
种群进化+邻域搜索的混合算法(GA+TS)求解作业车间调度问题(JSP)-算法介绍

代码黑科技的分享区

过去小编简单了解过作业车间调度问题(JSP),这两个月简单接触了柔性车间调度问题(FJSP),但是因为一些原因打算暂时研究到这里。在研究的时候,小编发现网上这方面的中文资源不多,那么秉持着普度众生的原则,就在这里和大家分享一下最近研究的一些成果。
柔性作业车间调度问题介绍
之前我们曾经做过车间调度问题(JSP)的内容,相关可以看这篇文章:
这里再简单介绍一下FJSP:
集合表示一系列相互独立的工件,任一工件需要经过等一系列工序的加工方可完成,工序之间按照固定的加工顺序依次完成。集合表示可用的加工机器,表示工件的第道工序,可以在可用机器集合中的任意机器上进行加工。每道工序的加工时间与加工机器相关。
一道工序一旦开始加工,就不能中断。每台机器一次只能加工一道工序。在初始加工时刻,所有工件和机器都是可用的。
一般来说,该问题的目标是最小化Makespan,通常用L来表示,即从开始加工到所有工件加工完毕总的时长。
综上所述,柔性车间调度问题和车间调度问题相似,在此之上改变了一个条件:对JSP,每道工序只能在某个特定的机器上加工;对FJSP,工序可能有多个可加工的机器(且不同机器上加工时间不同)。
所以,FJSP不光要选择工序在机器上加工的顺序,还要选择在哪个机器上加工。这也意味着FJSP是比JSP更复杂的优化问题。
根据小编这段时间的研究,学术界目前比较常用的启发式求解算法是种群进化+邻域搜索的混合算法,其中GA+TS是比较成熟的算法体系。接下来主要参考论文 An effective hybrid genetic algorithm and tabu search for flexible job shop scheduling problem 的算法,介绍论文里的混合算法HA,以及小编自己复现的代码。(代码和论文可在文末下载)
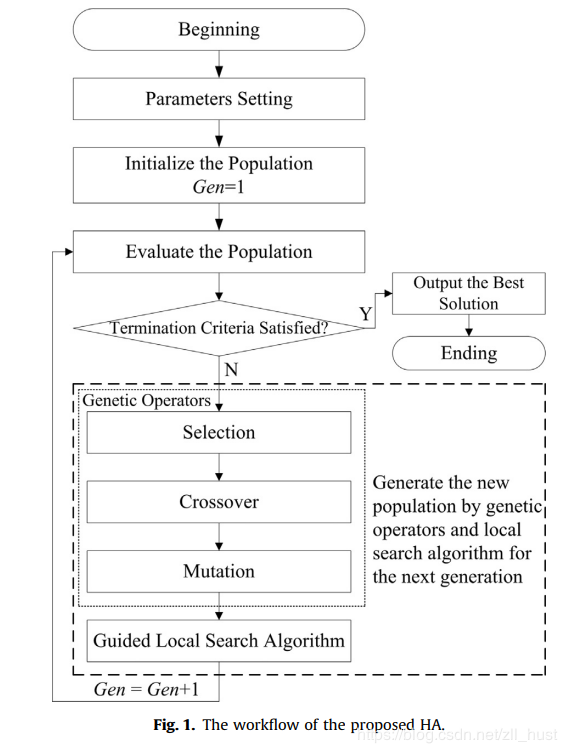 算法总体的流程如上图所示,简单来说就是在GA的过程中,对每一个子代个体进行tabu search优化。下面小编分别对GA部分和TS部分进行讲解。
算法总体的流程如上图所示,简单来说就是在GA的过程中,对每一个子代个体进行tabu search优化。下面小编分别对GA部分和TS部分进行讲解。
遗传算法部分
大家知道,不同的启发式算法在不同问题下效果会有很大的差别。过去小编在研究VRP问题时,GA的表现不是很好,编码、解码过程也相对复杂。但是GA在FJSP上表现的却非常优秀,因此大部分算法采取GA或类似GA的种群进化算法作为基础。仅仅是GA部分,已经可以以相当快的速度得到还算不错的解。
