
Apache老母鸡又下蛋?一文俯瞰Apache Superset



Superset简介
丰富的数据可视化集
易于使用的界面,用于浏览和可视化数据
创建和共享仪表板
与主要身份验证提供程序(数据库,OpenID,LDAP,OAuth和REMOTE_USER通过Flask AppBuilder集成)集成的企业就绪身份验证
可扩展的高粒度安全性/权限模型,允许有关谁可以访问单个要素和数据集的复杂规则
一个简单的语义层,允许用户通过定义哪些字段应显示在哪些下拉列表中以及哪些聚合和功能度量可供用户使用来控制如何在UI中显示数据源
通过SQLAlchemy与大多数说SQL的RDBMS集成
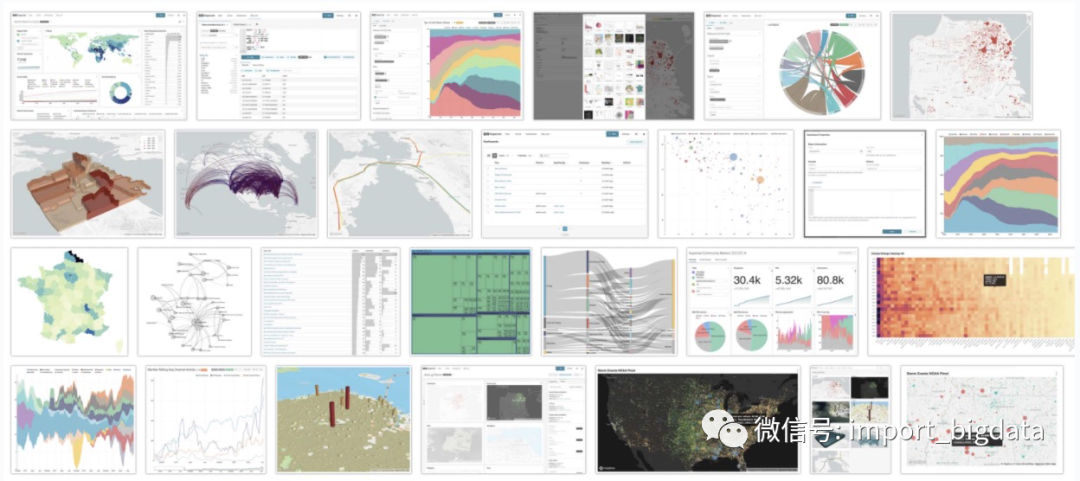
Superset丰富的数据源支持和图表展示

