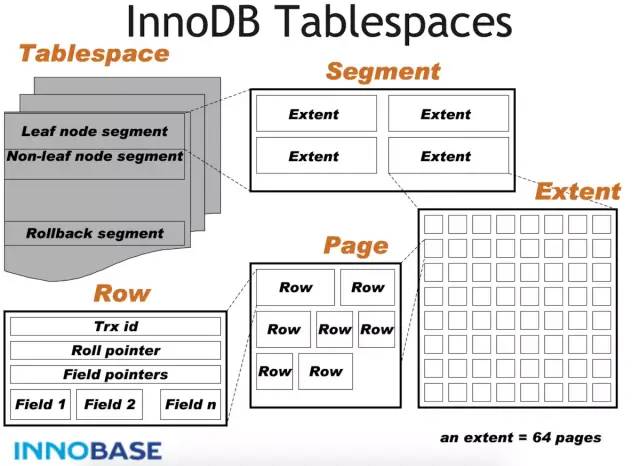
段(Segment)分为索引段,数据段,回滚段等。其中索引段就是非叶子结点部分,而数据段就是叶子结点部分,回滚段用于数据的回滚和多版本控制。一个段包含256个区(256M大小)。 区是页的集合,一个区包含64个连续的页,默认大小为 1MB (64*16K)。 页是 InnoDB 管理的最小单位,常见的有 FSP_HDR,INODE, INDEX 等类型。所有页的结构都是一样的,分为文件头(前38字节),页数据和文件尾(后8字节)。页数据根据页的类型不同而不一样。 FILE_SPACE_HEADER 页:用于存储区的元信息。ibd文件的第一页 FSP_HDR 页通常就用于存储区的元信息,里面的256个 XDES(extent descriptors) 项存储了256个区的元信息,包括区的使用情况和区里面页的使用情况。 IBUF_BITMAP 页:用于记录 change buffer的使用情况。 INODE 页:用于记录文件段(FSEG)的信息,每页有85个INODE entry,每个INODE entry占用192字节,用于描述一个文件段。每个INODE entry包括文件段ID、属于该段的区的信息以及碎片页数组。区信息包括 FREE(完全空闲的区), NOT_FULL(至少使用了一个页的区), FULL(没空闲页的区)三种类型的区的List Base Node(包含链表长度和头尾页号和偏移的结构体)。碎片页数组则是不同于分配整个区的单独分配的32个页。 INDEX 页:索引页的叶子结点的data就是数据,如聚集索引存储的行数据,辅助索引存储的主键值。
3.3 InnoDB File-Per-Table表空间
优点: 可以方便回收删除表所占的磁盘空间。 如果使用系统表空间的话,删除表后空闲空间只能被 InnoDB 数据使用。 TRUNCATE TABLE 操作会更快。 可以单独拷贝表空间数据到其他数据库(使用 transportable tablespace 特性),可以更方便的观测每个表空间数据的大小。 缺点: fsync 操作需要作用的多个表空间文件,比只对系统表空间这一个文件进行fsync操作会多一些 IO 操作。 此外,mysqld需要维护更多的文件描述符。
表空间文件结构
innodb_page_size 配置为 4K, 8K…64K 等。在ibd文件中,0-16KB偏移量即为0号数据页,16KB-32KB的为1号数据页,以此类推。页的头尾除了一些元信息外,还有Checksum校验值,这些校验值在写入磁盘前计算得到,当从磁盘中读取时,重新计算校验值并与数据页中存储的对比,如果发现不同,则会导致 MySQL 崩溃。
第0页是 FSP_HDR 页,主要用于跟踪表空间,空闲链表、碎片页以及区等信息。 第1页是 IBUF_BITMAP 页,保存Change Buffer的位图。 第2页是 INODE 页,用于存储区和单独分配的碎片页信息,包括FULL、FREE、NOT_FULL 等页列表的基础结点信息(基础结点信息记录了列表的起始和结束页号和偏移等),这些结点指向的是 FSP_HDR 页中的项,用于记录页的使用情况,它们之间关系如下图所示。 第3页开始是索引页 INDEX(B-tree node),从 0xc000(每页16K) 开始,后面还有些分配的未使用的页。
innodb_sys_tables 表中查到表t的表空间ID为28,然后可以在 innodb_buffer_page查到所有页信息,一共4个页。分别是 FSP_HDR, IBUF_BITMAP, INODE, INDEX。select * from information_schema.innodb_sys_tables where name='test/t';
select * from information_schema.innodb_buffer_page where SPACE=28;
索引页分析

# hexdump -C t.ibd
0000c000 95 45 82 8a 00 00 00 03 ff ff ff ff ff ff ff ff |.E..............|
0000c010 00 00 00 00 00 28 85 7c 45 bf 00 00 00 00 00 00 |.....(.|E.......|
0000c020 00 00 00 00 00 1c 00 02 00 b0 80 04 00 00 00 00 |................|
0000c030 00 9a 00 02 00 01 00 02 00 00 00 00 00 00 00 00 |................|