编码解码
FJSP的GA编码采取两行数字的方式。一串叫做OS(operation sequence),一串叫做MS(machine sequence)。之前我们提到过,求解FJSP需要做两个选择:工序加工顺序的选择;工序加工机器的选择。顾名思义,两串编码分别对应这两种选择。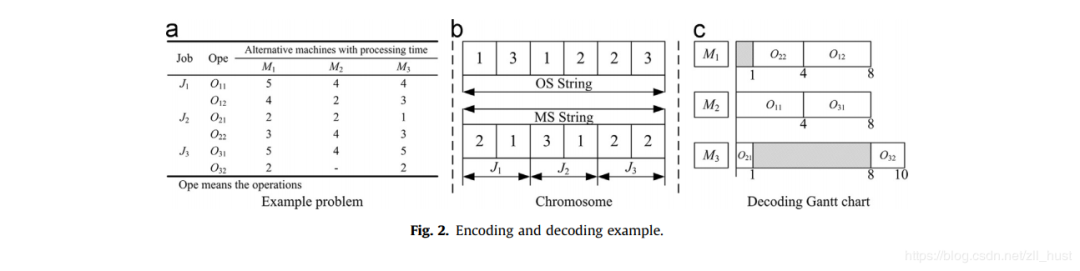 上图是一个FJSP算例的编码和对应解。
上图是一个FJSP算例的编码和对应解。
表a代表算例。

表b的OS String和MS String代表染色体编码。
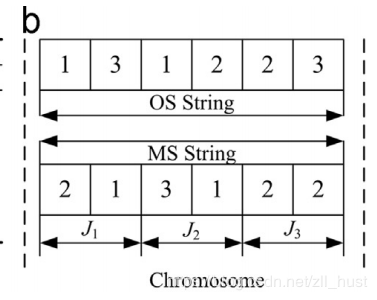
MS String中也有N个数字,代表每个工件选择的机器。MS的顺序按照工件顺序排列,如图,J1、J2、J3都有2道工序,那么第一位数字“2”则代表O11,J1T1,需要安排在第二个可以加工的机器上。注意这里的数字不代表机器序号,代表的是可加工的机器。例如最后一位数字“2”,代表的不是machine2,因为J3T3无法在machine2上加工;它代表的是J3T3第二个可加工的机器,也就是machine3。
表c用甘特图表示了表b中编码解码出的一个可行解。
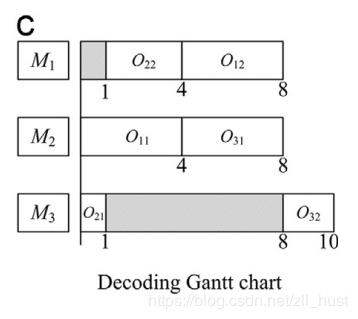
这里介绍一下如何优化decode。首先,我们设定 (allowing starting time),代表Oij的在工序约束(必须在同一工件上一道工序结束后才能开始加工)下的最早允许开始时间;代表Oij的结束时间。则我们得到公式。
从第一道工序开始按OS的顺序,安排工序Oij:
计算 检查工序所在加工机器中的所有空闲时间区间。例如对O22而言,其所在加工机器M1中的空闲时间区间有一个:。 ,则设置当前工序Oij的开始时间。其中表示Oij在机器k上加工的时间。 否则,检查下一个空闲时间区间。若所有区间都不满足,放置机器最后。 设置工序加工结束时间。
编码的过程则比较简单。MS编码自不用说,按顺序把机器需要排列好就行;OS编码论文中没提编码方法,小编觉得可以对所有工序直接按照starting time排序,再按规则填入数字即可。简单试验后发现,对一串染色体进行这样的解码编码后得到的染色体与原本的染色体是相同的。
除了编码解码外,其他交叉、变异、选择部分与一般的GA算法没有太大差别。对一串合法的OS序列,无论进行怎样的交换、插入运算,都可以解码成可行解。对MS序列,在同一工件范围内任意交换顺序,也可以保证得到可行解。所以后续处理相对常规。