Superset极其简单的安装和配置
#安装
pip install superset
#创建管理员用户名和密码
fabmanager create-admin --app superset
#初始化
superset db upgrade
#装载样例数据
superset load_examples
#创建默认角色和权限
superset init
#启动
superset runserver
$ git clone https://github.com/apache/superset.git
$ cd superset
$ docker-compose up
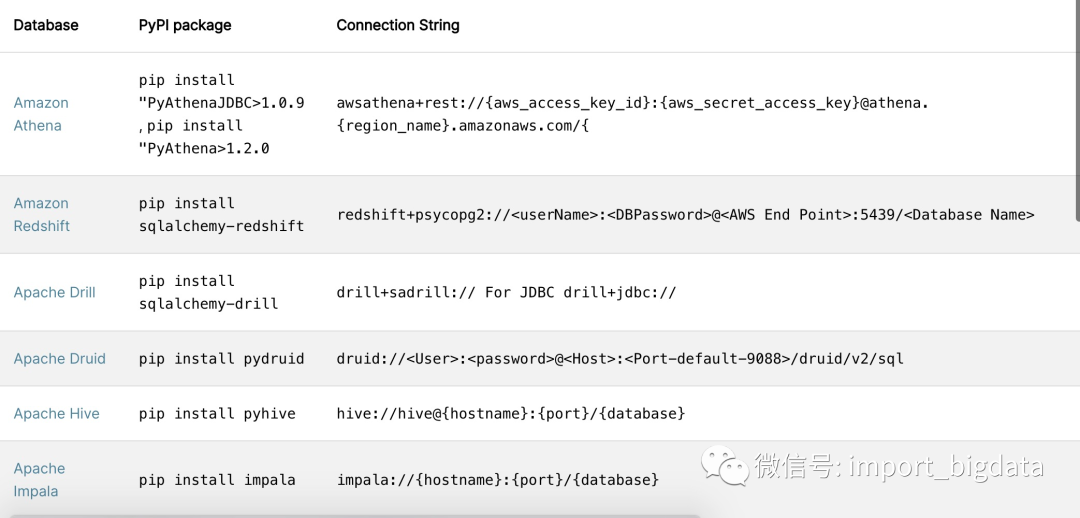
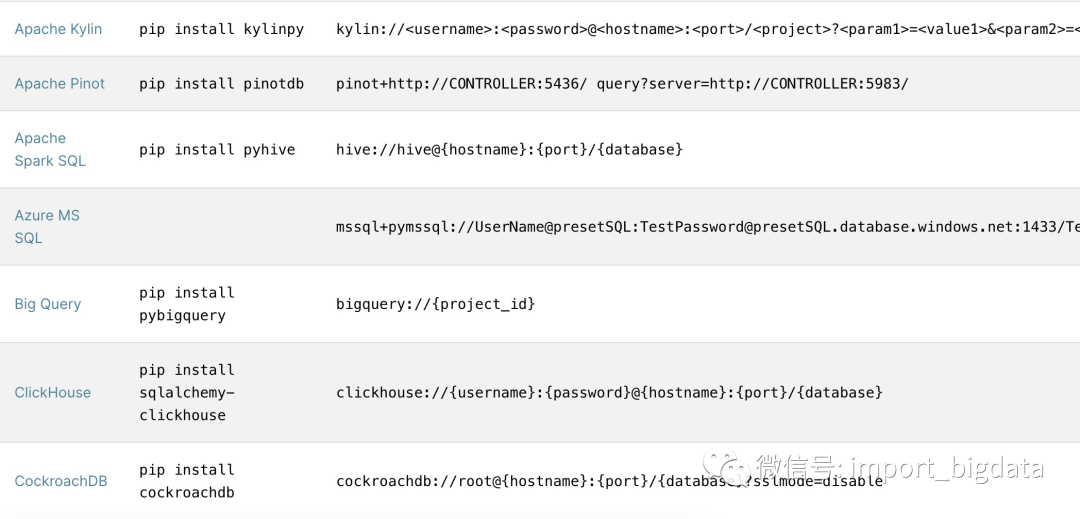