0000c040 00 00 00 00 00 00 00 00 00 2f 00 00 00 1c 00 00 |........./......|
0000c050 00 02 00 f2 00 00 00 1c 00 00 00 02 00 32 01 00 |.............2..|
0000c060 02 00 1c 69 6e 66 69 6d 75 6d 00 03 00 0b 00 00 |...infimum......|
0000c070 73 75 70 72 65 6d 75 6d 03 00 00 00 10 00 1b 80 |supremum........|
0000c080 00 00 01 00 00 00 00 05 68 d1 00 00 01 54 01 10 |........h....T..|
0000c090 61 62 63 05 00 00 00 18 ff d6 80 00 00 02 00 00 |abc.............|
0000c0a0 00 00 05 69 d2 00 00 01 55 01 10 64 65 66 67 68 |...i....U..defgh|
0000c0b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000fff0 00 00 00 00 00 70 00 63 95 45 82 8a 00 28 85 7c |.....p.c.E...(.||
00010000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
FIL Header(38字节): 记录文件头信息。前4字节 95 45 82 8a是 checksum,接着00 00 00 03是页偏移值 3,即这是第3页。接着 4 字节是上一页偏移值,因为只有一个数据页,所以这里为ff ff ff ff,接着 4 字节是下一页偏移值ff ff ff ff。然后 8 字节00 00 00 00 00 28 85 7c 是日志序列号 LSN。随后的 2 字节45 bf是页类型,代表是 INDEX 页。接着 8 字节00 00 00 00 00 00 00 00表示被更新到的LSN,在 File-Per-Table 表空间中都是0。然后 4 字节00 00 00 1c` 表示该数据页属于的表t的表空间ID是 0x1c(28)。INDEX Header(36字节): 记录的是 INDEX 页的状态信息。前2字节 00 02 表示页目录的 slot 数目为2;接着2字节 00 b0 是页中第一个记录的指针。80 04是这页的格式为DYNAMIC和记录数4(包括2条System Records我们插入的2条记录)。接着 00 00是可重用空间首指针,再后面2字节00 00是已删除记录数;00 9a是最后插入记录的位置偏移,即最后插入位置是 0xc09a,即第2条记录开始地址。00 02 是最后插入的方向,2 表示 PAGE_DIRECTION_RIGHT,即自增长方式插入。00 01 指一个方向连续插入的数量,这里为1。接着的00 02是 INDEX 页中的真实记录数,我们只有2条记录。然后8字节00…00为修改该页的最大事务ID,这个值只在辅助索引中存在,这里为0。接着2字节00 00为页在索引树的层级,0表示叶子结点。最后8个字节 00…2f为索引ID 47(索引ID可以在information_schema.INNODB_SYS_INDEXES 中查询,可以确认 47 正好是表 t 的主索引)。 FSEG Header:这是INDEX页中的根结点才有的,非根结点的为0。前10字节 00 00 00 1c 00 00 00 02 00 f2 是叶子结点所在段的segment header,分别记录了叶子结点的表空间ID 0x1c,INODE页的页号 2 和 INODE项偏移 0xf2。而后10字节 00 00 00 1c 00 00 00 02 00 32 是非叶子结点所在段的segment header,偏移分别是0xf2 和 0x32,即INODE页的前2个Entry,文件段ID分别是1和2。FSEG Header中存储了该 INDEX 页的INODE项,INODE项里面则记录了该页存储所在的文件段以及文件段页的使用情况。对于 File-Per-Table情况下,每个单独的表空间文件的 FSP_HDR 页负责管理页使用情况。

