
【神经网络搜索】Once for all
【GiantPandaCV导语】Once for all是韩松组非常有影响力的工作,其最大的优点是解耦了训练和搜索过程,可以直接从超网中采样出满足一定资源限制的子网,而不需要重新训练。该工作被ICLR20接收。
0. Info
Title: Once-for-All: Train one Network and Specialize it for Efficient Deployment
Author: 韩松组
Link: https://arxiv.org/pdf/1908.09791v5
Publish: ICLR2020
1. Motivation
传统网络搜索方法往往只能针对某个特定设备或者特定资源限制的平台进行针对性搜索。对于不同的设备,往往需要在该设备上从头训练。这样的方法扩展性很差并且计算代价太大,所以once for all从这个角度出发,希望能做到将训练和搜索过程解耦,从而可以训练一个支持不同架构配置的once-for-all网络(类似超网的概念),通过从once-for-all网络中选择一个子网,就可以在不需要额外训练的情况下得到一个专门的子网络。
不同的硬件平台有着不同的硬件效率限制,比如延迟、功耗 不同的硬件平台的硬件资源差别很大,比如最新的手机和最老的手机。 相同的硬件上,不同的电池条件、工作负载下使用的网络模型也是不同的。
也就是说,网络设计主要受平台的以下几方面约束:
部署的硬件设备不同。 相同硬件设备上不同的部署要求,比如期望的延迟。
2. Contribution
提出了解决以上问题的方法:设计once-for-all网络,可以在不同的网络配置下进行部署。 推理过程使用的模型是once-for-all网络的一部分,可以无需重新训练就能灵活的支持深度、宽度、卷积核大小、分辨率等参数的不同。 提出了渐进式收缩的训练策略来训练once-for-all网络
3. Method
方法部分需要搞清楚两个问题,一个是网络是什么样的?一个是网络是如何训练的?
第一个问题:once-for-all网络长什么样子?
once-for-all网络支持深度、宽度、卷积核大小、图像分辨率四个因素的变化。
elastic depth: 代表选择任意深度的网络,每个单元的深度有{2,3,4}三个选项。 elastic width: 代表选择任意数量的通道,宽度比例有{3,4,6}三个选项。 elastic kernel size: 代表选择任意的卷积核大小,有{3,5,7}三个选项。 arbitrary resolution: 代表图像的分辨率是可变的,从128到224,stride=4的分辨率均可。
由于网络包括5个单元,所以候选的子网大概有个不同的子网,并且是在25个不同输入分辨率下进行训练。所有的子网都共享权重,只需要7.7M的参数量。
第二个问题:once-for-all怎样才能同时训练这么多子网络?
由于once-for-all的目标是同时优化所有的子网,所以需要考虑使用新的训练策略。
最简单的想法:不考虑计算代价的情况下,每次梯度的更新都是由全体子网计算得到的。虽然这样最准确,但是可想而知计算代价过高,并不实际。 可行的想法:每次梯度是由一部分子网计算得到的。笔者曾经尝试过这种方法(single path one shot),收敛的速度非常慢,得到的准确率也非常低。这很可能是在训练过程中,由于权重是共享的,梯度在同一个参数的更新上可能带来冲突,减缓了训练的过程,并且达到最终的准确率也不够高。
通过以上分析可以看出,训练超网是非常困难的,需要采用更好的训练策略才能训练得动超网。
本文提出了Progressive Shrinking策略来解决以上问题,如下图所示:
先训练最大的kernel size, depth , width的网络 微调网络来支持子网,即将小型的子网加入采样空间中。比如说,当前正在微调kernel size的时候,其他的几个选项depth, width需要维持最大的值。另外,分辨率大小是每个batch随机采样的,类似于yolov3里的训练方法。 采用了知识蒸馏的方法,让最大的超网来指导子网的学习。

以上策略的特点是:先训练最大的,然后训练小的。这样可以尽可能减小训练小模型的时候对大模型的影响。
下面对照上图详细展开PS策略:
训练整个网络,最大kernel,最宽channel,最深depth 训练可变kernel size, 每次采样一个子网,使用0.96的初始学习率训练125个epoch 训练可变depth,采样两个子网,每次更新收集两者的梯度。第一个stage使用0.08的学习率训练25个epoch;使用0.24的学习率训练125个epoch。 训练可变width,采样四个子网,每次更新收集四个子网梯度。第一个stage使用0.08的学习率训练25个epoch;使用0.24的学习率训练125个epoch。
通过以上描述可以看出来,权重共享的网络优化起来非常复杂,上边的选择的子网个数、学习率的选择、epoch的选择可能背后作者进行了无数次尝试调参,才得到了一个比较好的结果。