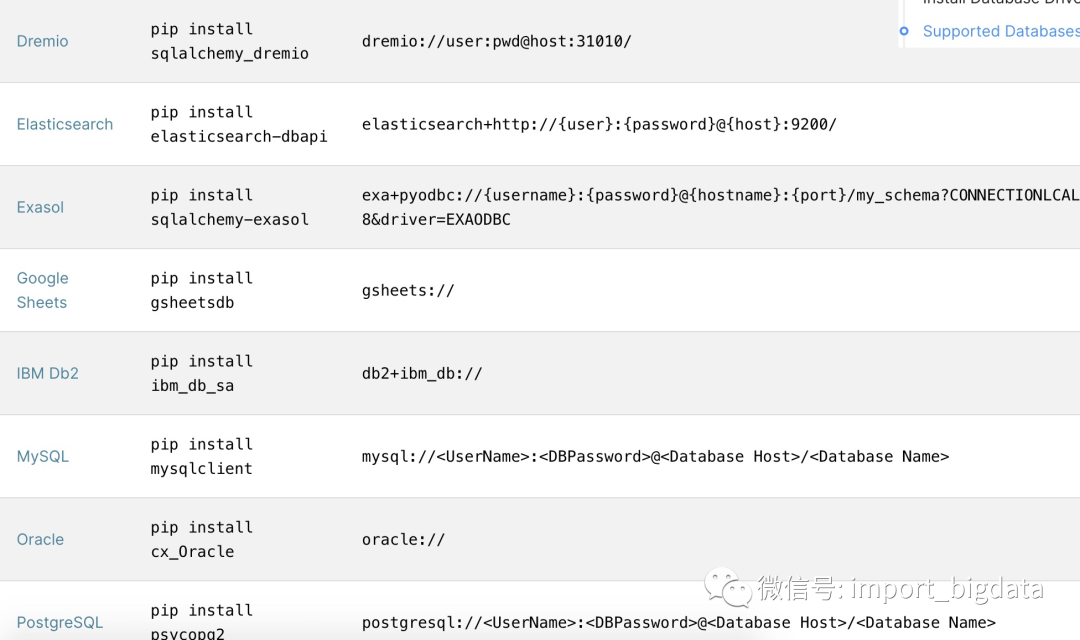
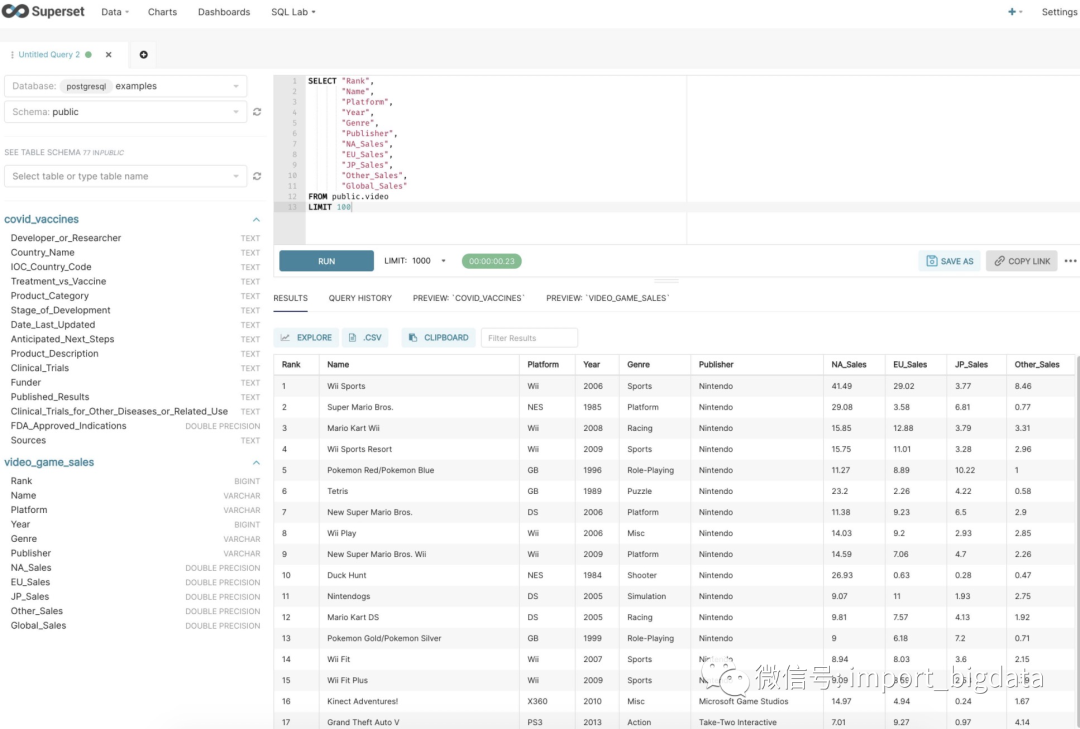
链接PostgreSQL
pip install psycopg2
postgresql:// : @ /
新增数据源
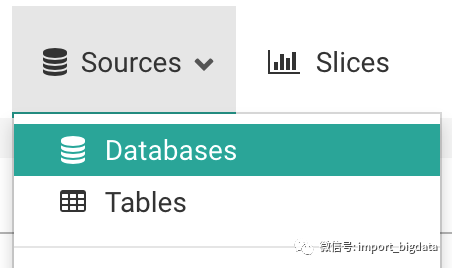
链接到数据库


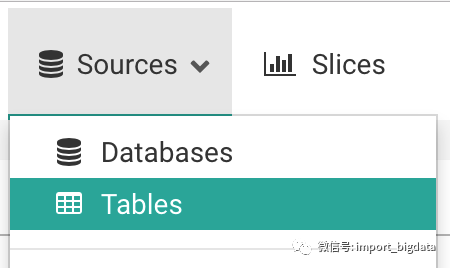
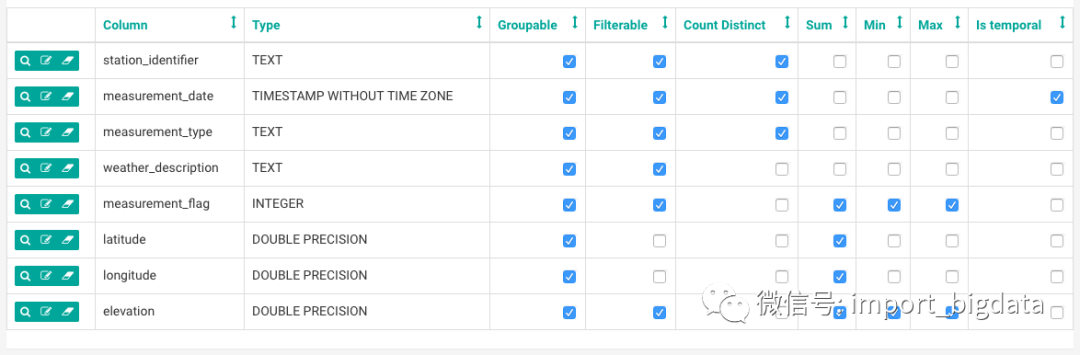
新建表


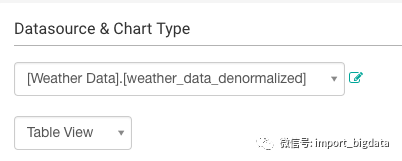
图表类型选择
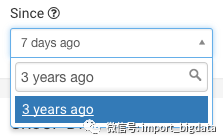
