
美团图数据库平台建设及业务实践

1 前言
2 图数据库选型
3 NebulaGraph架构
4 图数据库平台建设
4.1 高可用模块设计
4.2 每小时百亿量级数据导入模块设计
4.3 实时写入多集群数据同步模块设计
4.4 图可视化模块设计
5 业务实践
5.1 智能助理
5.2 搜索召回
5.3 图谱推荐理由
5.4 代码依赖分析
6 总结与展望
7 作者信息
8 参考资料
9 招聘信息
1 前言
图数据结构,能够很自然地表征现实世界。比如用户、门店、骑手这些实体可以用图中的点来表示,用户到门店的消费行为、骑手给用户的送餐行为可以用图中的边来表示。使用图的方式对场景建模,便于描述复杂关系。在美团,存在比较多的图数据存储及多跳查询需求,概括起来主要包括以下 4 个方面:
图谱挖掘: 美团有美食图谱、商品图谱、旅游图谱、用户全景图谱在内的近 10 个领域知识图谱,数据量级大概在千亿级别。在迭代、挖掘数据的过程中,需要一种组件对这些图谱数据进行统一的管理。 安全风控: 业务部门有内容风控的需求,希望在商户、用户、评论中通过多跳查询来识别虚假评价;在支付时进行金融风控的验证,实时多跳查询风险点。 链路分析: 包括代码分析、服务治理、数据血缘管理,比如公司数据平台上有很多 ETL Job,Job 和 Job 之间存在强弱依赖关系,这些强弱依赖关系形成了一张图,在进行 ETL Job 的优化或者故障处理时,需要对这个图进行实时查询分析。 组织架构: 公司组织架构的管理,实线汇报链、虚线汇报链、虚拟组织的管理,以及商家连锁门店的管理。比如,维护一个商家在不同区域都有哪些门店,能够进行多层关系查找或者逆向关系搜索。
总体来说,美团需要一种组件来管理千亿级别的图数据,解决图数据存储以及多跳查询问题。海量图数据的高效存储和查询是图数据库研究的核心课题,如何在大规模分布式场景中进行工程落地是我们面临的痛点问题。传统的关系型数据库、NoSQL 数据库可以用来存储图数据,但是不能很好处理图上多跳查询这一高频的操作。
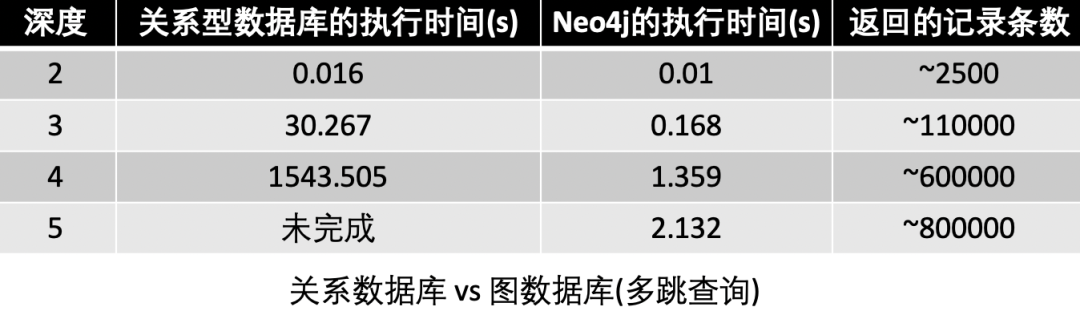
Neo4j 公司在社交场景(见图1)里做了传统关系型数据库 MySQL 跟图数据库 Neo4j 的查询性能对比 [1],在一个包含 100 万人、每人约有 50 个朋友的社交网络里找最大深度为 5 的朋友的朋友,实验结果表明多跳查询中图数据库优势明显(见图 2)。然而选取或者自主研发一款高吞吐、低查询延时、能存储海量数据且易用的图数据库非常困难。下面将介绍美团在图数据库选型及平台建设方面的一些工作。
2 图数据库选型
在图数据库的选型上我们主要考虑了以下 5 点:(A) 项目开源,暂不考虑需付费的图数据库;(B) 分布式架构设计,具备良好的可扩展性;(C) 毫秒级的多跳查询延迟;(D) 支持千亿量级点边存储;(E) 具备批量从数仓导入数据的能力。