**Elastic Kernel Size: **Kernel Size是如何共享的呢?
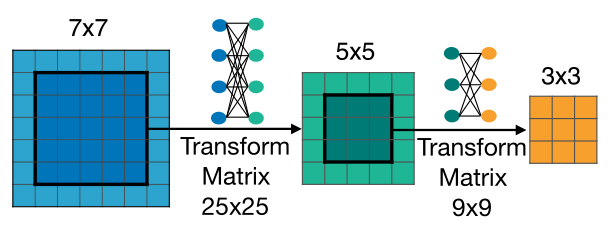
简单来说就是,中心共享+变换矩阵。从直觉上来讲,优化7x7的卷积核以后,再优化中间的5x5卷积核势必会影响原先7x7卷积核的结果,两者在分布和数值上有较大的不同,强制训练会导致性能有较大的下降,所以这就需要引入变换矩阵,具体实现是一个MLP,具体方法是:
不同层使用各自独立的变换矩阵来共享权重。 相同层内部,不同的通道之间共享变换矩阵。
Elastic Depth: 如何优化不同深度的网络呢?
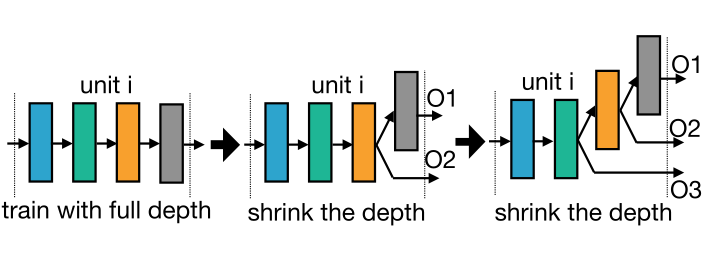
深度为2、3、4的时候,按照上图所示,选择前i个层,进行训练和优化。
**Elastic Width: ** 如何优化不同的通道个数?
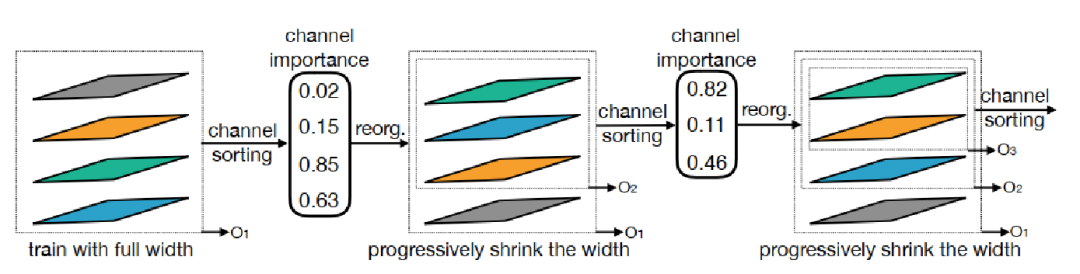
并没有使用类似slimmable network中那种选取前n个通道的策略,而是选取了一个channel importance进行排序,通道重要性计算方法是L1范数,L1范数越大,代表其重要性比较高,选择重要性最高的前n个通道。
部署阶段的其他技术细节:
搜索子网,满足一定的条件,比如延迟、功率等限制。 预测器:neural-network-twins, 功能是给定一个网络结构,预测其延迟和准确率。采样了16K个不同架构、不同分辨率的子网,然后再10K的验证数据集上得到他们真实的准确率。【arch, accuracy】可以作为准确率预测器的训练数据集。 构建了一个延迟查找表 latency lookup table来预测不同目标硬件平台的延迟。预测器训练数据集只需要40GPU Days。
4. Experiment
训练细节:
网络搜索空间:MobileNetV3类似的 使用标准的SGD优化器,momentum=0.9 weight decay=3e-5 初始学习率2.6 使用cosine schedule来进行learning rate decay 在32GPU上使用2048的batch size训练了180个epoch 在V100GPU上训练了1200个GPU hours