下面我们分别介绍相关步骤。
初始解生成
初始解生成采用随机生成的方式。
交叉
OS
OS String介绍两种crossover方法,分别为POX(precedence operation crossover )和JBX(job-basedcrossover ),每次迭代分别以50%的概率选择其中一个实行。
先介绍POX。
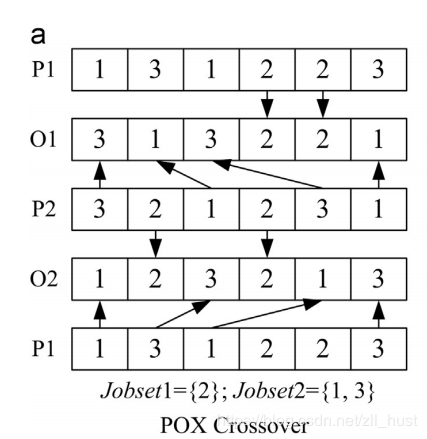
记父代为P1,P2,子代为O1,O2。
将工件随机分配成两组,Jobset1和Jobset12; 将P1中属于JS1的部分插入O1相同位置处,将P2中属于JS1的部分插入O1相同位置处; 将P1中属于JS2的部分按顺序插入O1的空余位置中(如图所示),P2同。
JBX非常类似:
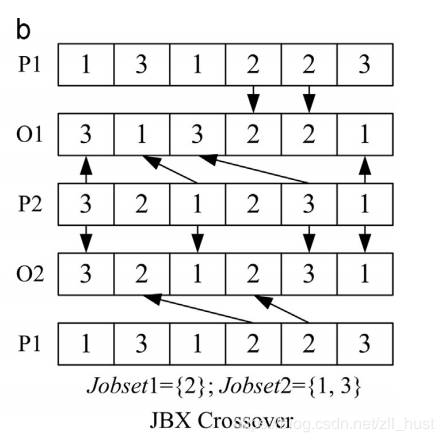
将工件随机分配成两组,Jobset1和Jobset12; 将P1中属于JS1的部分插入O1相同位置处,P2中属于JS2的部分插入O2相同位置中; 将P2中属于JS2的部分按顺序插入O1的空余位置中(如图所示),P1则插入O2中。
MS
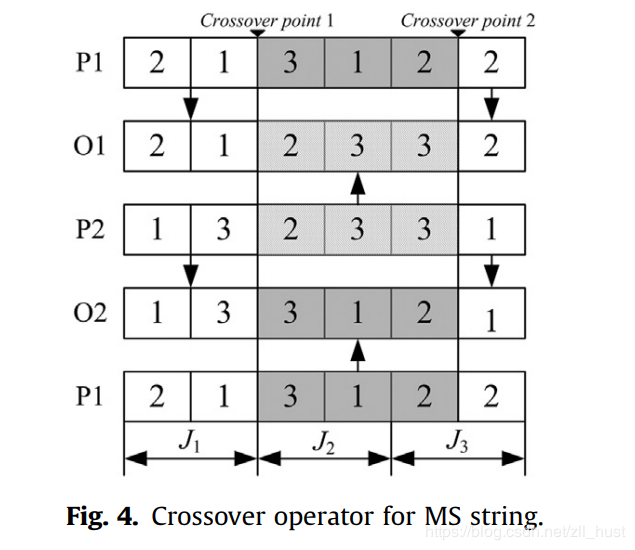 MS更简单,随机选择两个位置,如图所示,属于范围内的P1部分放到O1中,不属于范围内的P2部分放到O1中;属于范围内的P2部分放到O2中,不属于范围内的P1部分放到O2中。
MS更简单,随机选择两个位置,如图所示,属于范围内的P1部分放到O1中,不属于范围内的P2部分放到O1中;属于范围内的P2部分放到O2中,不属于范围内的P1部分放到O2中。
变异
OS
OS的变异有两种方法,交换式和邻域式。
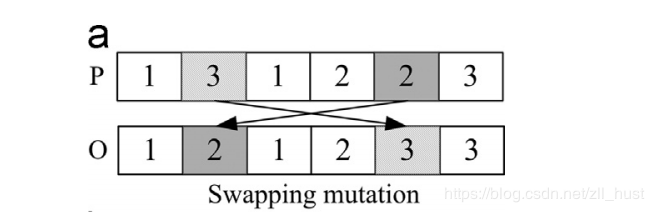 交换式即随机选择两点交换位置。
交换式即随机选择两点交换位置。
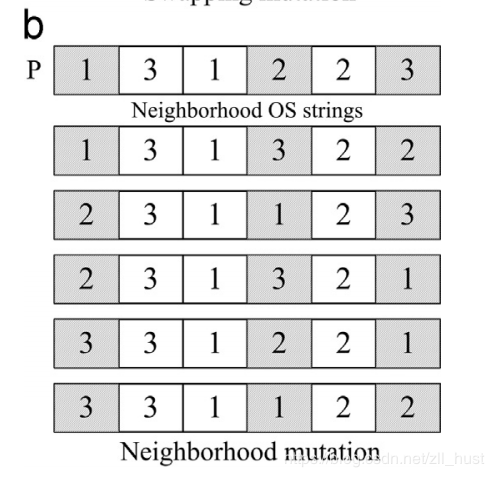 邻域式则是选择三个点,组成种情况,再随机选择其中一种。
邻域式则是选择三个点,组成种情况,再随机选择其中一种。
选择
选择可以有多种方法。精英选择,锦标赛选择,轮盘赌选择。这里介绍论文里使用的前两种。(小编的代码中三种都有写)
精英选择:直接按适应度排序,取最优的几个。
锦标赛选择:每次随机选择k个子代(k一般在2~6之间,论文里采用k=2),选出其中最优的一个。
论文里采用精英选择+竞标赛选择的方法。
禁忌搜索算法部分