System Records(26字节): 每个 INDEX 页都有两条虚拟记录 infimum 和 supremum,用于限定记录的边界,各占 13 个字节。其中记录头的5个字节分别标识了拥有记录的数目和类型(拥有记录数目是即后面页目录部分的owned值,当前页目录只有两个槽,infimum拥有记录数只有它自己为1,而supremum拥有我们插入的2条记录和它自己,故为3)、下一条记录的偏移 0x1c,即位置是 0xc07f,这就是我们实际记录开始位置。后面8个字节为 infimum + 空值,supremum类似,只是它下一条记录偏移为0。 01 00 02 00 1c 69 6e 66 69 6d 75 6d 00 # infimum
03 00 0b 00 00 73 75 70 72 65 6d 75 6d # supermumUser Records: 接下来是2条我们插入的记录。第1条记录前面7字节是记录头(Record Header),其中前面的 1字节记录的是可变变量的长度03,因为我们记录中c的值是 abc。然后1字节记录的是可为NULL的变量是否是NULL,这里不为 NULL,故为0。接着的5字节记录了插入顺序2(infimum插入顺序固定是0,supremum插入顺序是1,其他记录则是从2开始),下一个记录的偏移 0x1b(即下一个记录开始位置是0xc078+0x1b=0xc093),删除标记等。后面就是记录内容。第2条记录同理。这里的事务ID可以通过 select * from information_schema.innodb_trx 进行验证。
03 00 00 00 10 00 1b # 记录头
80 00 00 01 # 主键值1
00 00 00 00 05 68 # 事务ID
d1 00 00 01 54 01 10 # 回滚指针
61 62 63 # ch的值 abc
05 00 00 00 18 ff d6 # 第2条记录头
80 00 00 02 # 主键值2
00 00 00 00 05 69 # 事务ID
d2 00 00 01 55 01 10 # 回滚指针
64 65 66 67 68 # ch的值 defgh
Page Directory(4字节):因为页目录的slot只有2个,每个slot占2字节,故页目录为 00 70 00 63 这4字节,存储的是相对于最初行的位置。其中 0xc063 正好是 infimum 记录的开始位置,而 0xc070 正好是 supremum 记录的开始位置。使用页目录进行二分查找,可以加速查询,详细见后面分析。 FIL Tail (8字节): 最后8字节为 95 45 82 8a 00 28 85 7c,其中 95 45 82 8a 为 checknum,跟 FIL Header的checksum一样。后4字节00 28 85 7c 与 FIL Header的LSN的后4个字节一致。
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 -T test/t space-page-type-regions
start end count type
0 0 1 FSP_HDR
1 1 1 IBUF_BITMAP
2 2 1 INODE
3 3 1 INDEX
4 5 2 FREE (ALLOCATED)
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 -T test/t -p 3 page-records
Record 127: (id=1) → (ch="abc")
Record 154: (id=2) → (ch="defgh")
索引结构

mysql> create table t2(id int auto_increment primary key, ch varchar(10), key(ch));
mysql> insert into t2(ch) values('ab');
对比表t,表t2多一个INDEX页,用于存储辅助索引的根结点。 辅助索引的INDEX页也有两个系统记录 infimum 和 supremum。 而用户记录内容格式跟前面分析基本一致,内容为辅助索引 ch 列的值 ab 和 主键值1。
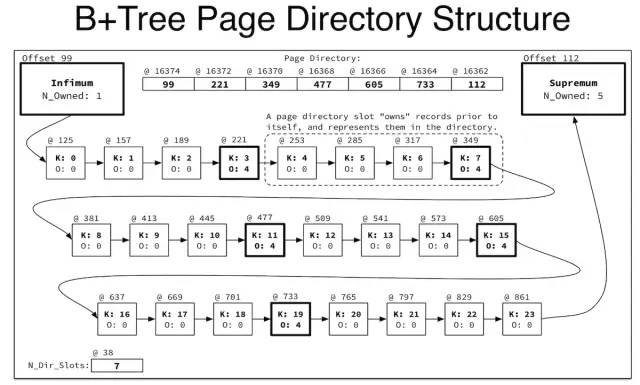
页目录
slot offset type owned key
0 99 infimum 1
1 112 supremum 3
slot offset type owned key
0 99 infimum 1
1 207 conventional 4 (i=4)
2 112 supremum 5
3.4 InnoDB 系统表空间
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1 space-page-type-summary
