
16 个写代码的好习惯
今日推荐 程序猿惯用口头禅,你被击中了吗? 常见代码重构技巧(非常实用) B站,牛啊。
每一个好习惯都是一笔财富,本文整理了写代码的16个好习惯,每个都很经典,养成这些习惯,可以规避多数非业务的bug!希望对大家有帮助哈,谢谢阅读,加油哦~
github地址,感谢每颗star
❝https://github.com/whx123/JavaHome
❞
1. 修改完代码,记得自测一下
「改完代码,自测一下」 是每位程序员必备的基本素养。尤其不要抱有这种侥幸「心理:我只是改了一个变量或者我只改了一行配置代码,不用自测了」。改完代码,尽量要求自己都去测试一下哈,可以规避很多不必要bug的。

2. 方法入参尽量都检验
入参校验也是每个程序员必备的基本素养。你的方法处理,「必须先校验参数」。比如入参是否允许为空,入参长度是否符合你的预期长度。这个尽量养成习惯吧,很多「低级bug」都是「不校验参数」导致的。
❝如果你的数据库字段设置为varchar(16),对方传了一个32位的字符串过来,你不校验参数,「插入数据库直接异常」了。
❞

3. 修改老接口的时候,思考接口的兼容性。
很多bug都是因为修改了对外老接口,但是却「不做兼容导致」的。关键这个问题多数是比较严重的,可能直接导致系统发版失败的。新手程序员很容易犯这个错误哦~
所以,如果你的需求是在原来接口上修改,,尤其这个接口是对外提供服务的话,一定要考虑接口兼容。举个例子吧,比如dubbo接口,原本是只接收A,B参数,现在你加了一个参数C,就可以考虑这样处理。
//老接口
void oldService(A,B);{
//兼容新接口,传个null代替C
newService(A,B,null);
}
//新接口,暂时不能删掉老接口,需要做兼容。
void newService(A,B,C);

4.对于复杂的代码逻辑,添加清楚的注释
写代码的时候,是没有必要写太多的注释的,好的方法变量命名就是最好的注释。但是,如果是「业务逻辑很复杂的代码」,真的非常有必要写「清楚注释」。清楚的注释,更有利于后面的维护。

5. 使用完IO资源流,需要关闭
应该大家都有过这样的经历,windows系统桌面如果「打开太多文件」或者系统软件,就会觉得电脑很卡。当然,我们linux服务器也一样,平时操作文件,或者数据库连接,IO资源流如果没关闭,那么这个IO资源就会被它占着,这样别人就没有办法用了,这就造成「资源浪费」。

所以使用完IO流,可以使用finally关闭哈
FileInputStream fdIn = null;
try {
fdIn = new FileInputStream(new File("/jay.txt"));
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}finally {
try {
if (fdIn != null) {
fdIn.close();
}
} catch (IOException e) {
log.error(e);
}
}
JDK 7 之后还有更帅的关闭流写法,「try-with-resource」。
/*
* 关注公众号,捡田螺的小男孩
*/
try (FileInputStream inputStream = new FileInputStream(new File("jay.txt")) {
// use resources
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
6.代码采取措施避免运行时错误(如数组边界溢出,被零除等)
日常开发中,我们需要采取措施规避「数组边界溢出,被零整除,空指针」等运行时错误。
类似代码比较常见:
String name = list.get(1).getName(); //list可能越界,因为不一定有2个元素哈
所以,应该「采取措施,预防一下数组边界溢出」,正例:
if(CollectionsUtil.isNotEmpty(list)&& list.size()>1){
String name = list.get(1).getName();
}

7.尽量不在循环里远程调用、或者数据库操作,优先考虑批量进行。
远程操作或者数据库操作都是「比较耗网络、IO资源」的,所以尽量不在循环里远程调用、不在循环里操作数据库,能「批量一次性查回来尽量不要循环多次去查」。(但是呢,也不要一次性查太多数据哈,要分批500一次酱紫)
正例:
remoteBatchQuery(param);
反例:
for(int i=0;i<n;i++){
remoteSingleQuery(param)
}