禁忌搜索算法部分是嵌套在GA中的。按原论文的说法,对每一代子代的每一个个体,都需要decode成可行解,然后运用禁忌搜索优化解,再编码回GA编码,进入下一代。(听起来就觉得时间复杂度蛮高的)
除了甘特图外,JSP / FJSP还有自己的一套表示解的方法,称为析取图。简单来说,就是把工序作为点,前后加工关系作为边,以此表示工序的加工顺序。
如前文所说,由于嵌套至每一个个体,算法的运行时间很容易爆炸,多写一个循环都会产生不可估量的后果。同时,原论文在这一部分没有很详细的描述,因此小编在复现这一部分的时候也没有处理的很好,来来回回写了多个Tabu Search。由于篇幅原因,这一部分暂时留到下期讲,后续应该还会对小编的代码进行简单讲解,请大家多多关注!
关于甘特图的画法,可以参照:
10分钟用Python或MATLAB制作漂亮的甘特图(Gantt)
参考
[1]Li, Xinyu , and L. Gao . "An effective hybrid genetic algorithm and tabu search for flexible job shop scheduling problem." International Journal of Production Economics 174.Apr.(2016):93-110.
[2]Zhang, Chao Yong , P. G. Li , and Y. R. Zailin Guan . "A tabu search algorithm with a new neighborhood structure for the job shop scheduling problem." Computers & Operations Research 34.11(2007):3229-3242.
[3]Mastrolilli, Monaldo , and L. M. Gambardella . "Effective Neighbourhood Functions for the Flexible Job Shop Problem." Journal of Scheduling 3.1(2015):3-20.
[4]Zhang, Guohui , L. Gao , and Y. Shi . "An effective genetic algorithm for the flexible job-shop scheduling problem." Expert Systems with Applications 38.4(2011):3563-3573.
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