时间范围选择
计算维度选择
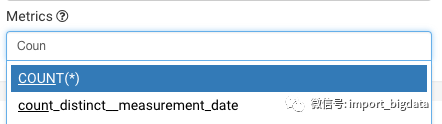
聚合维度选择

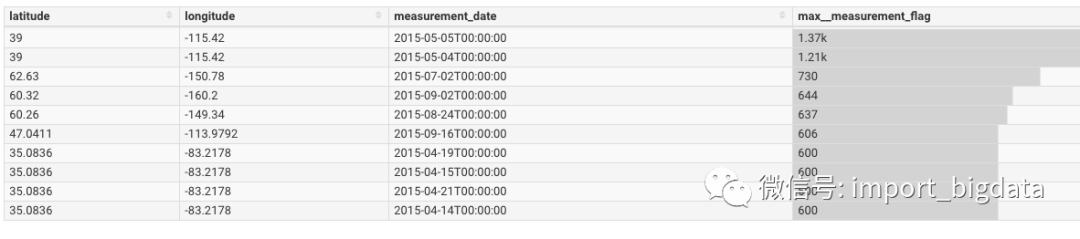
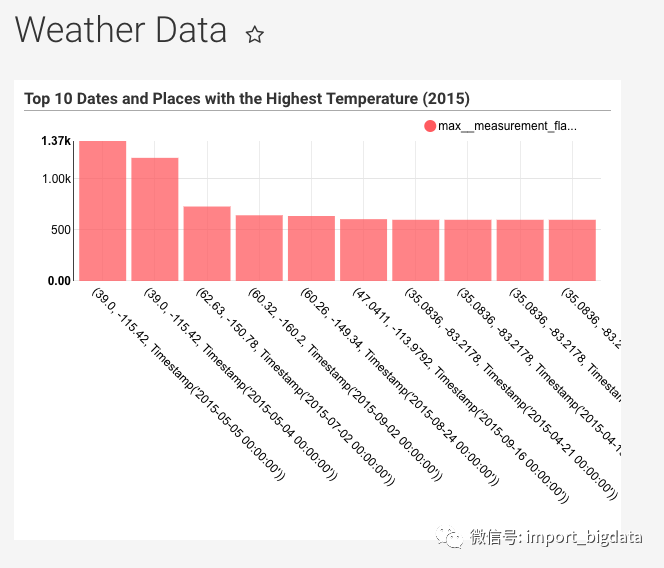
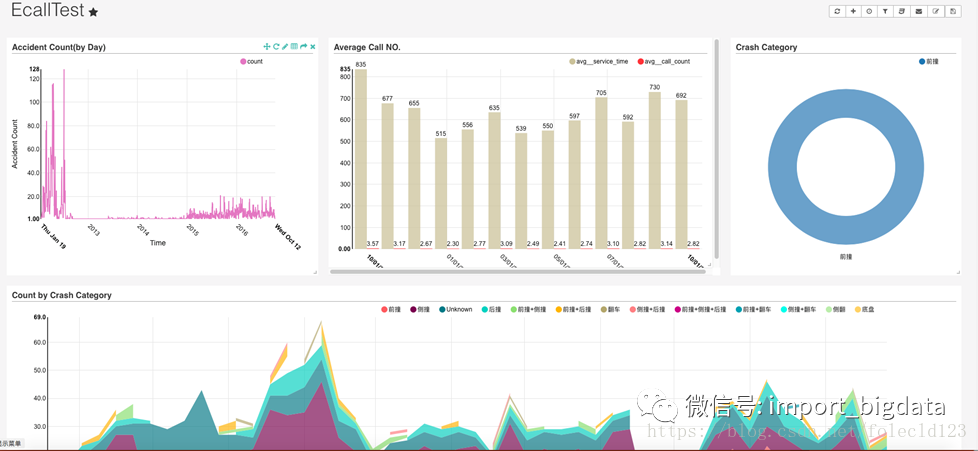
Superset权限体系
使用感受
1. 效率高、Developer Friendly(对开发者友好),适合那些需要快速支持业务的场景,尤其是BI人员看板需求。2. 感觉这是一个程序员主导的产品,基于Python开发,对于使用者来说需要有Python技术栈才能进行二次开发。3. 权限体系小规模使用还算方便,大规模使用需要很高的配置和运维成本。

评论