分析 DB-Engines[2] 上排名前 30 的图数据库,剔除不开源的项目,我们将剩余的图数据库分为三类:
第一类:Neo4j[3]、ArangoDB[4]、Virtuoso[5]、TigerGraph[6]、RedisGraph[7]。 此类图数据库只有单机版本开源可用,性能优秀,但不能应对分布式场景中数据的规模增长,即不满足选型要求(B)、(D)。 第二类:JanusGraph[8]、HugeGraph[9]。 此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求,即不满足选型要求(C)。 第三类:DGraph[10]、NebulaGraph[11]。 此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们的选型要求。
DGraph 是由前 Google 员工 Manish Rai Jain 离职创业后,在 2016 年推出的图数据库产品,底层数据模型是 RDF[12],基于 Go 语言编写,存储引擎基于 BadgerDB[13] 改造,使用 RAFT 保证数据读写的强一致性。
NebulaGraph 是由前 Facebook 员工叶小萌离职创业后,在 2019年 推出的图数据库产品,底层数据模型是属性图,基于 C++ 语言编写,存储引擎基于 RocksDB[14] 改造,也使用 RAFT 保证数据读写的强一致性。
这两个项目的创始人都在互联网公司图数据库领域深耕多年,对图数据库的落地痛点有深刻认识,整体的架构设计也有较多相似之处。在图数据库最终的选型上,我们基于 LDBC-SNB 数据集[15]对 NebulaGraph、DGraph、HugeGraph 进行了深度性能测评,测试详情见文章:主流开源分布式图数据库 Benchmark,从测试结果看 NebulaGraph 在数据导入、实时写入及多跳查询方面性能均优于竞品。此外,NebulaGraph 社区活跃,问题响应速度快,所以我们团队最终选择基于 NebulaGraph 来搭建图数据库平台。
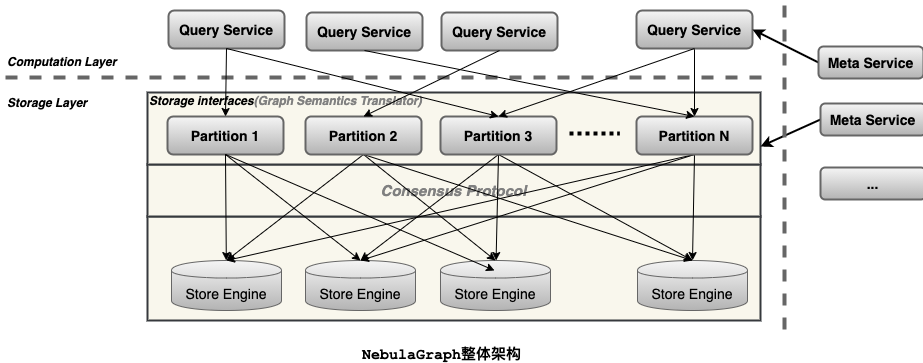
一个完整的 NebulaGraph 集群包含三类服务,即 Query Service、Storage Service 和 Meta Service。每类服务都有各自的可执行二进制文件,既可以部署在同一节点上,也可以部署在不同的节点上。下面是NebulaGraph 架构设计(见图 3)的几个核心点[16][17]。
