
CHIP2021 | 医学对话临床发现阴阳性判别任务第一名方案开源
比赛简介
比赛名称:CHIP2021评测一: 医学对话临床发现阴阳性判别任务 测评任务:针对互联网在线问诊记录中的临床发现进行阴阳性的分类判别 测评链接:http://www.cips-chip.org.cn/2021/eval1
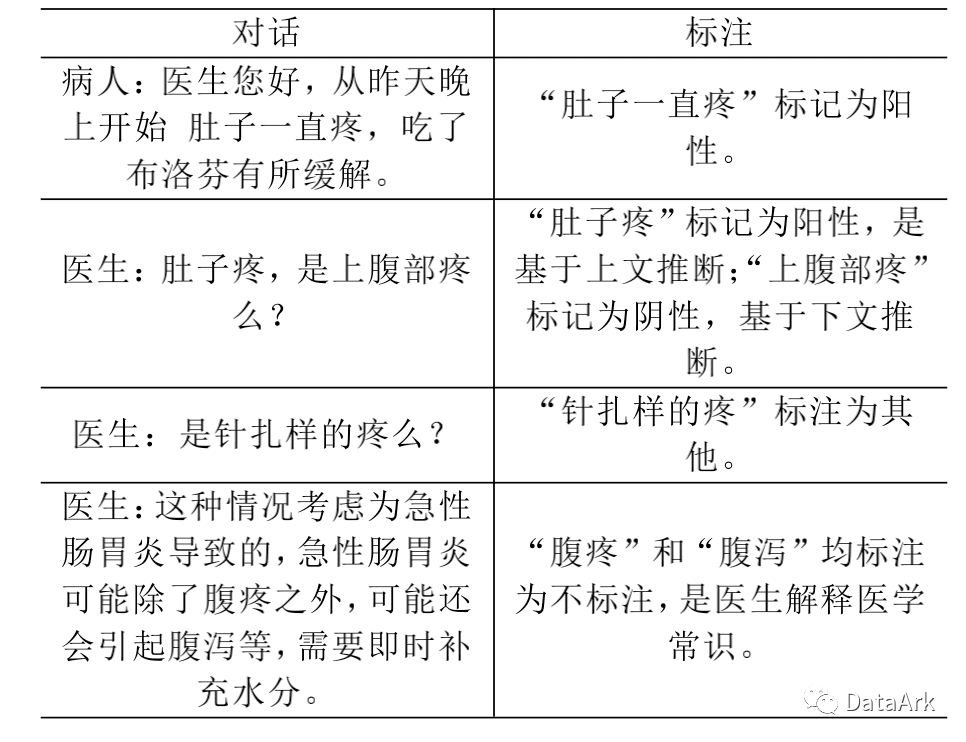
本次比赛可以视为针对实体的细颗粒情感分析任务,一共有阴性、阳性、其他、不标注四种标签。
阳性:已有症状疾/病等相关;医生诊断(包含多个诊断结论);假设未来可能发生的疾病等 阴性:未患有的疾病症状相关 其他:用户没有回答、不知道;回答不明确/模棱两可不好推断 不标注:无实际意义的不标注
任务难点与挑战
对话上下文信息的利用

