
Hudi 实践 | 基于 Apache Hudi 构建分析型数据湖

为了更好地发展业务,每个组织都在迅速采用分析。在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能。通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特定受众。只有当我们能够大规模提供分析时,这一切才有可能。
对数据湖的需求
在 NoBrokercom[1],出于操作目的,事务数据存储在基于 SQL 的数据库中,事件数据存储在 No-SQL 数据库中。这些应用程序 dB 未针对分析工作负载进行调整。此外,为了更全面地了解客户和业务,通常需要跨交易和事件数据加入数据。这些限制大大减慢了分析过程。为了解决这些问题,我们开发了一个名为 STARSHIP 的数据平台,它提供了所有 Nobroker 数据的集中存储库,并且可以通过 SQL 访问。
STARSHIP 正在为 40TB+ 快速发展的数据提供分析。在 Nobroker 上发生的任何事件或交易,都可以在 30 分钟内在 Starship 中进行分析。
它的一个组成部分是构建针对分析优化的数据存储层。Parquet 和 ORC 数据格式提供此功能,但它们缺少更新和删除功能。
Apache Hudi
Apache Hudi 是一个开源数据管理框架,提供列数据格式的记录级插入、更新和删除功能。我们在将数据带到 STARSHIP 的所有 ETL 管道中广泛使用 Apache Hudi。我们使用 Apache Hudi 的 DeltaStreamer 实用程序采用增量数据摄取。我们已经能够增强 DeltaStreamer 以适应我们的业务逻辑和数据特征。
DeltaStreamer
在到达分布式云存储之前,数据通过 Apache Hudi 中的多个相互连接的模块进行处理。这些模块可以独立工作,也可以通过 Delta-streamer 实用程序工作,从而简化整个 ETL 流程。尽管提供的默认功能有限,但它允许使用可扩展的 Java 类进行定制。
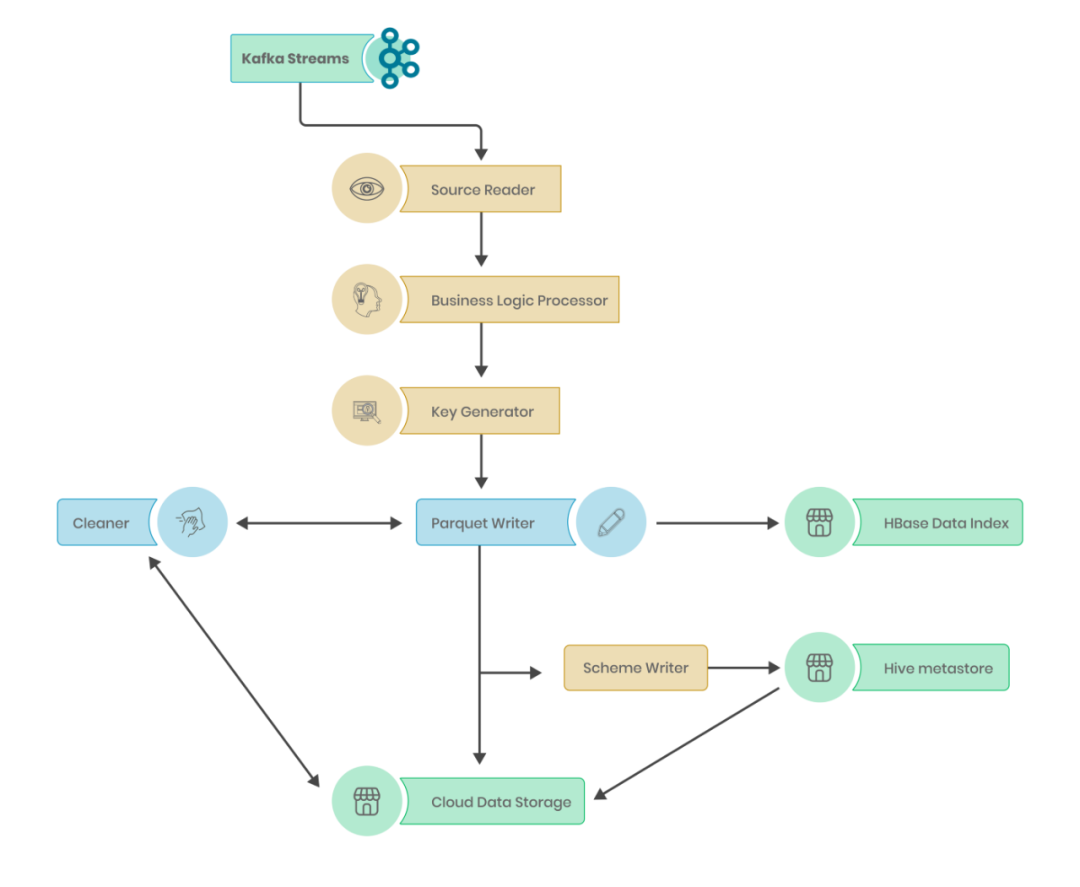
源读取器
源读取器是 Hudi 数据处理中的第一个也是最重要的模块,用于从上游读取数据。Hudi 提供支持类,可以从本地文件(如 JSON、Avro 和 Kafka 流)读取。在我们的数据管道中,CDC 事件以 Avro 格式生成到 Kafka。我们扩展了源类以添加来自 Kafka 的增量读取,每次读取一个特定的编号。来自存储的检查点的消息,我们添加了一项功能,将 Kafka 偏移量附加为数据列。
# Reading data from Kafka from given Offset ranges
baseConsumerRDD = KafkaUtils.createRDD(
sparkContext,
KafkaParams,
offsetRanges,
consistent_location_strategy,
)
.filter(x -> x != null)
.filter(x -> x.value() != null);
# Adding Message offset to the data
baseRDD = baseConsumerRDD.map(x ->"{
\"starship_offset\":"+x.offset()
+","
+"\"starship_value\": "
+ x.value().toString() +
"}"
);
# Reading into Spark data frame & Applying schema
table_df = sparkSession.read()
.schema(table.getIncomingSchema())
.json(baseRDD)
.select(
"starship_value.*",
"starship_offset"
);在初始数据读取之后,我们还强制执行从 Kafka 模式注册表或用户提供的自定义模式获取的模式。
业务逻辑处理器
从 Source reader 带入 Spark 数据帧的数据将采用原始格式。为了使其可用于分析,我们需要对数据进行清理、标准化和添加业务逻辑。STARSHIP 中的每个数据点都经过以下转换,以确保数据质量。
• case标准化:下/上case。
• 日期格式转换:将各种字符串日期格式转换为毫秒。