8.写完代码,脑洞一下多线程执行会怎样,注意并发一致性问题
我们经常见的一些业务场景,就是先查下有没有记录,再进行对应的操作(比如修改)。但是呢,(查询+修改)合在一起不是原子操作哦,脑洞下多线程,就会发现有问题了,
反例如下:
if(isAvailable(ticketId){
1、给现金增加操作
2、deleteTicketById(ticketId)
}else{
return "没有可用现金券";
}
为了更容易理解它,看这个流程图吧:
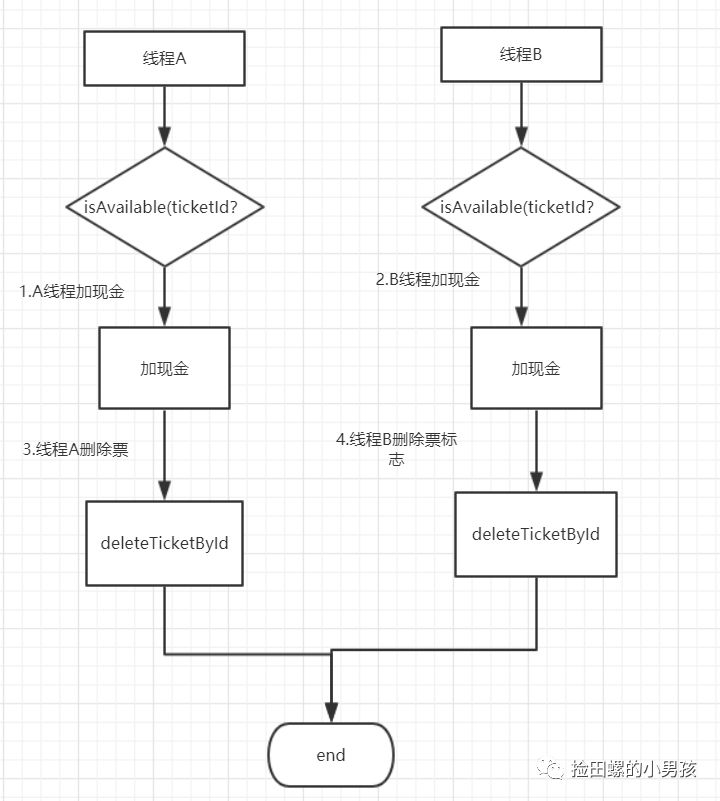
1.线程A加现金 2.线程B加现金 3.线程A删除票标志 4.线程B删除票标志
显然这样存在「并发问题」,正例应该「利用数据库删除操作的原子性」,如下:
if(deleteAvailableTicketById(ticketId) == 1){
1、给现金增加操作
}else{
return “没有可用现金券”
}
因此,这个习惯也是要有的,「写完代码,自己想下多线程执行,是否会存在并发一致性问题」。

9.获取对象的属性,先判断对象是否为空
这个点本来也属于「采取措施规避运行时异常」的,但是我还是把它拿出来,当做一个重点来写,因为平时空指针异常太常见了,一个手抖不注意,就导致空指针报到生产环境去了。
所以,你要获取对象的属性时,尽量不要相信「理论上不为空」,我们顺手养成习惯判断一下是否为空,再获取对象的属性。正例:
if(object!=null){
String name = object.getName();
}

10.多线程异步优先考虑恰当的线程池,而不是new thread,同时考虑线程池是否隔离
为什么优先使用线程池?使用线程池有这几点好处呀
它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。 提高响应速度。 重复利用。
同时呢,尽量不要所有业务都共用一个线程池,需要考虑「线程池隔离」。就是不同的关键业务,分配不同的线程池,然后线程池参数也要考虑恰当哈。

11. 手动写完代码业务的SQL,先拿去数据库跑一下,同时也explain看下执行计划。
手动写完业务代码的SQL,可以先把它拿到数据库跑一下,看看有没有语法错误嘛。有些小伙伴不好的习惯就是,写完就把代码打包上去测试服务器,其实把SQL放到数据库执行一下,可以规避很多错误的。
同时呢,也用「explain看下你Sql的执行计划」,尤其走不走索引这一块。
explain select * from user where userid =10086 or age =18;

12.调用第三方接口,需要考虑异常处理,安全性,超时重试这几个点。
调用第三方服务,或者分布式远程服务的的话,需要考虑
异常处理(比如,你调别人的接口,如果异常了,怎么处理,是重试还是当做失败) 超时(没法预估对方接口一般多久返回,一般设置个超时断开时间,以保护你的接口) 重试次数(你的接口调失败,需不需要重试,需要站在业务上角度思考这个问题)
❝简单一个例子,你一个http请求别人的服务,需要考虑设置connect-time,和retry次数。
❞
如果是转账等重要的第三方服务,还需要考虑「签名验签」,「加密」等。之前写过一篇加签验签的,有兴趣的朋友可以看一下哈

13.接口需要考虑幂等性
接口是需要考虑幂等性的,尤其抢红包、转账这些重要接口。最直观的业务场景,就是「用户连着点击两次」,你的接口有没有hold住。
❝❞
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。 在编程中.一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。
一般「幂等技术方案」有这几种:
查询操作 唯一索引 token机制,防止重复提交 数据库的delete删除操作 乐观锁 悲观锁 Redis、zookeeper 分布式锁(以前抢红包需求,用了Redis分布式锁) 状态机幂等

14. 多线程情况下,考虑线性安全问题
在「高并发」情况下,HashMap可能会出现死循环。因为它是非线性安全的,可以考虑使用ConcurrentHashMap。所以这个也尽量养成习惯,不要上来反手就是一个new HashMap();
❝❞
Hashmap、Arraylist、LinkedList、TreeMap等都是线性不安全的; Vector、Hashtable、ConcurrentHashMap等都是线性安全的

15.主从延迟问题考虑
先插入,接着就去查询,这类代码逻辑比较常见,这「可能」会有问题的。一般数据库都是有主库,从库的。写入的话是写主库,读一般是读从库。如果发生主从延迟,很可能出现你插入成功了,但是却查询不到的情况。

如果是重要业务,需要考虑是否强制读主库,还是再修改设计方案。 但是呢,有些业务场景是可以接受主从稍微延迟一点的,但是这个习惯还是要有吧。 写完操作数据库的代码,想下是否存在主从延迟问题。
16.使用缓存的时候,考虑缓存跟DB的一致性,还有(缓存穿透、缓存雪崩和缓存击穿)
通俗点说,我们使用缓存就是为了「查得快,接口耗时小」。但是呢,用到缓存,就需要「注意缓存与数据库的一致性」问题。同时,还需要规避缓存穿透、缓存雪崩和缓存击穿三大问题。
❝❞
缓存雪崩:指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。 缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。 缓存击穿:指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。

推荐文章
更多项目源码