Meta Service: 架构图中右侧为 Meta Service 集群,它采用 Leader/Follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务;Followers 处于待命状态,并从 Leader 复制更新的数据。一旦 Leader 节点 Down 掉,会再选举其中一个 Follower 成为新的 Leader。Meta Service 不仅负责存储和提供图数据的 Meta 信息,如 Schema、数据分片信息等,同时还提供 Job Manager 机制管理长耗时任务,负责指挥数据迁移、Leader 变更、数据 compaction、索引重建等运维操作。 存储计算分离: 在架构图中 Meta Service 的左侧,为 NebulaGraph 的主要服务,NebulaGraph 采用存储与计算分离的架构,虚线以上为计算,以下为存储。存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。存储计算分离还带来了另一个优势:使水平扩展成为可能。此外,存储计算分离使得 Storage Service 可以为多种类型的计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的 OLTP 计算层,而各种 OLAP 迭代计算框架会是另外一个计算层。 无状态计算层: 每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 Meta 信息以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。 Shared-nothing 分布式存储层: Storage Service 采用 Shared-nothing 的分布式架构设计,共有三层,最底层是 Store Engine,它是一个单机版 Local Store Engine,提供了对本地数据的 get/put/scan/delete 操作,该层定义了数据操作接口,用户可以根据自己的需求定制开发相关 Local Store Plugin。目前,NebulaGraph 提供了基于 RocksDB 实现的 Store Engine。在 Local Store Engine 之上是 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group。在 Consensus 层上面是 Storage interfaces,这一层定义了一系列和图相关的 API。这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 KV 操作。正是这一层的存在,使得存储服务变成了真正的图存储。否则,Storage Service 只是一个 KV 存储罢了。而 NebulaGraph 没把 KV 作为一个服务单独提出,最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 Schema,而 KV 层没有数据 Schema 概念,这样设计比较容易实现计算下推,是 NebulaGraph 查询性能优越的主要原因。