type count percent description
ALLOCATED 427 55.60 Freshly allocated
UNDO_LOG 125 16.28 Undo log
SYS 110 14.32 System internal
INDEX 71 9.24 B+Tree index
INODE 11 1.43 File segment inode
FSP_HDR 9 1.17 File space header
IBUF_BITMAP 8 1.04 Insert buffer bitmap
BLOB 5 0.65 Uncompressed BLOB
TRX_SYS 2 0.26 Transaction system header
Undo 日志

CREATE TABLE `t3` (
`id` int(11) NOT NULL,
`a` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into t3 values(1, 'A');
update t3 set a='B' where id=1;
update t3 set a='C' where id=1;
root@stretch:/var/lib/mysql# innodb_space -s ibdata1 -T test/t3 -p 3 -R 127 record-history
Transaction Type Undo record
(n/a) insert (id=1) → ()
root@stretch:/var/lib/mysql# innodb_space -s ibdata1 -T test/t3 -p 3 -R 127 record-history
Transaction Type Undo record
2333 update_existing (id=1) → (a="B")
2330 update_existing (id=1) → (a="A")
(n/a) insert (id=1) → ()
双写缓冲
4、InnoDB 事务隔离级别
Read Uncommitted: 未提交读也称为脏读,它读取的是当前最新修改的记录,即便这个修改最后并未生效。 Read Committed: 提交读。 它基于的是当前事务内的语句开始执行时的最大的事务ID。 如果其他事务修改同一个记录,在没有提交前,则该语句读取的记录还是不会变。 但是这种情况会产生不可重复读,即一个事务内多次读取同一条记录可能得到不同的结果(该记录被其他事务修改并提交了)。 Repeatable Read: 可重复读。 它基于的是事务开始时的读视图,直到事务结束。 不读取其他新的事务对该记录的修改,保证同一个事务内的可重复读取。 InnoDB提供了 next-key lock来解决幻读问题,不过在一些特殊场景下,可重复读还是可能出现幻读的情况。 在实际开发中影响不大,就不赘述了。
5、InnoDB 和 ACID 模型
Atomicity
COMMIT 和 ROLLBACK 语句(通过 Undo Log实现)。
Consistency
InnoDB 的故障恢复机制(crash recovery)。
Isolation
innodb的隔离性也是主要通过事务机制实现,特别是为事务提供的多种隔离级别,相关特性包括:
Autocommit设置。 SET ISOLATION LEVEL 语句。 InnoDB 锁机制。
Durability
Redo log。 双写缓冲功能。 可以通过配置项 innodb_doublewrite 开启或者关闭。 配置 innodb_flush_log_at_trx_commit。 用于配置innodb如何写入和刷新 redo 日志缓存到磁盘。 默认为1,表示每次事务提交都会将日志缓存写入并刷到磁盘。 innodb_flush_log_at_timeout 可以配置刷新日志缓存到磁盘的频率,默认是1秒。 配置 sync_binlog。 用于设置同步 binlog 到磁盘的频率,为0表示禁止MySQL同步binlog到磁盘,binlog刷到磁盘的频率由操作系统决定,性能最好但是最不安全。 为1表示每次事务提交前同步到磁盘,性能最差但是最安全。 MySQL文档推荐是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置为 1。 操作系统的 fsync 系统调用。 UPS设备和备份策略等。
END
有热门推荐?
1. 重磅 ! Kubernetes 决定弃用 Docker!
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)

评论