• 时区标准化:将所有时区的数据转换为 UTC。
• 电话号码标准化:将电话号码格式化为“国家代码 - 电话号码”格式。
• 数据类型转换:将引用的数字转换为 Int/Long,转换为文本格式等。
• 屏蔽和散列:使用散列算法屏蔽敏感信息。
• 自定义 SQL 查询处理:如果需要对特定列应用自定义过滤器,它们可以作为 SQL 子句传递。
• 地理点数据处理:将地理点数据处理为 Parquet 支持的格式。
• 列标准化:将所有列名转换为蛇形大小写并展平任何嵌套列。
键生成器
Hudi 中的每一行都使用一组键表示,以提供行级别的更新和删除。Hudi 要求每个数据点都有一个主键、一个排序键以及在分区的情况下还需要一个分区键。
• 主键:识别一行是更新还是新插入。
• 排序键:识别当前批次事件中每个主键的最新事件,以防同一批次中同一行出现多个事件。
• 分区键:以分区格式写入数据。
对来自 CDC 管道的事件进行排序变得很棘手,尤其是在同一逻辑处理多种类型的流时。为此,我们编写了一个键生成器类,它根据输入数据流源处理排序逻辑,并提供对多个键作为主键的支持。
Parquet写入器
一旦数据处于最终转换格式,Hudi writer 将负责写入过程。每个新的数据摄取周期称为一次提交并与提交编号相关联。
• 提交开始:摄取从在云存储中创建的“
.commit_requested”文件开始。 • 提交飞行:一旦处理完所有转换后开始写入过程,就会创建一个“
.commit_inflight”文件。 • 提交结束:一旦数据成功写入磁盘,就会创建最终的“
.commit”文件。
只有当最终的 .commit 文件被创建时,摄取过程才被称为成功。万一发生故障,Hudi writer 会回滚对 parquet 文件所做的任何更改,并从最新的可用 .commit 文件中获取新的摄取。如果我们每次提交都编写新的 Parquet 文件,我们最终会得到一个很大的数字。小文件会减慢分析过程。为此,每次有新插入时,Hudi writer 会识别是否有任何小文件并向它们添加新插入,而不是写入新文件。
在 Nobroker,我们确保每个 parquet 文件的大小至少为 100MB,以优化分析的速度。
数据索引
除了写入数据,Hudi 还跟踪特定行的存储位置,以加快更新和删除速度。此信息存储在称为索引的专用数据结构中。Hudi 提供了多种索引实现,例如布隆过滤器、简单索引和 HBase 索引Hudi表。我们从布隆过滤器开始,但随着数据的增加和用例的发展,我们转向 HBase 索引,它提供了非常快速的行元数据检索。
HBase 索引将我们的 ETL 管道的资源需求减少了 30%。
Schema写入器
一旦数据被写入云存储,我们应该能够在我们的平台上自动发现它。为此,Hudi 提供了一个模式编写器,它可以更新任何用户指定的模式存储库,了解新数据库、表和添加到数据湖的列。我们使用 Hive 作为我们的集中Schema存储库。默认情况下Hudi 将源数据中的所有列以及所有元数据字段添加到模式存储库中。由于我们的数据平台面向业务,我们确保在编写Schema时跳过元数据字段。这对性能没有影响,但为分析用户提供了更好的体验。
在 Schema writer 的帮助下,业务可以在上游数据中添加一个新的特性,并且它可以在我们的数据平台上使用,而无需任何人工干预。
Cleaner
在摄取过程中,会创建大量元数据文件和临时文件。如果保持不变,它们会降低分析性能。Hudi 确保所有不必要的文件在需要时被归档和删除。每次发生新的摄取时,一些现有的 Parquet 文件都会推出一个新版本。旧版本可用于跟踪事件时间线和使查询运行更长时间。他们慢慢地填满了存储空间。为此,Cleaner 提供了 2 种减少存储空间的方法
• KEEP_LATEST_FILE_VERSIONS :最新的文件版本被保留,而旧的被删除。
• KEEP_LATEST_COMMITS :仅保留 n 个最新提交写入的文件版本。
我们的数据平台经过调整,可在 1 分钟内提供交互式查询/报告。同时,我们确保旧文件版本最多保留 1 小时,以支持长时间运行的数据科学工作负载。
Apache Hudi 是 Starship Data 平台最重要的部分之一。我们还有更多组件提供其他功能,例如可视化、交互式查询引擎等。
引用链接
[1] NoBrokercom: [https://medium.com/@NoBroker](https://medium.com/@NoBroker)