NebulaGraph 基于 C++ 实现,架构设计支持存储千亿顶点、万亿边,并提供毫秒级别的查询延时。我们在 3 台 48U192G 物理机搭建的集群上灌入 10 亿美食图谱数据对 NebulaGraph 的功能进行了验证。
一跳查询 TP99 延时在 5ms 内,两跳查询 TP99 延时在 20ms 内,一般的多跳查询 TP99 延时在百毫秒内。 集群在线写入速率约为20万 Records/s。 支持通过 Spark 任务离线生成 RocksDB 底层 SST File,直接将数据文件载入到集群中,即类似 HBase BulkLoad 能力。 提供了类 SQL 查询语言,对于新增的业务需求,只需构造 NebulaGraph SQL 语句,易于理解且能满足各类复杂查询要求。 提供联合索引、GEO 索引,可通过实体属性或者关系属性查询实体、关系,或者查询在某个经纬度附近 N 米内的实体。 一个 NebulaGraph 集群中可以创建多个 Space (概念类似 MySQL 的DataBase),并且不同 Space 中的数据在物理上是隔离的。
4 图数据库平台建设

为了统一管理图数据,减少工程同学在图数据库集群上的运维压力,我们基于开源分布式图数据库 NebulaGraph,搭建了一套一站式图数据库自助管理平台(见图 4),该平台包含以下 4 层:
数据应用层。 业务方可以在业务服务中引入图谱 SDK,实时地对图数据进行增删改查。 数据存储层。 支持两种图数据库集群的部署。 第一种部署方式是 CP 方案,即 Consistency & Partition tolerance。单集群部署,集群中机器数量大于等于副本的数量,副本数量大于等于 3 。只要集群中有大于副本数一半的机器存活,整个集群就可以对外正常提供服务。CP 方案保证了数据读写的强一致性,但这种部署方式下集群可用性不高。 第二种部署方式是 AP 方案,即 Availability & Partition tolerance。在一个应用中部署多个图数据库集群,每个集群数据副本数为 1 ,多集群之间进行互备。这种部署方式的好处在于整个应用对外的可用性高,但数据读写的一致性要差些。 数据生产层。 图数据主要有两种来源,第一种是业务方把数仓中数据通过 ETL Job 转成点和边的 Hive 表,然后离线导入到图数据库中;第二种是业务线上实时产生的数据、或者通过 Spark/Flink 等流式处理产生的近线数据,调用在线批量写接口实时灌到图数据库中。 支撑平台。 提供了 Schema 管理、权限管理、数据质检、数据增删改查、集群扩缩容、图谱画像、图数据导出、监控报警、图可视化、集群包管理等功能。