渐进收缩策略:
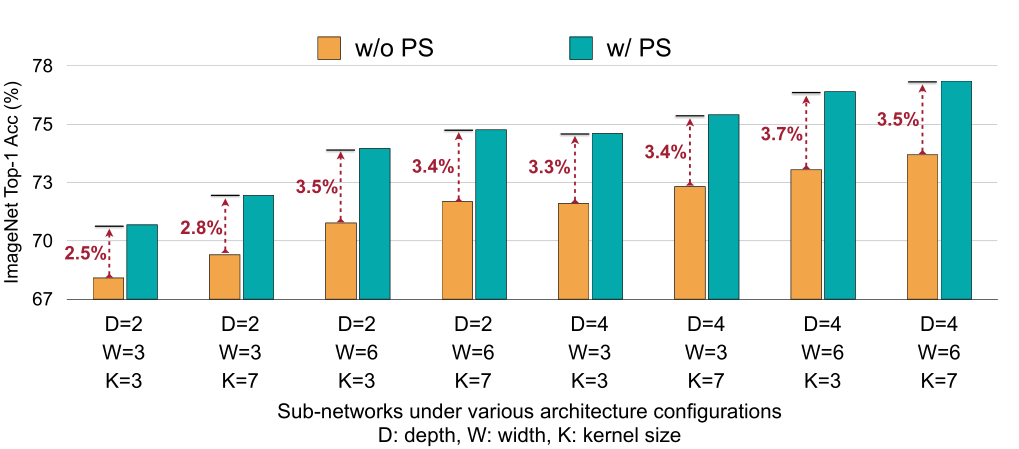
上图展示了使用渐进收缩策略以后带来的性能提升,可以看出,不同的架构配置下,都带来了2-4%的性能提升。
实验结果:
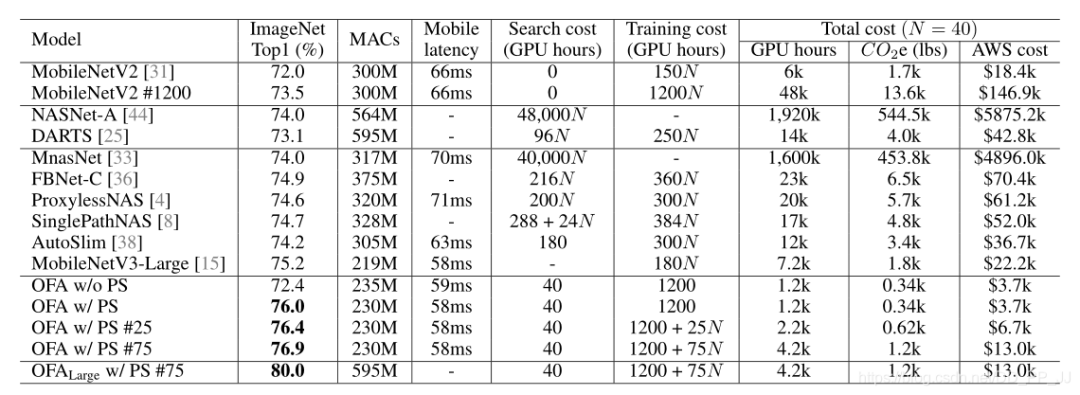
once-for-all在ImageNet上训练结果如上表所示,其中可以发现虽然训练代价比较高,但是搜索的代价稳定在40GPU Hours并且取得了相同量级MACs下不错结果。
5. Revisiting
并没有什么突破性的创新点,但是每个点都做得很扎实,在一个不错的motivation下,将故事讲的非常引人入胜。所以会讲故事+扎实的实验结果+(大量的算力) 才得到这个结果。 渐进收缩策略中先训练kernel size,在训练depth,最后训练width的顺序并没有明确指出为何是这样的顺序。 通道的搜索策略笔者把它搬到single path one shot上进行了实验,效果并不理想。 通道搜索策略中once for all计算L1 Norm是根据输入的通道来计算的,有点违背直觉,通常来讲根据输出通道计算更符合直觉一些。这一点可以参考通道剪枝,可能两种方法都是可行的,具体选哪个需要看实验结果。 共享kernel size那部分工作的分析非常好,想到使用一个转移矩阵来适应不同kernel所需要的分布非常符合直觉。 这篇工作代码量非常大,非常的工程化,从文章的实验也能看出里边需要非常强的工程能力,调参能力、才能在顶会上发表。
6. Reference
https://zhuanlan.zhihu.com/p/164695166
https://github.com/mit-han-lab/once-for-all
https://arxiv.org/abs/1908.09791
https://file.lzhu.me/projects/OnceForAll/OFA%20Slides.pdf
对文章有疑问或者研究NAS的同学可以添加笔者微信