标准词信息的引入

噪声和难判断样本
数据不平衡
方案总结
一、整体结构
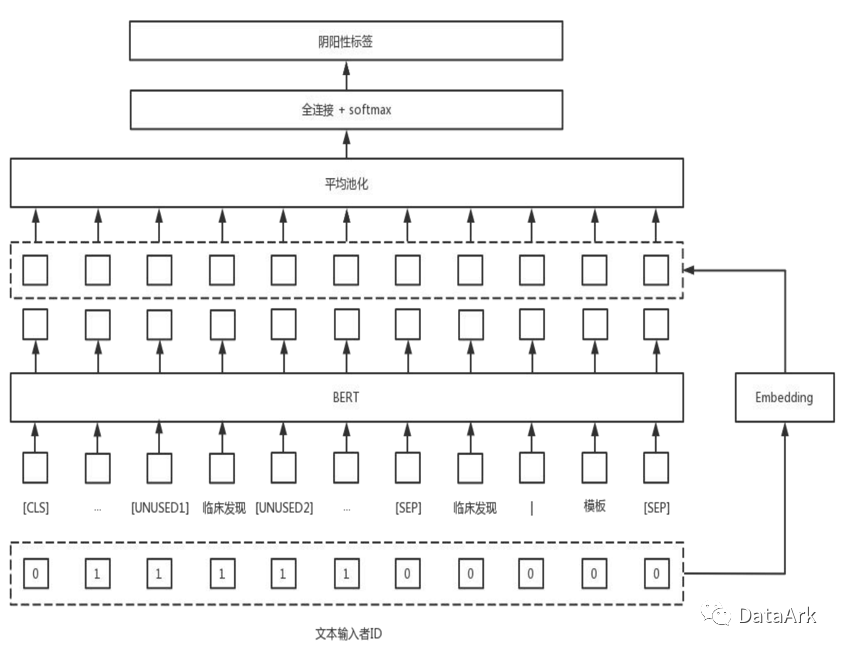
我们借鉴了R-BERT的思路在BERT的基础上,在需要判别阴阳性的临床发现实体两端分别加入[UNUSED1]和[UNUSED2]。针对标准化信息,我们通过构建标准词模版引入该部分的信息,具体构建方法如下:
临床发现词+“|标准化为”+标准名 临床发现词+“|没有标准化”
此外,我们使用输入者嵌入矩阵生成输入者,拼接在bert输出的向量中。
二、数据处理
上下文拼接
若文本的输入者为患者,则在文本前拼接“患者:” 若文本的输入者为医生,则在文本前拼接“医生:” 若当前临床发现词所在的文本是医生输入,则拼接三轮下文患者输入的文本; 若是患者输入,则不区分下文输入者信息,直接拼接三轮下文输入文本 拼接文本的长度为小于40个字符的一轮上文文本 截断选择
以临床发现词为核心进行上下文截断
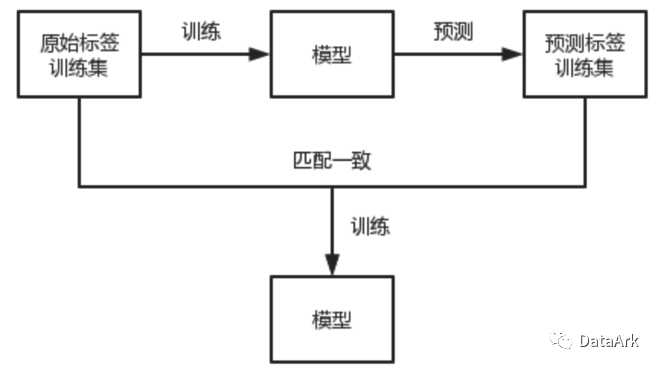
三、数据清洗
过滤与预测标签不一致的原始标签
任务预训练
四、模型集成
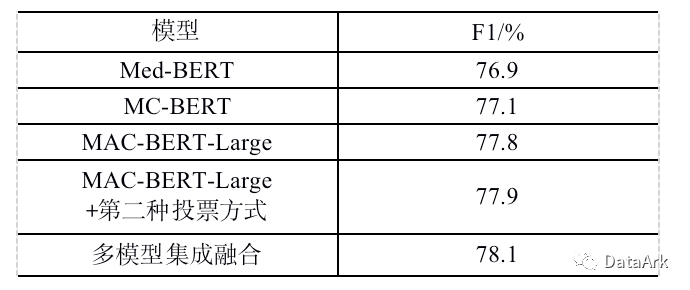
本次任务中,我们一共采用了MC-BERT、Med-BERT、MAC-BERT-Large和任务预训练后的MAC-BERT-Large四种预训练模型。针对每一种预训练模型我们使用10折交叉验证生成10个模型,并使用投票法集成输出结果。

除了正常的投票法外,针对其他和不标注两类标签召回少的问题,采用弱者投票机制,即十组投票结果中,若有2组以上的预测结果为“不标注”或“其他”,则忽略其他高票预测结果。
多模型融合则采用规则集成修正的方式进行融合。
五、其他Trick
EMA FGM
六、B榜结果
比赛总结
比赛已经结束,最终侥幸获得了第一名的成绩。很荣幸地受邀在CHIP2021线上会议上进行分享,也看到了其他选手精彩的方案。总体来说,Top方案之间的差距很小,我们更多还是靠一些小的细节trick取胜。本次比赛我们的代码是在自己的ark-nlp上进行开发和实验,后续我们也会继续对ark-nlp进行改进,收录更多的SOTA方式。此外,我们也将积极推动医疗知识图谱和医疗预训练模型的开发,也希望有兴趣的朋友可以加入我们。
ark-nlp地址:https://github.com/xiangking/ark-nlp 方案开源地址:https://github.com/DataArk/CHIP2021-Task1-Top1 MC-BERT torch版权重:医疗BERT | 中文生物医学文本挖掘的概念化表征学习
评论