与业界方案相比,团队主导设计的图数据库平台除了支持存储千亿顶点、万亿边,具备毫秒级别查询能力外,还提供了如下四项能力:应用可用性 SLA 达 99.99%;支持每小时百亿量级数据导入;实时写入数据时保证多集群数据最终一致性;易用的图谱可视化能力。下面将介绍具体的设计思路。
4.1 高可用模块设计
首先介绍单应用多集群高可用模块的设计(AP 方案)。为什么有 AP 方案的设计呢?因为接入图数据库平台的业务方比较在意的指标是集群可用性。在线服务对集群的可用性要求非常高,最基础的要求是集群可用性能达到 4 个 9,即一年里集群的不可用时间要小于一个小时。对于在线服务来说,服务或者集群的可用性是整个业务的生命线,如果这点保证不了,即使集群提供的能力再多再丰富,那么业务方也不会考虑使用,可用性是业务选型的基础。
另外,公司要求中间件要有跨区域容灾能力,即要具备在多个地域部署多集群的能力。我们分析了平台接入方的业务需求,大约 80% 的场景是 T+1 全量导入数据、线上只读。在这种场景下,对图数据的读写强一致性要求并不高,因此我们设计了单应用多集群这种部署方案。
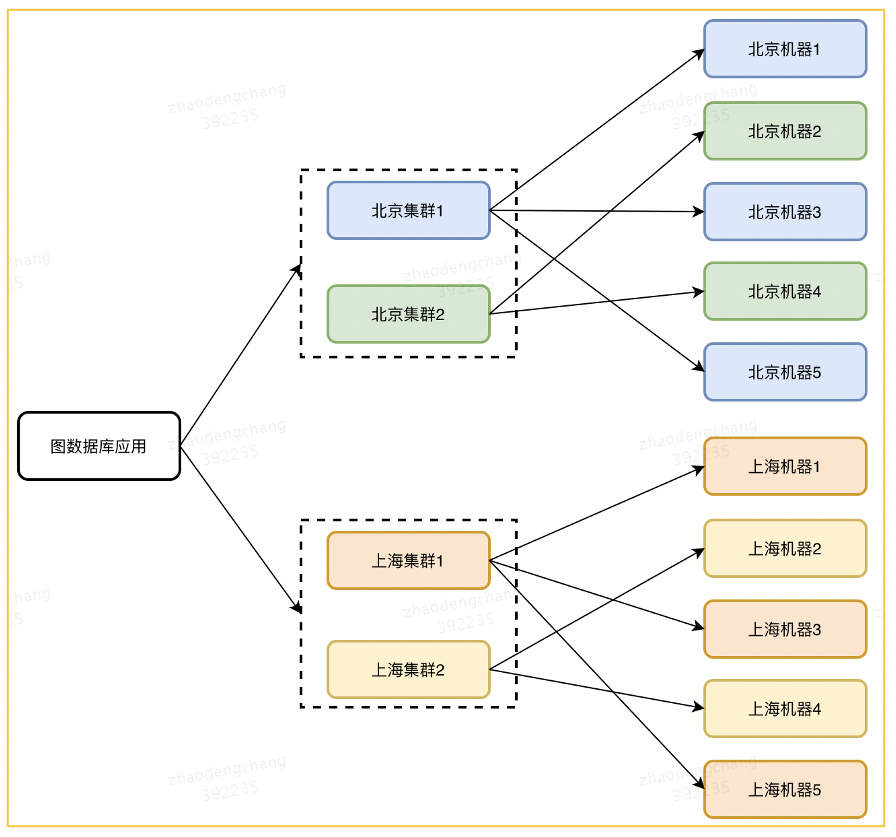
AP 方案部署方式可以参考图 5,一个业务方在图数据库平台上创建了 1 个应用并部署了 4 个集群,其中北京 2 个、上海 2 个,平时这 4 个集群同时对外提供服务。假如现在北京集群 1 挂了,那么北京集群 2 可以提供服务。如果说真那么不巧,北京集群都挂了,或者北京侧对外的网络不可用,那么上海的集群也可以提供服务。在这种部署方式下,平台会尽可能地通过一些方式来保证整个应用的可用性。然后每个集群内部尽量部署同机房的机器,因为图数据库集群内部 RPC 非常多,如果有跨机房或者跨区域的频繁调用,整个集群对外的性能会比较低。
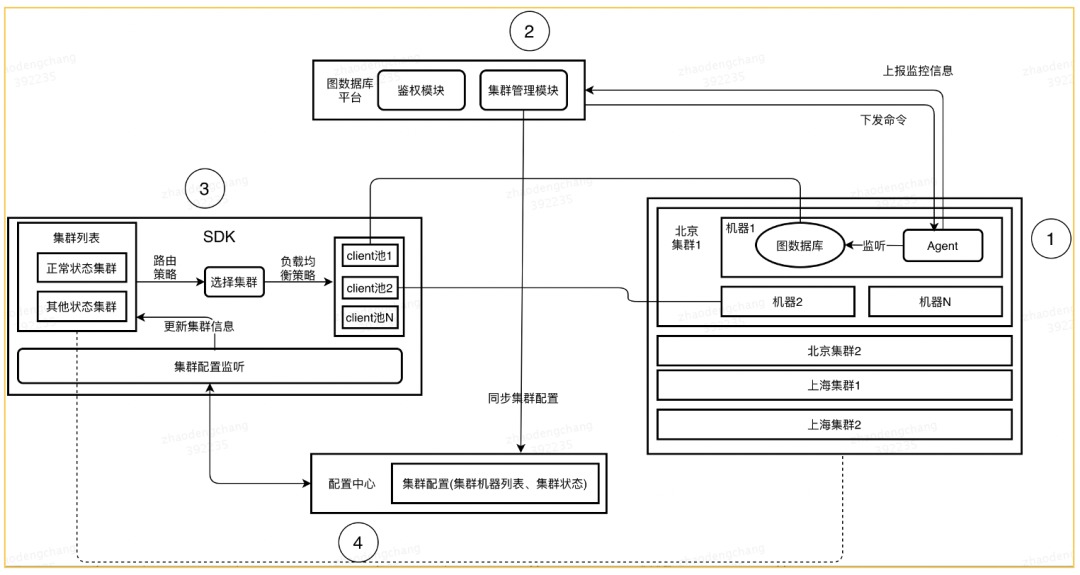
高可用模块主要包含下面 4 个部分,如上图 6 所示:
第一部分是右侧的图数据库 Agent,它是部署在图数据库集群的一个进程,用来收集机器和图数据库三个核心模块的信息,并上报到图数据库平台。Agent 能够接收图数据库平台的命令并对图数据库进行操作。
第二部分是图数据库平台,它主要是对集群进行管理,并同步图数据库集群的状态到配置中心。
第三部分是图数据库 SDK,主要负责管理连接到图数据库集群的连接。如果业务方发送了某个查询请求,SDK 会进行集群的路由和负载均衡,选择出一条高质量的连接来发送请求。此外,SDK 还会处理图数据库集群中问题机器的自动降级以及恢复,并且支持平滑切换集群的数据版本。
