
Java8中为什么使用红黑树?
前言
在jdk1.8版本后,Java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度。
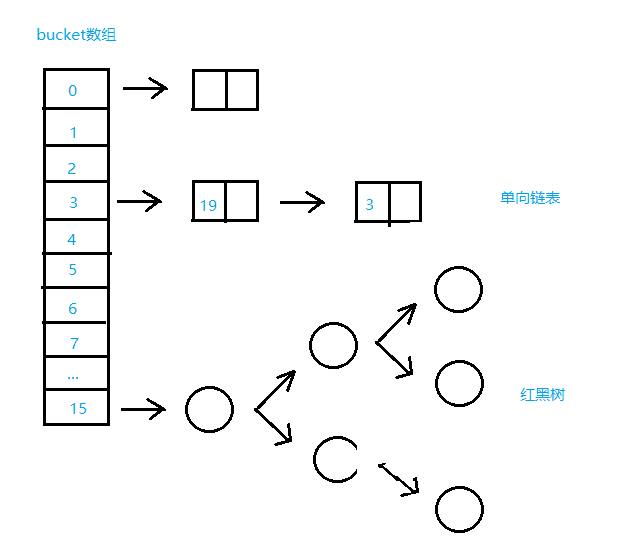
Java8中HashMap数据结构
什么是红黑树?
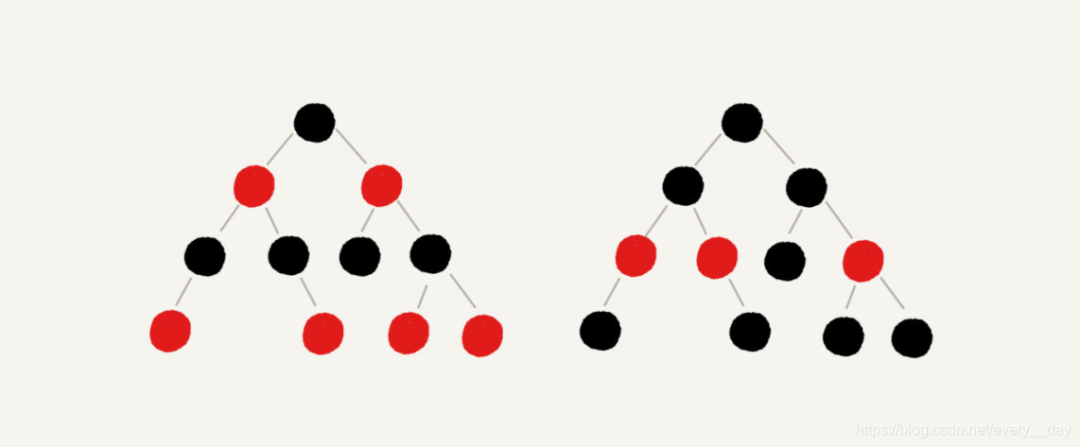
红黑树(Red Black Tree)是一颗自平衡(self-balancing)的二叉排序树(BST),树上的每一个结点都遵循下面的规则(特别提醒,这里的自平衡和平衡二叉树AVL的高度平衡有别):
每一个结点都有一个颜色,要么为红色,要么为黑色;
树的根结点为黑色;
树中不存在两个相邻的红色结点(即红色结点的父结点和孩子结点均不能是红色);
从任意一个结点(包括根结点)到其任何后代 NULL 结点(默认是黑色的)的每条路径都具有相同数量的黑色结点。
红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。加快检索速率。
总结:
为什么选择红黑树?
红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于插入删除等操作效率提高很多。红黑树不像avl树一样追求绝对的平衡,他允许局部很少的不完全的平衡,这样对于效率影响不大,能够省去了很多没有必要调平衡的操作。
既然红黑树这么好,为什么HashMap不直接用红黑树,而是当链表数大于8的时候才转换为红黑树?
因为红黑树需要进行左旋、右旋操作,单链表则不需要。
以下是红黑树和单链表的对比
元素小于8个时,查询成本高,新增成本低
元素大于8个时,查询成本低,新增成本高
评论