第四部分是配置中心,类似 ZooKeeper,存储集群的当前状态。
4.2 每小时百亿量级数据导入模块设计

第二个模块是每小时百亿量级数据导入模块,平台在 2019 年底- 2020 年初全量导入数据的方式是调用 NebulaGraph 对外提供的批量数据导入接口,这种方式的数据写入速率大概是每小时 10 亿级别,导入百亿数据大概要耗费 10 个小时,耗时较长。此外,在以几十万每秒的速度导数据的过程中,会长期占用机器的 CPU、IO 资源,一方面会对机器造成损耗,另一方面数据导入过程中集群对外提供的读性能会变弱。
为了解决上面两个问题,平台进行了如下优化:在 Spark 集群中直接生成图数据库底层文件 SST File,再借助 RocksDB 的 Bulkload 功能直接 ingest 文件到图数据库。
数据导入的核心流程可以参考图 7,当用户执行导数据操作后,图数据库平台会向公司的 Spark 集群提交一个 Spark 任务,在 Spark 任务中会生成图数据库里相关的点、边以及点索引、边索引相关的 SST 文件,并上传到美团的 S3 云存储上。文件生成后,图数据库平台会通知应用中多个集群去下载这些存储文件,之后完成 ingest 跟 compact 操作,最后完成数据版本的切换。
为兼顾各个业务方的不同需求,平台统一了应用导入、集群导入、离线导入、在线导入,以及全量导入、增量导入这些场景,然后细分成下面九个阶段,从流程上保证在导数据过程中应用整体的可用性:SST File 生成 、SST File 下载 、ingest、compact、数据校验、增量回溯、数据版本切换、集群重启、数据预热。
4.3 实时写入多集群数据同步模块设计

第三个模块是实时写入多集群数据同步模块,平台约有 15% 的需求场景是在实时读取数据时,还要把新产生的业务数据实时写入集群,并且对数据的读写强一致性要求不高。就是说,业务方写到图数据库里的数据,不需要立马能读到。针对上述场景,业务方在使用单应用多集群这种部署方案时,多集群里的数据需要保证最终一致性。针对这一需求,我们做了以下设计。
第一部分是引入 Kafka 组件,业务方在服务中通过 SDK 对图数据库进行写操作时,SDK 并不直接写图数据库,而是把写操作写到 Kafka 队列里,之后由该应用下的多个集群异步消费这个 Kafka 队列。
第二部分是集群在应用级别可配置消费并发度,来控制数据写入集群的速度。具体流程如下:
SDK 对用户写操作语句做语法解析,将其中点边的批量操作拆解成单个点边操作,即对写语句做一次改写。 Agent 消费 Kafka 时确保每个点及其出边相关操作在单个线程里顺序执行(见图 8),保证这点就能保证各个集群执行完写操作后最终的结果是一致的。 并发扩展:通过改变 Kafka 分片数、Agent 中消费 Kafka 线程数来调整 Kafka 中操作的消费速度。如果未来图数据库支持事务的话,上面的配置需要调整成单分片单线程消费,有必要对设计方案再做优化调整。
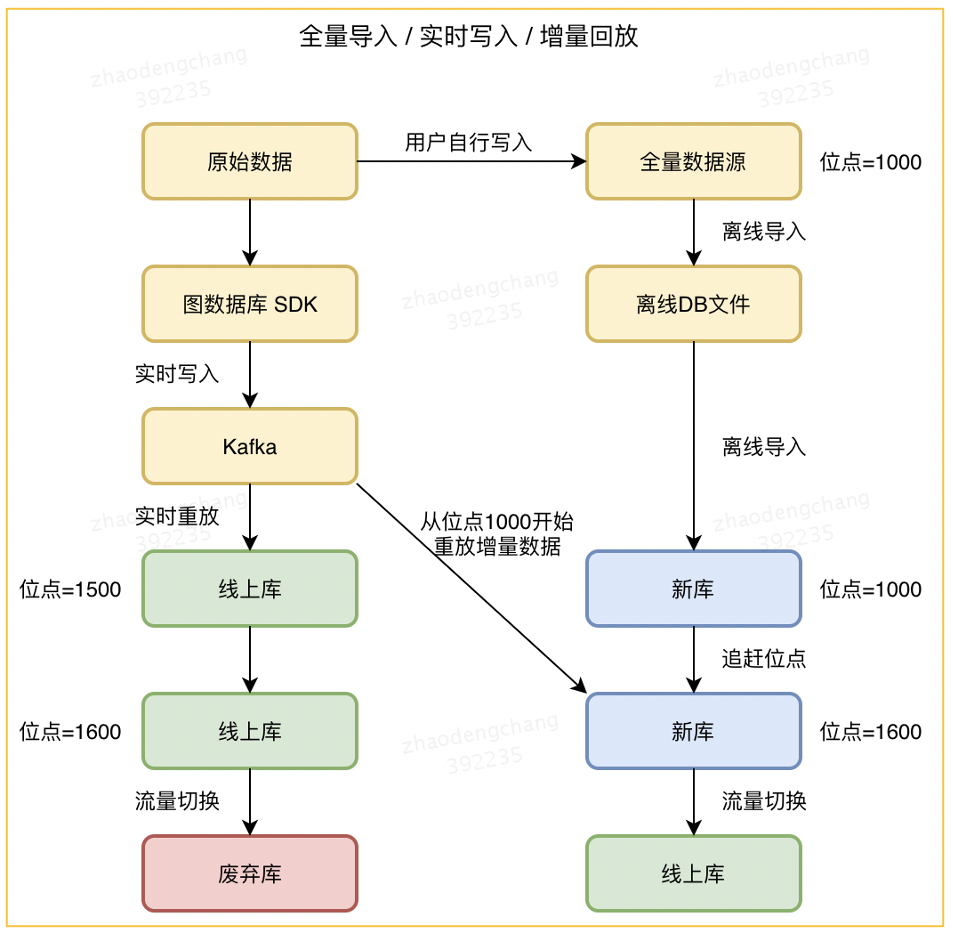
第三部分是在实时写入数据过程中,平台可以同步生成一个全量数据版本,并做平滑切换(见图 9),确保数据的不重、不漏、不延迟。
4.4 图可视化模块设计

第四个模块是图可视化模块(见图10),主要是用于解决子图探索问题。当用户在图数据库平台通过可视化组件查看图数据时,能尽量通过恰当的交互设计来避免因为节点过多而引发爆屏。主要包括以下几个功能:
通过 ID 或者索引查找顶点。 能查看顶点和边的卡片(卡片中展示点边属性和属性值),可以单选、多选、框选以及按类型选择顶点。 图探索,当用户点击某个顶点时,系统会展示它的一跳邻居信息,包括该顶点有哪些出边?通过这个边它能关联到几个点?该顶点的入边又是什么情况?通过这种一跳信息的展示,用户在平台上探索子图的时候,可快速了解到周边的邻居信息,更快地进行子图探索。在探索过程中,平台也支持通过属性对边进行过滤。 图编辑能力,让平台用户在不熟悉 NebulaGraph 语法的情况下也能增删改点边数据,对线上数据进行临时干预。
5 业务实践
5.1 智能助理
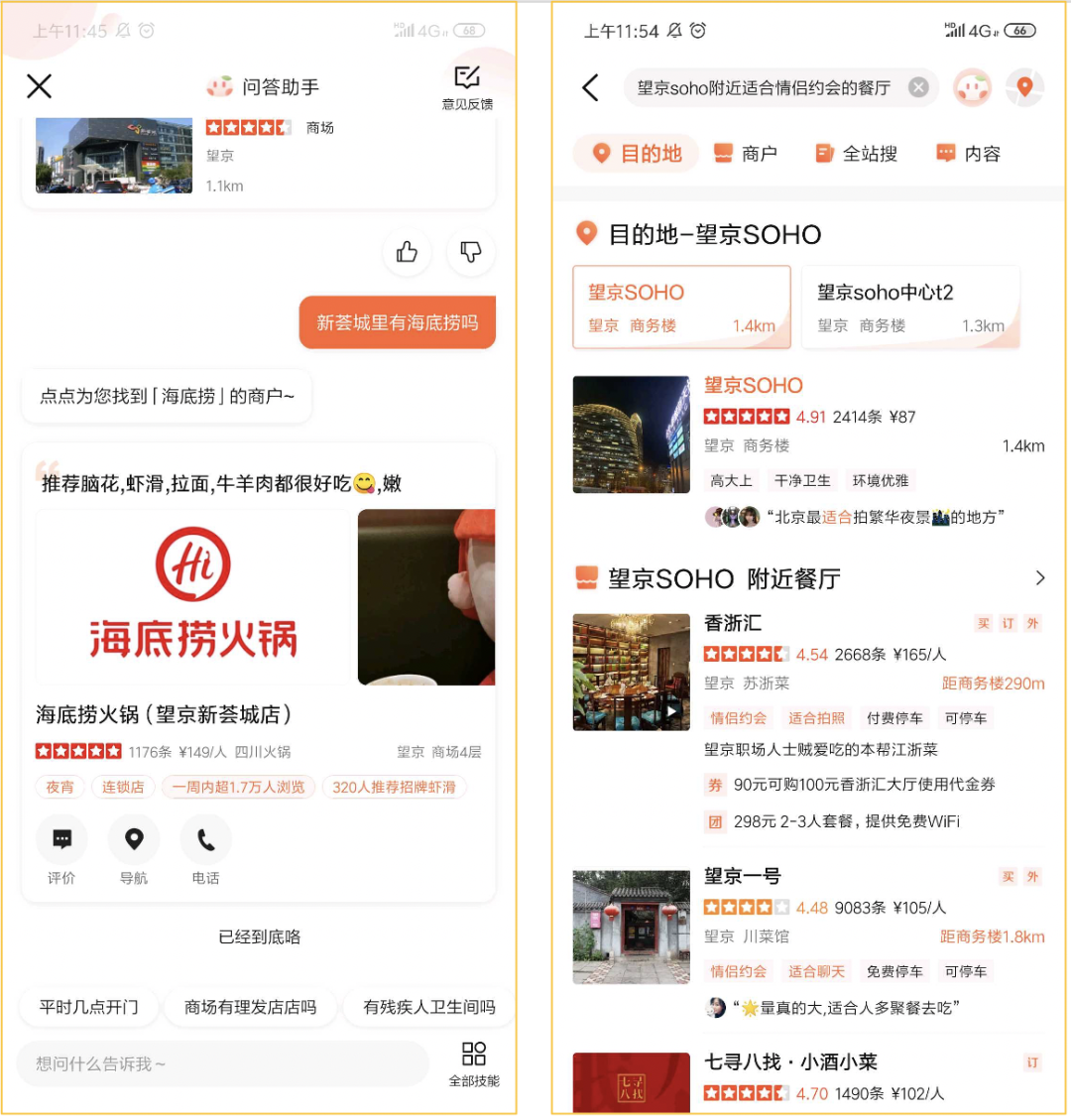
该项目数据是基于美团商户数据、用户评论构建的餐饮娱乐知识图谱,覆盖美食、酒店、旅游等领域,包含 13 类实体和 22 类关系。目前,点边数量大概在百亿级别,数据 T+1 全量更新,主要用于解决搜索或者智能助理里 KBQA(全称:Knowledge Based Question Answer)类问题。核心处理流程是通过 NLP 算法识别关系和实体后构造出 NebulaGraph SQL 语句,再到图数据库获取数据。
典型的应用场景包括商场找店,比如,某个用户想知道望京新荟城这个商场有没有海底捞,系统可以快速查出结果告诉用户;另一个场景是标签找店,用户想知道望京 SOHO 附近有没有适合情侣约会的餐厅,或者可以多加几个场景标签,系统都可以帮忙查找出来。
5.2 搜索召回
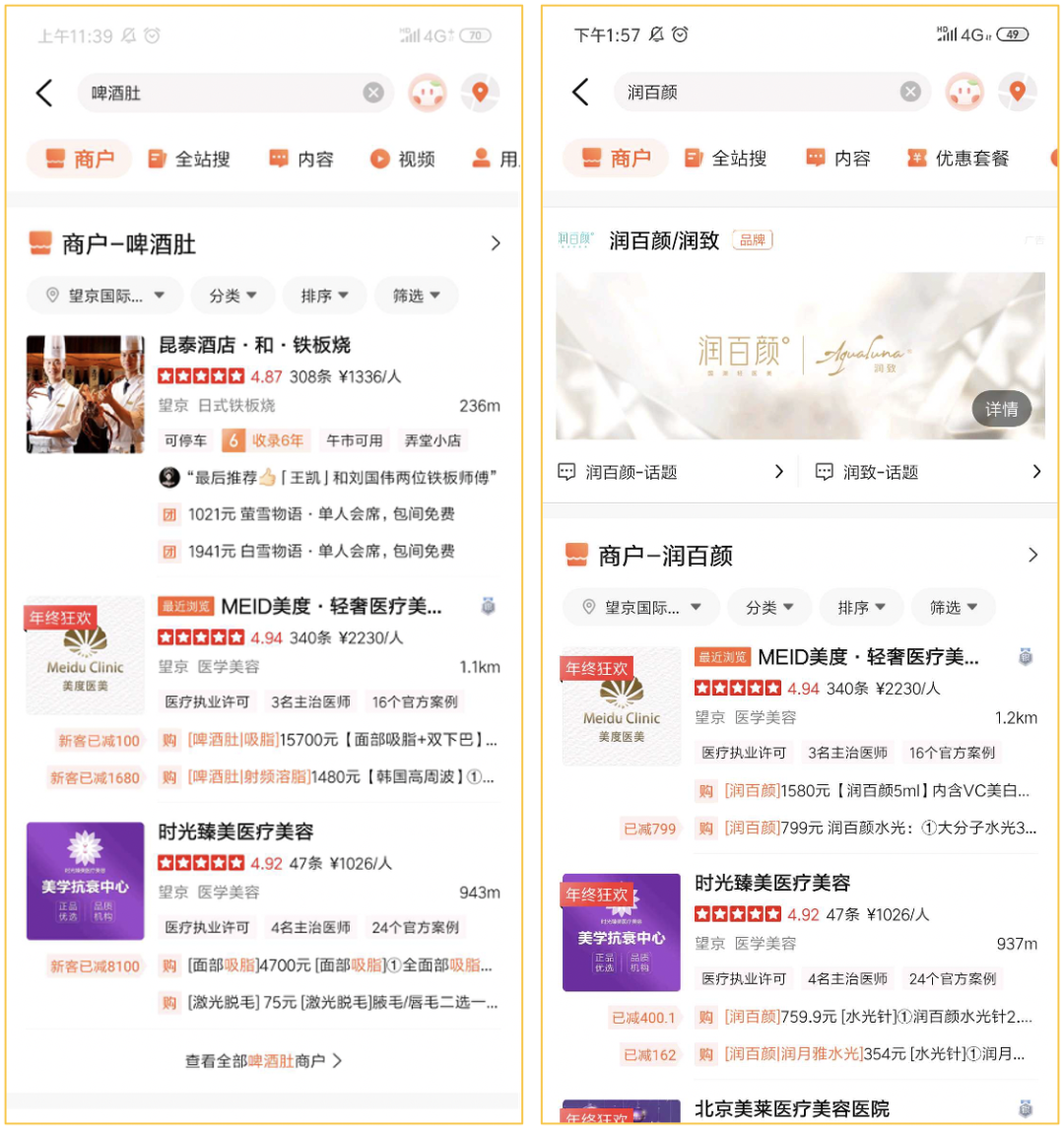
该项目数据是基于医美商家信息构建的医美知识图谱,包含 9 类实体和 13 类关系,点边数量在百万级别,同样也是 T+1 全量更新,主要用于大搜底层实时召回,返回与 Query 相关的商户、产品或医生信息,解决医美类搜索词少结果、无结果问题。比如,某个用户搜“啤酒肚”这种症状、或者“润百颜”这类品牌,系统可以召回相关的医美门店。
5.3 图谱推荐理由

该项目数据来自用户的画像信息、商户的特征信息、用户半年内收藏/购买行为,数据量级是 10 亿级别,T+1 全量更新。现在美团 App 和点评 App 上默认的商户推荐列表是由深度学习模型生成的,但模型并不会给出生成这个列表的理由,缺少可解释性。
而在图谱里用户跟商户之间天然存在多条连通路径,项目考虑选出一条合适路径来生成推荐理由,在 App 界面上展示给用户推荐某家店的原因。该项目基于用户的协同过滤算法来生成推荐理由,在家乡、消费水平、偏好类目、偏好菜系等多个组合维度中找出多条路径,然后给这些路径打分,选出一条分值较高的路径,之后按照特定 Pattern 产出推荐理由。通过上述方式,就可以获得“在北京喜欢北京菜的山东老乡都说这家店很赞”,或者“广州老乡都中意他家的正宗北京炸酱面”这类理由。
5.4 代码依赖分析
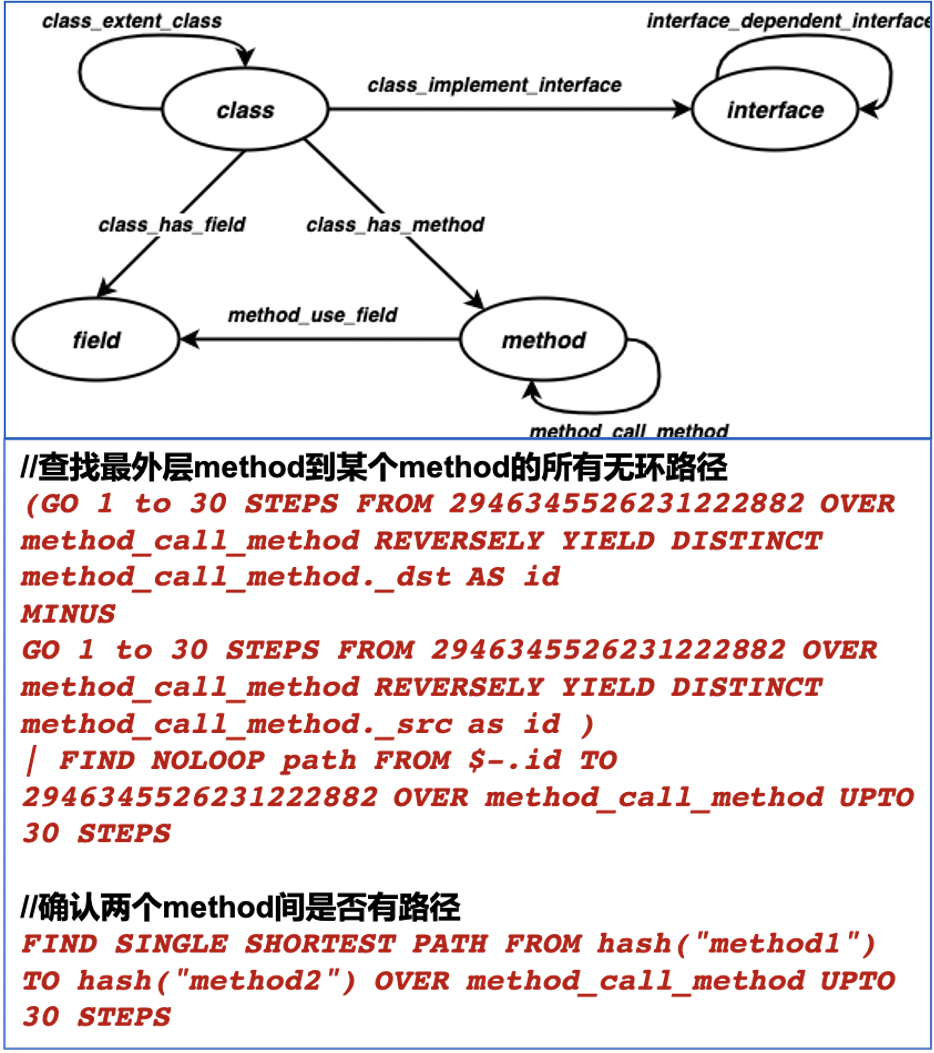
该项目把代码库中代码依赖关系写入到图数据库。代码库中存在很多服务代码,这些服务会包括对外提供的接口,这些接口的实现依赖于该服务中某些类的成员函数,这些类的成员函数又依赖了本类的成员变量、成员函数或者其它类的成员函数,那么它们之间的依赖关系就形成了一张图,可以把这个图写到图数据库里做代码依赖分析。
典型应用场景是精准测试:当开发同学完成需求并向公司的代码仓库提交了 PR 后,可以把更改实时地写到图数据库中。这样的话,开发同学就能查到他所写的代码影响了哪些外部接口,并且借助图可视化组件查看调用路径。如果开发同学本来是要改接口 A 的行为,改了很多代码,但是他可能并不知道他改的代码也会影响到对外接口 B、C、D,这时候就可以用代码依赖分析来做个 Check,增加测试的完备性。
6 总结与展望
目前,图数据库平台基本具备了对图数据的一站式自助管理功能。如果某个业务方要使用这种图数据库能力,那么业务方可以在平台上自助地创建图数据库集群、创建图的 Schema、导入图数据、配置导入数据的执行计划、引入平台提供的 SDK 对数据进行操作等等。平台侧主要负责各业务方图数据库集群的稳定性。目前,美团有三四十个业务已经在该平台上落地,基本满足了各个业务方的需求。
未来规划主要有两个方向,第一,根据业务场景优化图数据库内核,提升平台稳定性,开发的通用 Feature 持续反哺 NebulaGraph 社区。第二,挖掘更多的图数据价值。现在平台仅支持图数据存储及多跳查询这种基本能力,后续将基于 NebulaGraph 去探索图学习、图计算的能力,为平台用户提供更多挖掘图数据价值的功能。
7 作者信息
登昌、梁帅、高辰、杨鑫、尊远、王超等,均为美团搜索与NLP部工程师。